PPOをTensorflow2で実装しBipedalWalker-v3を攻略します。手法解説は①を参照ください。
[PPOシリーズ]
【強化学習】ハムスターでもわかるProximal Policy Optimization (PPO)①基本編 - どこから見てもメンダコ
ハムスターでもわかるProximal Policy Optimization (PPO)②TF2による実装 - どこから見てもメンダコ

PPO論文: [1707.06347] Proximal Policy Optimization Algorithms
コード全文はgithubへ:
1. Surrogate Objective Clipping による方策更新
PPOのコアアリゴリズムであるSurrogate objective clipping (代理目的関数クリッピング) で方策を更新する場合、方策関数と価値関数がパラメータを共有するA2C型モデル か 方策関数と価値関数を別に定義するTRPO(というか普通のActor-Critic)型モデルのどちらを採用するかで更新式が異なります。前者は離散値コントロールのaratiドメインで、後者は連続値コントロールのmujokoドメインで良好な性能を発揮することが論文中で示されています。
今回は連続値コントロールタスクであるBipedalWalker-v3をターゲットとするので、コードはパラメータ共有をしないTRPO型のモデル、すなわち典型的なActor-Criticモデルの場合のみを示します。
パラメータを共有するA2C型モデルの場合
方策ネットワークと価値ネットワークがパラメータを共有するA2C/A3C型のモデルでは”ロス関数=方策勾配ロス+価値ロス+方策エントロピーボーナス” としてパラメータ更新します。この方策勾配ロスをSurrogate objective clipping に置き換えるだけでPPOとなります。したがってA2C/A3Cの実装をわずかに変更するだけで実装完了です。この実装はAtari環境での良好なパフォーマンスからA2Cの改良手法と位置付けることができます。
【強化学習】A3CでCartPole【TF2】 - どこから見てもメンダコ
パラメータを共有しないTRPO型モデルの場合
一方でPPOをTRPOの改良手法として位置付ける場合は、価値関数と方策関数を別に定義する典型的なActor-Criticモデルを実装します。
この場合、tensorflow2での方策関数の更新コードは以下のようになります。
tensorflow2系のtf.GradientTapeではwithコンテクスト内での計算のみ勾配が流れます。この仕様はPPOと大変相性が良く、上のようなシンプルな実装が可能になります。advantagesとold_logprobをtf.GradientTapeの外で計算しておくのがポイント。
また、収集したサンプル群から2048step分をランダムサンプリングし、ポリシーを更新することを20回繰り返すという、 オンポリシー強化学習なのにオフポリシー強化学習のような一見違和感のある実装をしています。
これは重点サンプリング(Importance Sampling)という関心のある分布とは異なる分布から生成されたサンプルから別の分布の特性を推定する計算トリックが可能にしている実装なのですが説明すると長いのでTRPOの過去記事をご覧ください。
更新を20回でなく100回あるいは200回繰り返したとしても、clippingはold_policyを参照するためポリシーの過学習を回避できるというのも重要なポイントです。
2. Advantage(GAE)の計算
advantageの計算にはさまざまな方法がありますがPPOではGeneralized Advantage Estimation (GAE) で実装することが論文内で明言されています。
[1506.02438] High-Dimensional Continuous Control Using Generalized Advantage Estimation
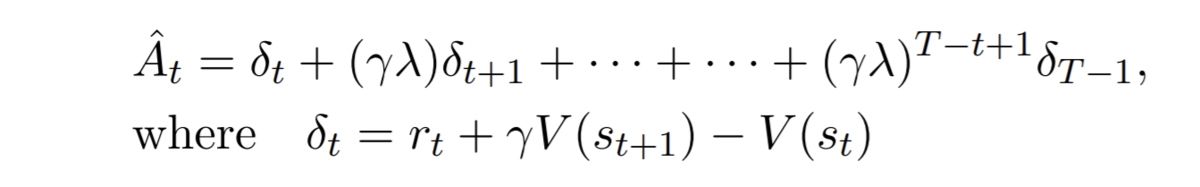
なんでこの式になるかの説明も長いので省略しますが、とりあえず実装すると下のようになります。
rewardを過去のrewardから算出した標準偏差で割ることによりスケーリングしていることに注意してください。報酬のスケーリングは連続値環境においては強い学習安定化効果があることが知られています。
※running_statsの算出はbaselinesのコードを転用しています。
baselines/running_mean_std.py at master · openai/baselines · GitHub
ただし、今回のターゲットであるBipedalWalker-v3は通常時の報酬が-1から1程度なのに対して転倒時が-100という非常に大きな負報酬が設定されておりrunning_statsを狂わせます。そこで、転倒時報酬は-1に変更しています(後述のwokerクラスを参照)。
3. 非同期/同期並列化
PPO論文ではトラジェクトリの収集で並列化agentを使用することが明言されています。
強化学習におけるAgentの並列化では、A3Cのような分散非同期並列化とA2Cの同期並列化のどちらかがよく採用されます。GPUが一つしかない場合には後者の同期並列化の方が効率がよいので、今回はbaselinesのSubprocVecEnv( baselines/subproc_vec_env.py at master · openai/baselines · GitHub
)をベースに、pythonの分散並列処理ライブラリであるRayで再実装しました。
※ちなみにbaselinesのppo1は非同期並列、ppo2は同期並列実装です。
rayを使うことで並列化をとてもシンプルに記述することができました。
この同期並列環境は以下のように動かします。
学習実行と結果
ここまででPPOに必要な要素はすべて揃いました。さっそくBipedalWalker-v3をターゲットに学習を開始します。
コード全文: RL_TF2/PPO/Bipedalwaker-v3 at master · horoiwa/RL_TF2 · GitHub
Bipedalwalker-v3 solved with Proximal Policy Optimization (PPO)
— めんだこ (@horromary) 2020年10月18日
[Tips] -100 penalty on falling causes instable leaning#ReinforcementLearning pic.twitter.com/aopRIq1Iya
ポリシーの標準偏差は固定値かつ大きめで実装したところ、コケやすいドジっ子walkerになってしまいました。

しかし、trajectoryの総報酬(=1000stepごとの報酬和)で見ると単調増加しておりPPOがうまく実装できていることがわかります。
