連続値制御で大人気の強化学習手法であるSoft-Aactor-Criticのtensorflow2実装を解説します。
対象タスクはPendulum-v0とBipedalWalker-v3。

SAC論文 ②: [1812.05905] Soft Actor-Critic Algorithms and Applications
SAC論文 ③: https://arxiv.org/pdf/1812.11103.pdf
前提手法:DDPG, DQN
ここまでの概要
SAC(Soft Actor Critic)はSoft-Q学習のactor-criticへの適用であり、累積報酬和と同時に方策エントロピーの期待値の最大化を目的関数としてます。
SACの理論的根拠となっているSoft-Q学習は最大エントロピー強化学習に基づくQ学習であり、Q学習の課題である探索力の弱さを方策エントロピー項を目的関数に組み込むことによって解決する自然なアプローチです。また、SAC(およびSoft Q学習)はオフポリシー強化学習手法であり高いサンプル効率が期待できます。
SACの実装はDDPGおよびその改良であるTD3に非常によく似ていますが、Soft-Q学習に由来する探索力の高さから致命的なハイパーパラメータが少なく安定したパフォーマンスを期待できます。
【TF2】DDPGでPendulum-v0【強化学習】 - どこから見てもメンダコ
【強化学習】TD3の解説・実装【TF2】 - どこから見てもメンダコ
全体的なアルゴリズムの流れはDDPGとほぼ同じであり、環境から得た経験をReplayBufferに蓄積しそこからミニバッチを作成してネットワークの更新を行うというループを繰り返します。DDPGと同様にSACは方策とQについてニューラルネットワークによる関数近似を行いますが、状態に基づくアクションの決定は方策関数が担いQ関数は方策関数の更新のためにだけ使用されます。
Soft-Q関数について
SACはsoft-Q関数をニューラルネットワークによって関数近似します。連続値制御のために、QはDQNスタイルではなくDDPGスタイルの実装になります。すなわち、状態Sと行動Aを入力とし、単一のQ値を出力するように実装します。これに対してDQNスタイルのQは状態Sを入力とし、行動Aの次元数分のQを出力します。

