Deep-Q-Network (2013) 以降の深層強化学習(Q学習)の発展を、簡単な解説とtensorflow2での実装例と共に紹介していきます。今回はDQNの改良トリックを全部盛りにしたら強いんでは?という脳筋発想によって生まれた手法であるRainbowを実装します。
DQNシリーズ
DQNの進化史 ①DeepMindのDQN - どこから見てもメンダコ
DQNの進化史 ②Double-DQN, Dueling-network, Noisy-network - どこから見てもメンダコ
DQNの進化史 ③優先度付き経験再生, Multi-step learning, C51 - どこから見てもメンダコ
DQNの進化史 ④Rainbowの実装 - どこから見てもメンダコ
- はじめに
- 構成要素の寄与について
- トレーニングループ
- Q-networkの実装(tensorflow2)
- ReplayBufferの実装
- ネットワーク更新(tensorflow2)
- Breakoutでの学習結果
- 次:Ape-X DQN
はじめに
[1710.02298] Rainbow: Combining Improvements in Deep Reinforcement Learning
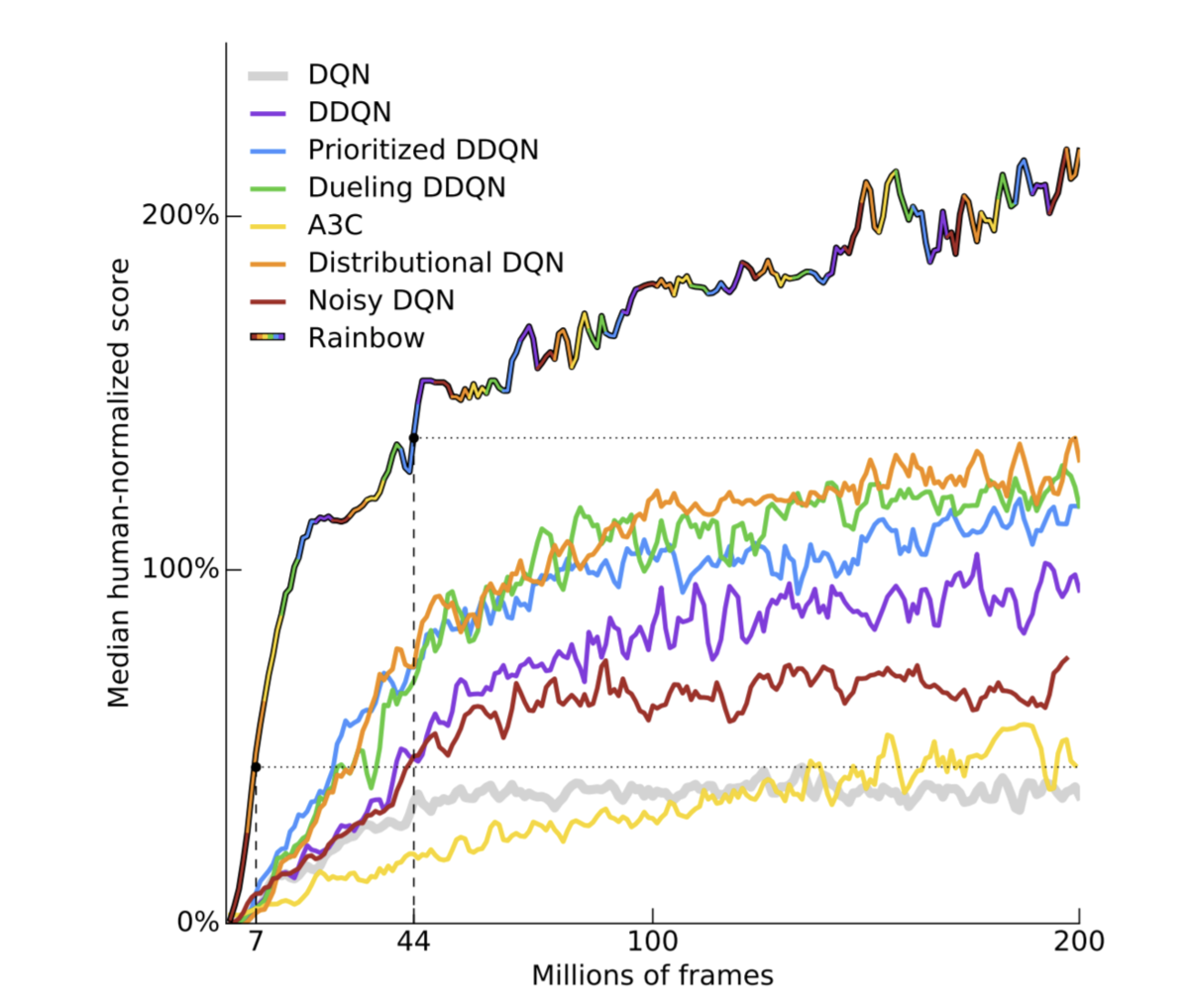
2017年に発表されたRainbowは、それまで報告されてきたDQN改良トリックをすべて搭載したDQNの総まとめ的な手法です。