はじめに
A2C (Advantage Actor Critic) は A3Cのバリアントであり、A3Cから非同期 (Asynchronous) 要素を除いた手法です。
A3Cはいろいろ盛り込んでて属性過多な手法だったので、手法の発表後にそれぞれの要素が性能にどの程度の寄与があったのかが検証されました。
結果、各Agentによるネットワークの非同期更新ではなく、各Agentから受け取ったトラジェクトリによりネットワークをまとめて更新する同期更新実装でもパフォーマンスが落ちないことが発見されました。それなら実装が楽だし1台のGPUを効果的に利用できるしこっちの方がいいね、となったのがA2Cです。
名前だけ聞くとA2Cの方が先に発表されたように思えるので私は当初混乱しました。
詳細は OpenAI Baselines: ACKTR & A2C を参照
BreakoutDeterministic-v4 with A2C
— めんだこ (@horromary) 2020年5月19日
裏回しに成功した後呆然として固まるagentくん
#ReinforcementLearning pic.twitter.com/jx7RZUr5Co
同期更新をどのライブラリで実装するか
ですので焦点はプロセス間の同期更新をどう実装するか、もっと言うとどのライブラリでプロセス並列化するかです。
本記事ではmultiprocessingライブラリでmulti-agentによる同期更新を実装しますが、もしマルチノードで学習させたいならRayが良いでしょう。
【更新2020年12月: rayでの実装例を公開しました】
A2Cの実装
コード全体はgituhubに置いています。
A3Cでは各agentがローカルネットワークを持ち自律的にゲームプレイを行っていましたが、A2Cでは各agentはmaster agent (Brain、あるいは中央指令室) による指示に従って動きます。
具体的には各agentは現在の状態をmaster agentに提示し、master agentは提示された状態から次のアクションを判断しagentにアクション指示を与えます。
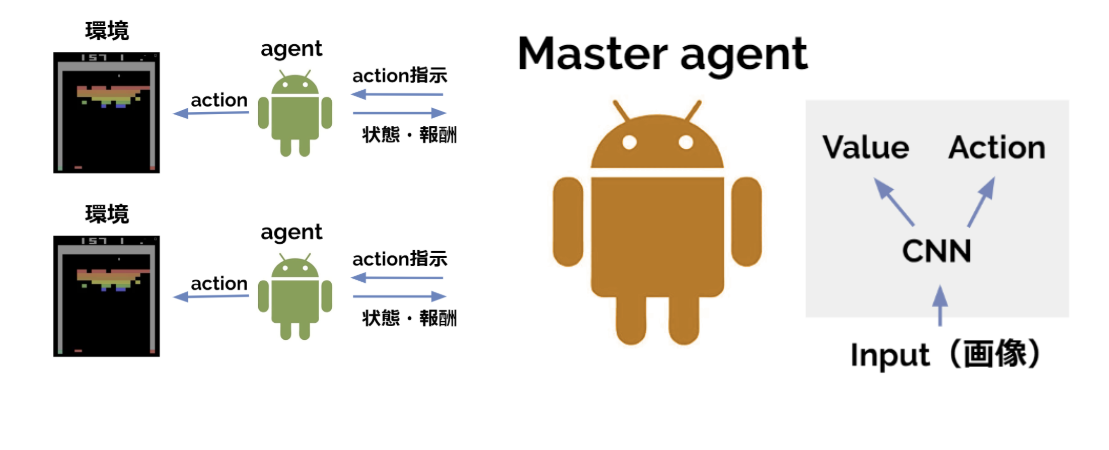
Master Agent (Brain)
MsterAgentの役割は①各agentにアクション指示を出して遷移後の状態を受け取る、①を5step繰り返したらネットワークをアップデートする、というだけなのでシンプルに書けます。
Multi-agent環境
このコードはopenai-baselinesのmultiprocessingによるマルチエージェント実装をシンプルにしたものです。
baselines/subproc_vec_env.py at master · openai/baselines · GitHub
multiprocessing.PipeがMasterAgentと各環境への通信手段となります。
Pipe()は2つのコネクションオブジェクトを生成しますがこれは糸電話の両端のようなものと理解しましょう。片端をworker_funcに渡し、もう片端はSubprocVecEnvが保持するようにします。
たとえばMaster Agent がSubProcVecEnv(N並列設定)に対してN個のアクション指示を出すと、SubProcVecEnvが各Agent(worker_func)にaction指示を与えます。SubProcVecEnvは各Agentのアクション実行結果を集約してMaster Agentに返します。
Actor Critic Network
ネットワーク構造は最後にvalueとpolicyに分かれる以外はNature DQNと同じです。
学習結果
CPUのみ15並列で20時間ほどの結果です。かなり安定して学習が進んでいます。

※スコアは定期的(15000ステップごと)に行ったテストプレイ5episodeの平均スコアです。
DQNに比べてメモリ消費も少ないのでそこそこスペックのノートPCでも学習できます。爆熱になるからやらないけど。