soft-Q関数の更新
Soft-Q学習におけるベルマン方程式通りに更新していけばOKです。
通常のQ学習における価値関数Vが、
であるのに対して、
Soft-Q学習における価値関数Vは
というように状態に方策エントロピーがボーナスとして付加されています。
Soft-Q学習における更新式(ベルマンエラー)
※a'は実際に行ったアクションではなく毎回の更新時に方策関数からサンプリングして決める
さらに、この更新式にTD3で提案されたClipped-Double-Qトリックを適用します。Clipped-Double-QとはQ学習のmax演算子(soft-Q学習ではsoftmax)に由来するQ値の過大評価を軽減するための手法であり、Double Q learning (https://arxiv.org/pdf/1509.06461.pdf) と同様のコンセプトの手法です。具体的には2つのQ関数を用意して小さい方の評価値を採用することでQ値の過大評価を打ち消します。
Soft-Q学習における更新式 with Clipped-double-Q
※a'は実際に行ったアクションではなく毎回の更新時に方策関数からサンプリングして決める
プログラミング的にはClipped-Double-Qトリックのために実際に2つのQ関数インスタンスを作ってもよいのですが、コードをすっきりさせるためひとつのQ関数インスタンス内に(self.dualqnet)2つのq関数を内包させることにしました。
2つのq関数を内包するQ関数はtensorflow2で下記のように実装しました。レイヤー構成などはDDPG論文に準拠しています。
ソフトターゲット更新
※Soft-Q学習の”ソフト”とソフトターゲット更新の”ソフト”はとくに関係ありません
Target Networkは、DQN(2013)で提案されて以降、Q学習では標準的に使用される学習安定化のためのテクニックです。