具体的にはオリジナルのDQNに、Double Q-learning, Dueling-network, Noisy-network, Prioritized Experience Replay, Categorical DQN(C51, or Distributional DQN), Multi-step learningの6つの手法を全部盛りにすることにより当時のatari環境のSotAを更新しました。
手法自体に目新しいことは無いので本記事では実装レベルの解説をしていきます。
構成要素の寄与について
論文ではRainbowの各構成要素をひとつ抜いた時にどれだけパフォーマンスが下がるか、という実験をしています。これによると優先度付き経験再生(prior)、分布強化学習(distributional)、Multi-step learningの寄与が大きいようです。
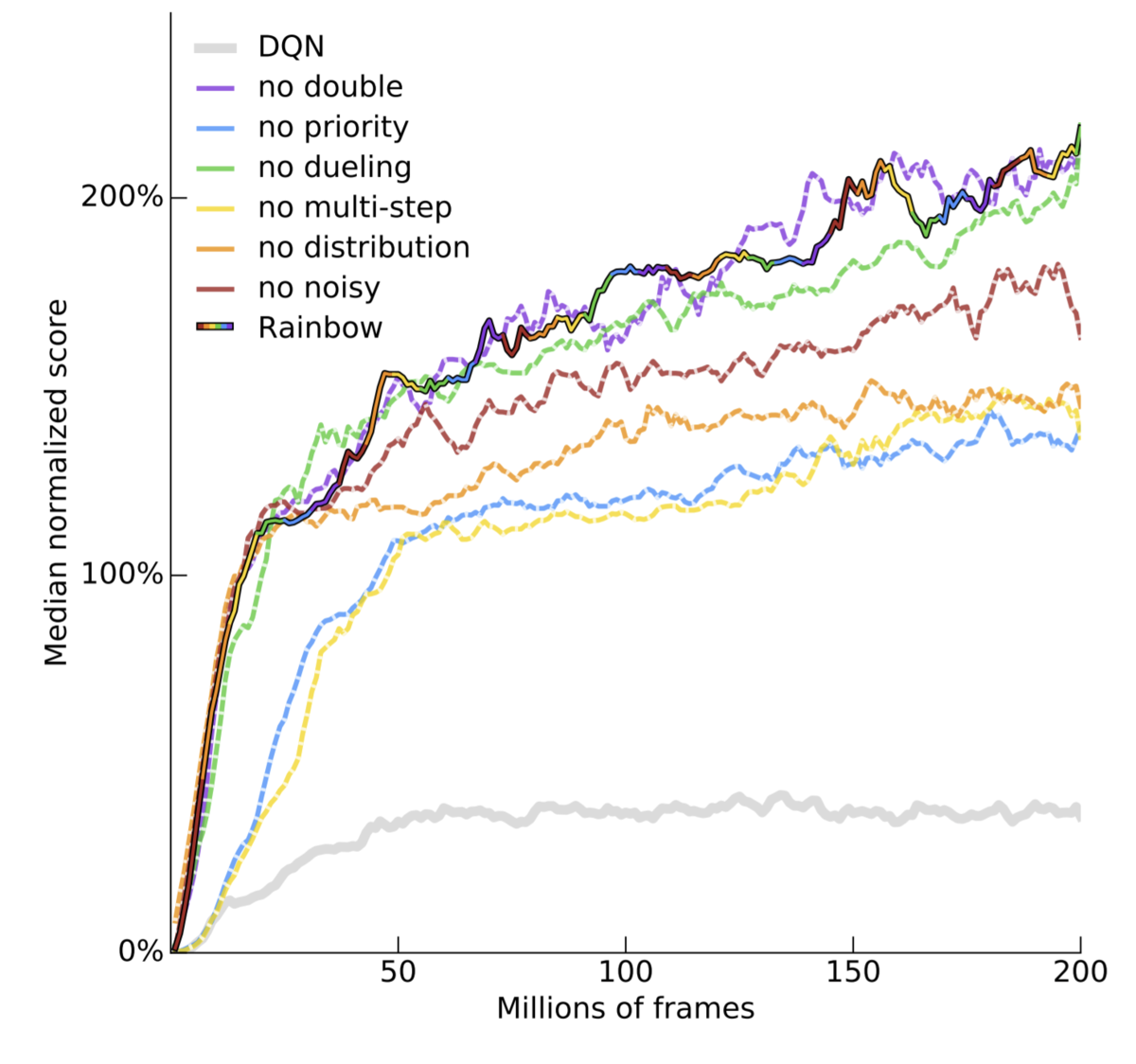
ただし、あくまで要素の一つ抜きだけでありすべての組み合わせを試しているわけではないので、各要素の寄与はFigに示されているほど単純に見積もることはできません。実際にtensorflowのチュートリアル( DQN C51/Rainbow | TensorFlow Agents)ではDistributional DQNとMulti-step learningの組み合わせだけでRainbowと同等のパフォーマンスが得られたという記述がされています。
Although C51 and n-step updates are often combined with prioritized replay to form the core of the Rainbow agent, we saw no measurable improvement