DQNでは10000stepごとくらいの頻度でtarget Q関数とメインQ関数の重みを同期していましたが、この同期頻度の程度がそれなりに重要なハイパーパラメータになってしまっていました。これに対して、DDPGでは1-8step程度の高頻度で少しずつ重みを同期していくことによりtarget Q関数がメインQ関数をゆるやかに後追いするようにさせるSotf-Targetという手法を提案しました。SACでもこのSoft-Targetを使用します。

Deep Deterministic Policy Gradient — Spinning Up documentation
Q関数をtensorflow.keras.Modelで作成しておけばget_weightsおよびset_weightsが使えるので実装上とくに難しいことはありません。
方策関数について
確率的方策は任意の形式が使用可能ですが、論文で単ガウス方策が使用されているのでこれに倣います。SAC論文の初期versionでは混合ガウス分布を使っていましたがmujuco環境では単ガウスでも混合ガウスでもあまりパフォーマンスに影響が無いようです。
https://openreview.net/pdf?id=HJjvxl-Cb
方策関数の更新
前記事(Soft-Actor-Critic (SAC) ①Soft-Q学習からSACへ - どこから見てもメンダコ)では、 方策関数はsoft-Q関数のSoftmax方策に似せていく、つまりKL距離を最小化することにより最適方策が得られるということを解説しました。
これを数式で表現するとSAC論文③ https://arxiv.org/pdf/1812.11103.pdfより
方策関数の更新:Qのsoftmax方策に似せる
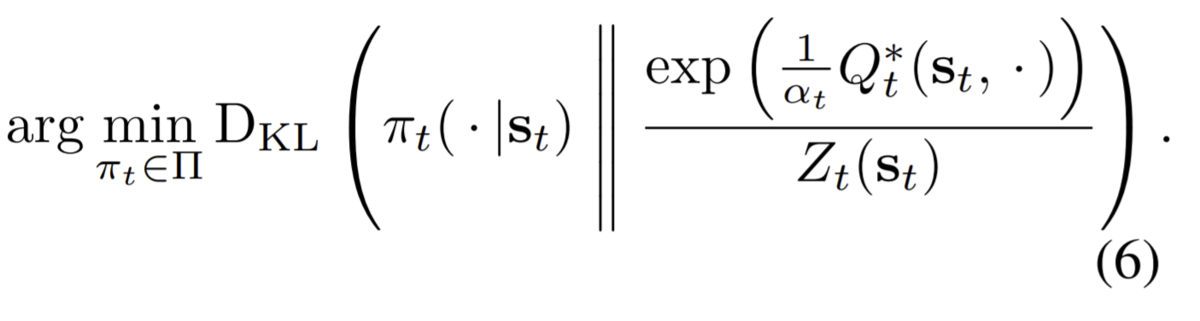
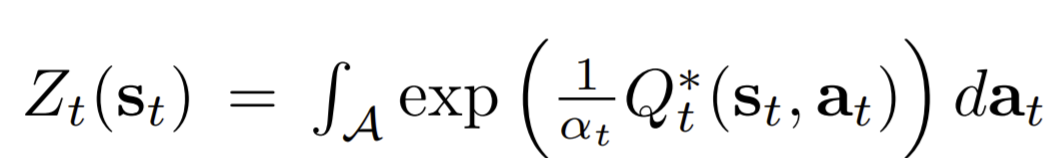
この数式は一見難しそうに思えますが、式を書き下していくとそうでもないことがわかります。
について、まずはKL距離の定義通りに式変形して、
ここで、 がxの確率密度関数であるとき、
であることから、
とすっきり変形できました。
よって、
ここで、Z(s)はπに依存しない規格化定数((softmax方策の規格化定数、統計力学で言えば分配関数)) なのでの中では無視できます。温度パラメータαもまたπに依存しない正の定数なので-αを掛けることで式を整理しつつ、最小化問題を最大化問題に変換します。
というわけで結局のところ、Q値を最大化しつつ方策エントロピー を最大化するというSoft-Q学習の定義通りの式が出てきました。更新式が単純なので実装も簡単です。
方策関数の実装
モデル構造自体はなんの変哲もないガウス方策ですが、状態sからの行動aのサンプリングにおいて”Reparameterization Trick” と "Squashed Gaussian Policy"という2つのテクニックが用いられています。
Reparameterization trick
上述の方策関数の更新を見れば明らかなように、SACでは方策ロスの計算において
- 状態sをガウス方策関数に与えてアクション分布の平均(μ)と標準偏差(σ)を得る
- 正規分布 N(μ、σ)からのサンプリングにより確率的にアクションaを決定する。
- 決定したアクションaと状態sをQ関数に与えてQ(s, a)を計算する
という処理があります。確率的な処理が誤差逆伝搬の通り道にいるとそこで自動微分が止まってしまうため、方策関数の重みを更新できません。*1
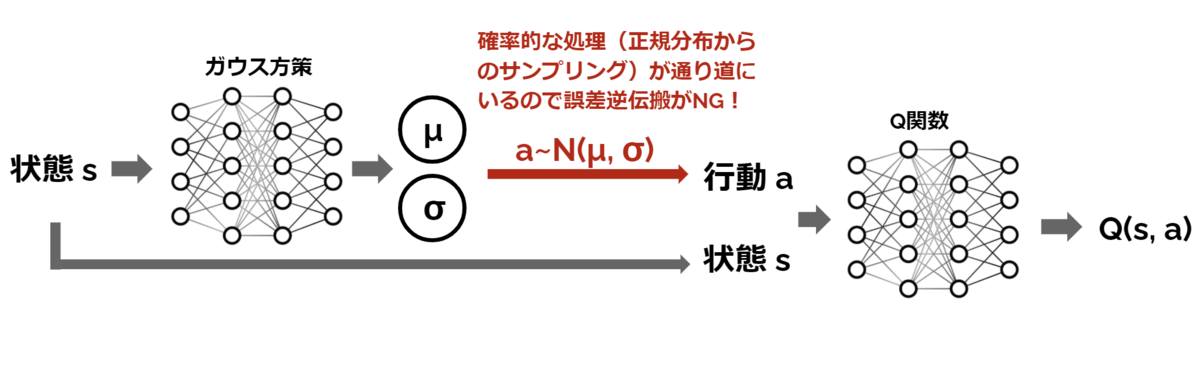
この問題はVAE(Variational Auto Encoder)なんかでもお馴染みの Reparameterization Trick を使用することで解決します。 と言ってもやるべきことは簡単で、確率的処理を誤差逆伝搬の通り道から追い出すだけです。
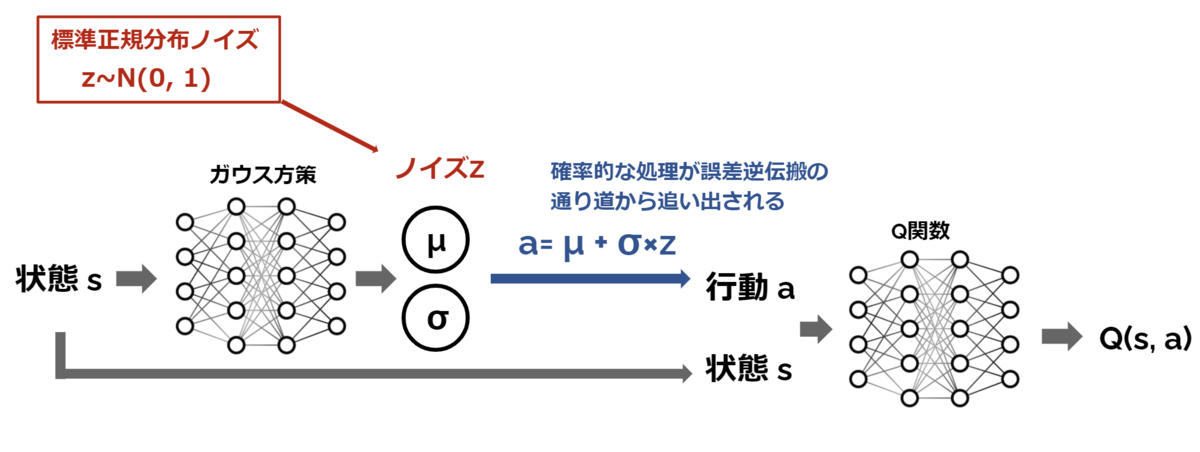
N(μ, σ) からのサンプリングと μ+σz (zは標準正規分布からサンプリングしたノイズ)は同じ結果になりますので確率的処理を通り道から追い出すことができます。いちおう実験しておきましょう。
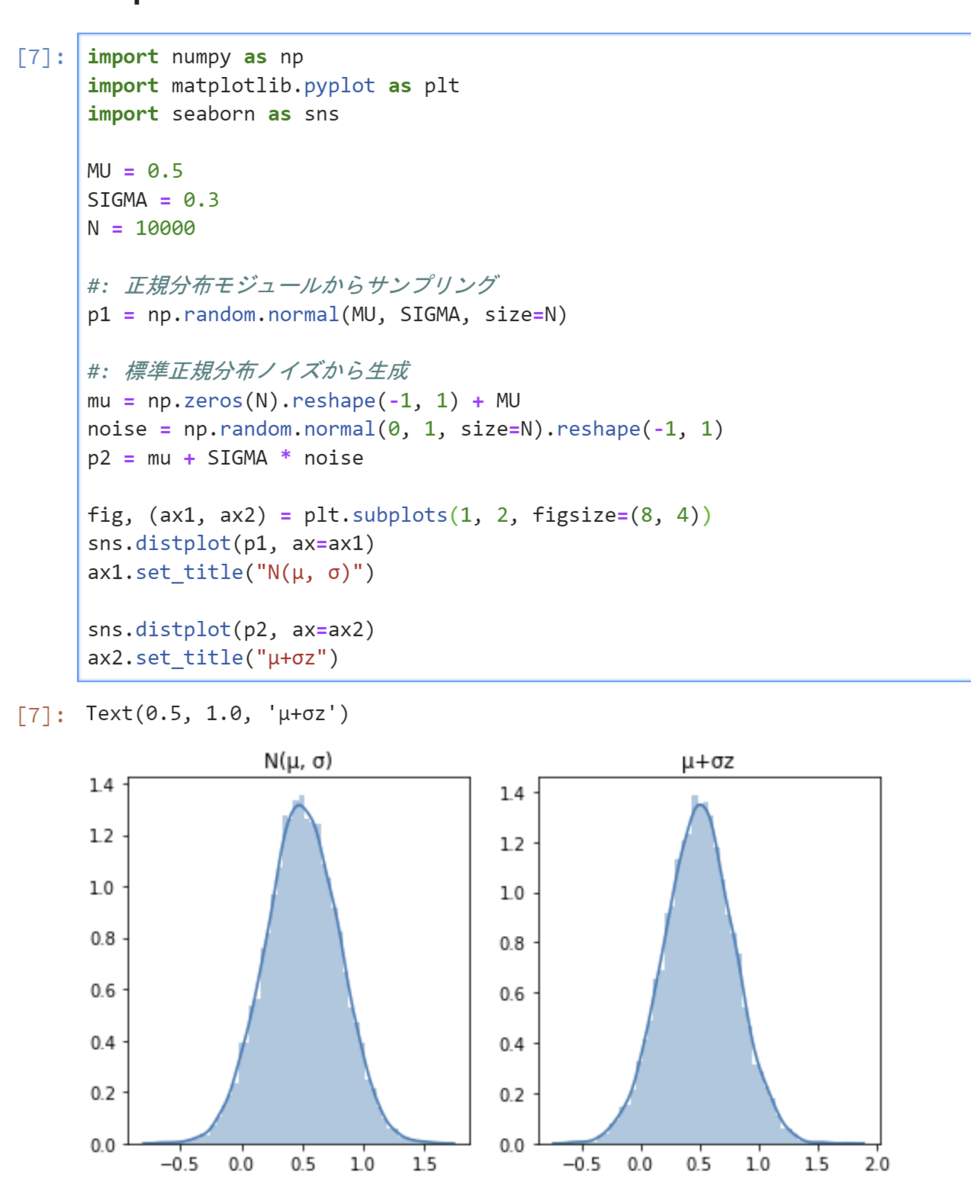