from implementing prioritized replay. Moreover, we find that when combining our C51 agent with n-step updates alone, our agent performs as well as other Rainbow agents on the sample of Atari environments we've tested.
(C51とn-step更新は、優先リプレイと組み合わされてRainbowエージェントのコアを形成することがよくありますが、優先リプレイを実装しても測定可能な改善は見られませんでした。さらに、C51エージェントをnステップ更新のみと組み合わせると、テストしたAtari環境のサンプルで他のRainbowエージェントと同様に機能することがわかりました。)
トレーニングループ
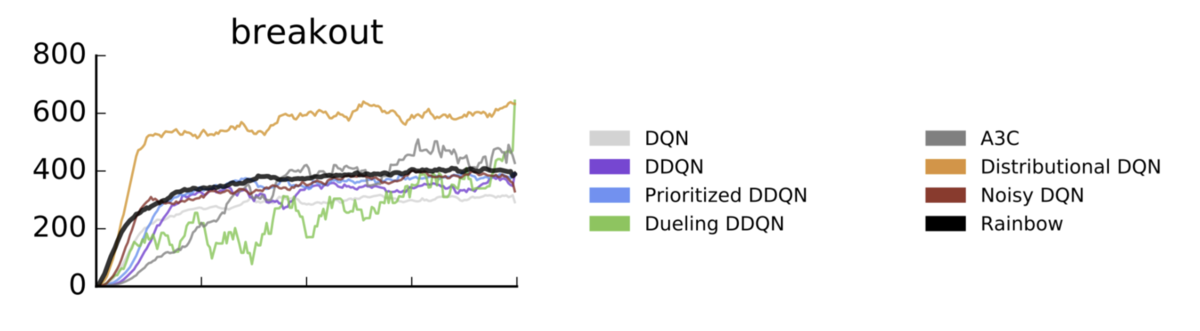
ハイパーパラメータはrainbow論文ではなく、 Categorical DQN論文(Distrubutional DQN)に従っていることに注意してください。これはBreakout環境ではDistributional DQN単体の方がパフォーマンスが良いためです。
Q-networkの実装(tensorflow2)
Qネットワークには Dueling-network, Categoical DQN (Distributional DQN), Noisy-network の3要素が導入されます。
ReplayBufferの実装