Squashed Gaussian Policy
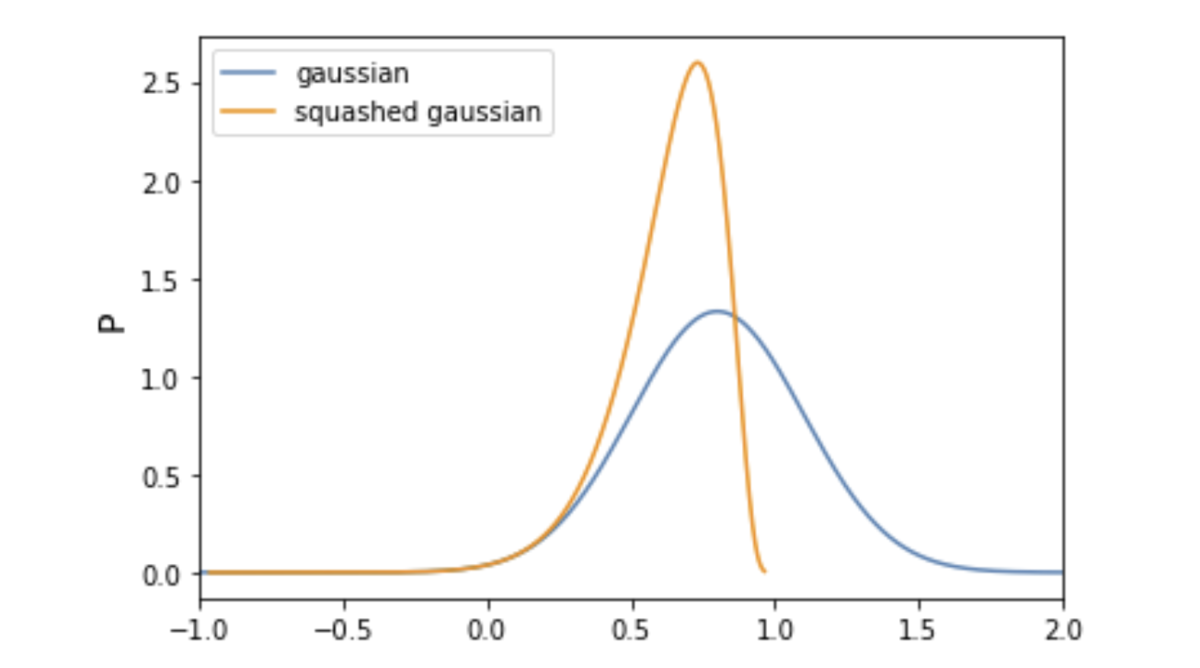
ガウス分布は-∞から∞まであらゆる値をとりうる分布である一方で、たとえば今回のターゲットであるBipedalWalker-v3ではアクションの値を-1から1の範囲に制限する必要があります*2。このような場合にはガウス方策からサンプリングされたアクションにtanhを適用することで-1から1に出力されるアクションの数値範囲を制限することができます。
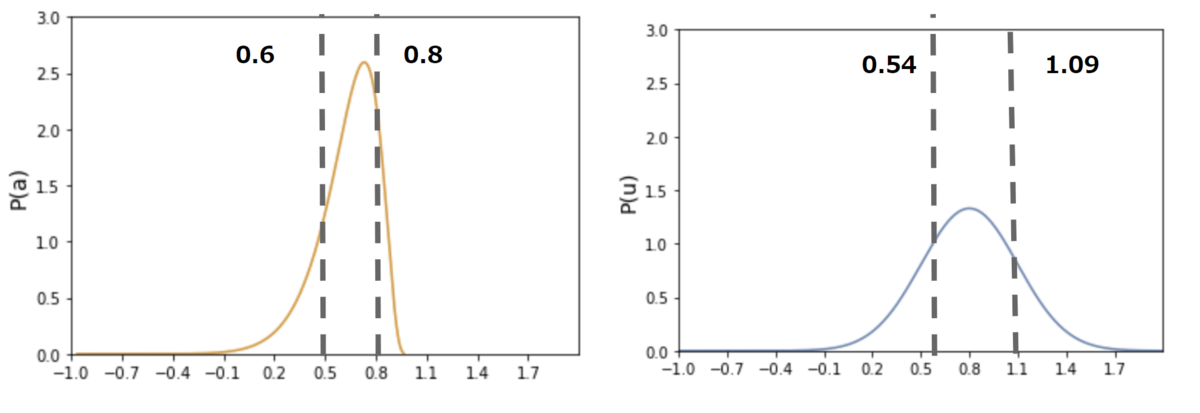
平均0.8, 標準偏差0.3のガウス分布からサンプリングされた値へtanh関数を適用したのが下図です。まさにガウス分布が-1から1の範囲に押しつぶされた(Squashed)ような分布になっていることがわかります。*3
通常のガウス鵜方策の場合には、ロスの計算に必要なはガウス分布の確率密度関数をそのまま使用すればよいですが、tanhによるガウス分布の押し潰しを行った場合
は下記のように計算します。

数学強い人なら上の式みただけで理解できるのかもしれませんが私の数学力はハムスターレベルなので困惑しました。
まず、ガウス分布はtanhで押しつぶされただけなので*4、破線区間での積分が等しくなるということが直感的にイメージできるでしょうか。
これを数式で表現すると、tanhを適用されたガウス分布の確率密度関数を、 ガウス分布の確率密度関数を
として
ここまでイメージできればあとは下記の参考リンクを見れば大丈夫(丸投げ)。
sinhx, coshx, tanhxの逆関数 | 高校数学の美しい物語
温度パラメータαの自動調整
SAC(というかSoft-Q学習)の目的関数では累積報酬和と方策エントロピーの期待値の最大化という多目的最適化問題を、単純な和をとることで一つの式にまとめ単目的最適化問題のように表現しています。しかし、Q値およびエントロピーのスケール感はタスクおよび学習の進み具合によって変わるため、エントロピー項の係数αを適切に設定することによって累積報酬和と方策エントロピーのバランスをとる必要があります。