経験バッファには 優先度付き経験再生, Multi-step learning の2要素が導入されます。
注意:このリプレイバッファの実装は見通しの良さを重視しており、速度パフォーマンスを気にしないで実装しています。
SegmentTree構造を利用した高速な優先度付きReplayBufferの実装は別記事を参照ください。
ネットワーク更新(tensorflow2)
ネットワーク更新に絡んでくるのは、Double Q-learning、 優先度付き経験再生、Categorical DQN(Distributional DQN)の3要素です。
見ればわかりますがDistributional DQNの存在がTD誤差の計算をやたらと煩雑にしています。この詳細は過去記事を参照ください。
Breakoutでの学習結果
Breakout(ブロック崩し)を GCPのn1-standard-4(4-vCPU, 15GBメモリ) + GPU K80 のプリエンティブルVMインスタンス*1で24時間学習させました。1Mstep未満で40点取れてるので動作確認としては十分なスコアだと思います。(※rainbow論文では200Mstepを学習)
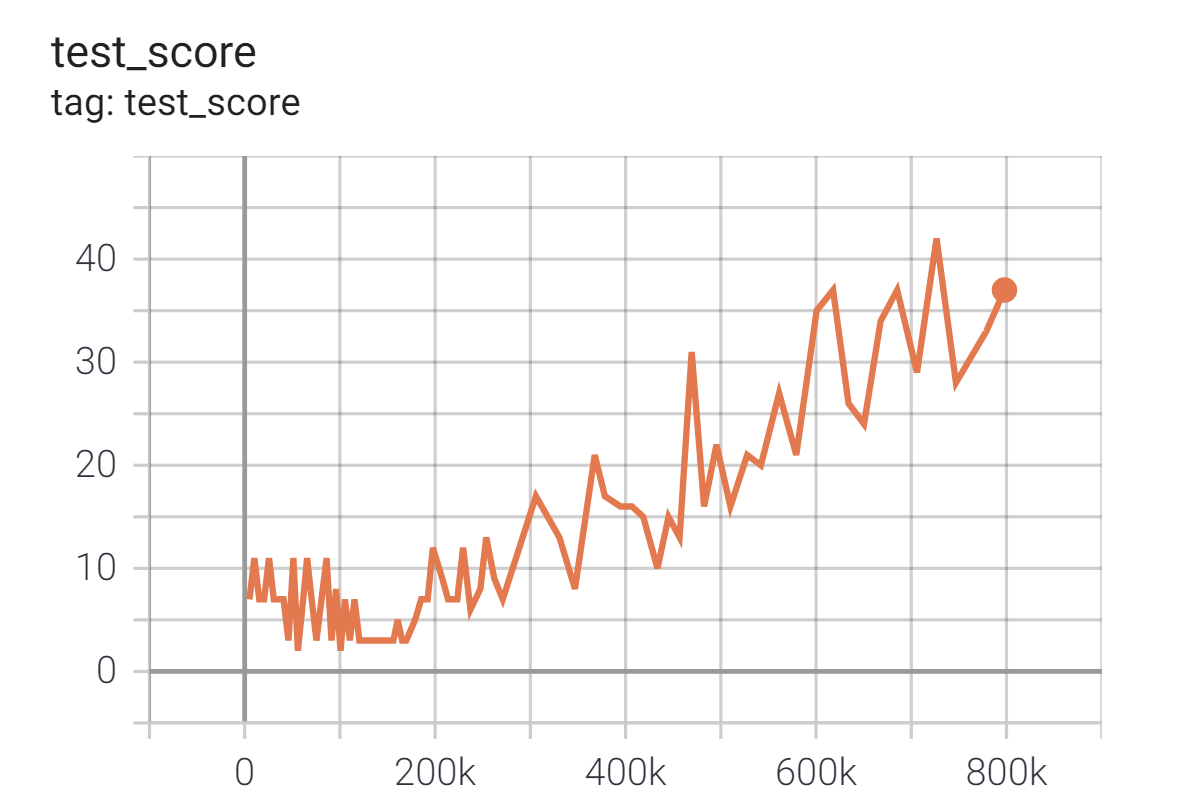
いろいろ試してみましたが、どうもBreakout環境はNoisy-networkとの相性が悪い印象を受けました。また、優先度つき経験再生を雑に実装*2しているため処理速度がかなり遅く24時間で1Mstepしか進行していません。
実装全体はgithubへ:
github.com
次:Ape-X DQN
C-51がいないおかげでRainbowよりApe-Xのほうが実装が楽に感じる。