※αは論文では温度(temperature)パラメータと表現されています。これはSoft-Q学習における最適方策が統計力学におけるボルツマン分布と同じ形であり、αはボルツマン分布における温度Tに対応するためです。
最初のSAC論文ではこの係数αはハイパーパラメータとして調整されるべき値とされましたが、SAC論文② では係数αの自動調整手法が提案されています。具体的には下式に示すように、エントロピー下限値の制約付き報酬累積和の最大化問題と捉えることで適切なαを決定します。

この双対問題を解くことによりαの更新式が得られます。しかし、真面目に最小化問題を解くのはpracticalでないので実際は右辺のEの中身をlossとしてSGDでαを更新していきます

実装はこんな感じ。tf.Variableを直接定義してSGDって案外やる機会がないのでちょっと焦る。
直感的にはエントロピーが目標値Hより小さくなったらαを大きくし、逆に目標値Hより大きくなったらαを小さくして、というように適応的にαを更新していくと理解することができます。ただしエントロピーの目標値Hはやはりハイパーパラメータであり、"-1×アクションの次元数" が推奨値として提案されているものの、とくに理論的根拠があるわけではないのである程度ハイパラチューニングした方がよいと思われます。
結果
コード全文はgithubへ: https://github.com/horoiwa/deep_reinforcement_learning_gallery
Pendulum-v0, Bipedalwalker-v3ともにハイパラ調整の試行錯誤なしで良いパフォーマンスを得ることができました。
soft-actor-criticでpendulum-v0 pic.twitter.com/JHmVVleSeW
— めんだこ (@horromary) 2020年12月20日
Soft-actor-criticでbipedalwaker-v3 pic.twitter.com/tGMnnbZThU
— めんだこ (@horromary) 2020年12月20日