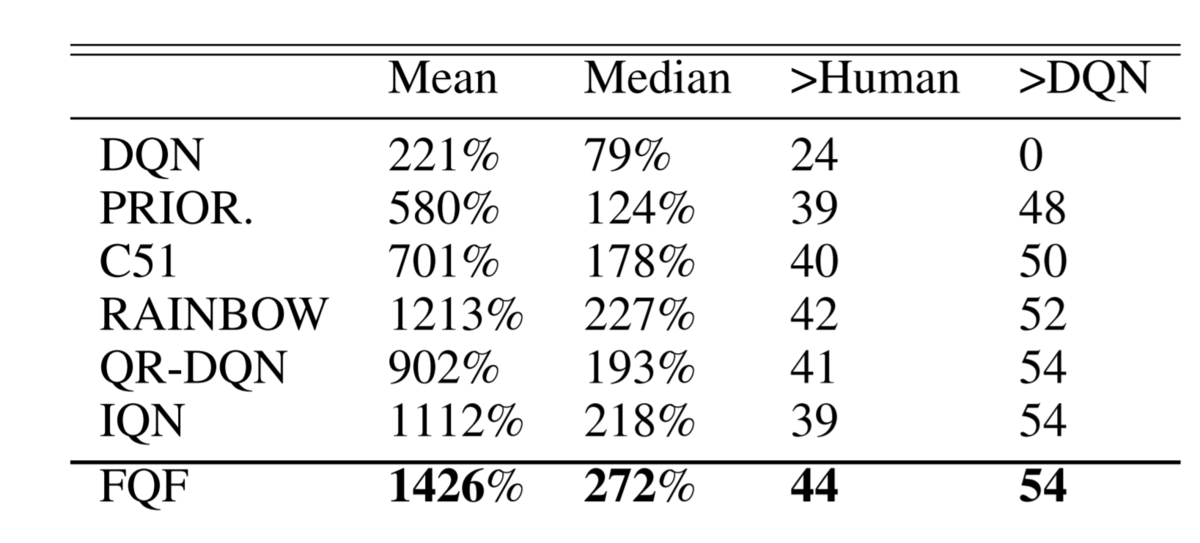
単体でRainbow越えを達成した深層分布強化学習手法FQFをtensorflow2で実装します。
前提手法:
horomary.hatenablog.com
はじめに
現実のほとんどの環境はランダム性を内包するため、状態価値は分布であると考えるのが妥当です。しかし、典型的な状態価値ベースの強化学習では状態価値分布の期待値のみの近似を目的とするため、状態価値が明示的に分布としてモデル化されることはありません。
これに対して、深層分布強化学習では状態価値を明示的に分布として深層学習により近似し、状態価値分布から状態価値分布の期待値を算出するというアプローチをとります。このような深層分布強化学習はリスク考慮型方策が可能になるなどいくつかのメリットがありますが、その最大の利点は状態価値を明示的に分布としてモデル化することは(なぜか)パフォーマンスの向上に寄与する、という点です。
状態価値分布のモデル化によりなぜエージェントのパフォーマンスが向上するかは(私の知る限りは)理論的に解明されていないものの、分布の近似がQネットワーク訓練のためのよい補助タスク(Auxiliary Tasks, 詳細はUNREALを参照)になっているのだろうと推察されます。
このような深層学習と分布強化学習の組み合わせの有用性は、 Categorical DQN, C51 論文から注目されるようになり、その後もQR-DQN, IQNなどいくつかの改良手法が提案され続けています。本記事で実装を紹介するFQF(Fully Parameterized Quantile Function for Distributional RL)もそのひとつであり、特筆すべきはついに単体でRainbow超えを達成したことです。
論文:
[1911.02140] Fully Parameterized Quantile Function for Distributional Reinforcement Learning
Microsoftの実装・解説:
Finding the best learning targets automatically: Fully Parameterized Quantile Function for distributional RL - Microsoft Research
C51 → QR-DQN → IQN
FQFの話を始める前にこれまでの深層分布強化学習の各手法がどのようなアプローチで分布をモデル化してきたのかを確認しましょう。
Categorical DQN (C51) では、素直にカテゴリ分布によって状態価値の確率分布を近似します。このアプローチは一定の成功を収めたものの、分布の最大値/最小値の設定が重要なハイパラになっていたり、ベルマンオペレータの適用で生じるビン幅のずれの修正処理が煩雑だったりといくつかの欠点を抱えていました。
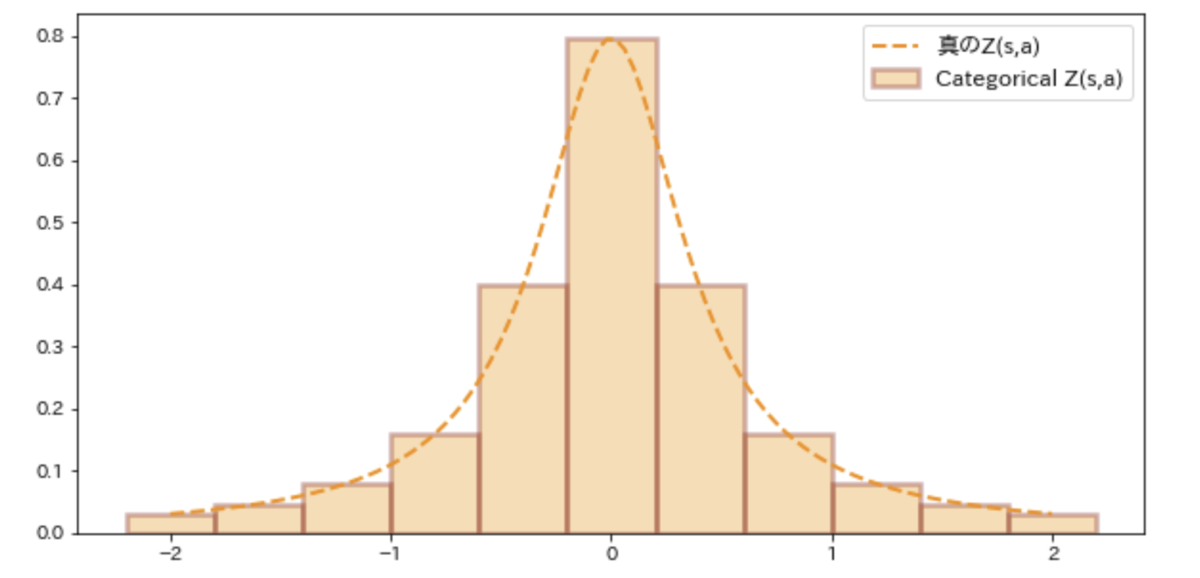
QR-DQNでは、状態価値分布の分位点を予測する=状態価値分布の累積分布関数の逆関数を近似するというアプローチによりC51の残したいくつかの課題を解決しました。
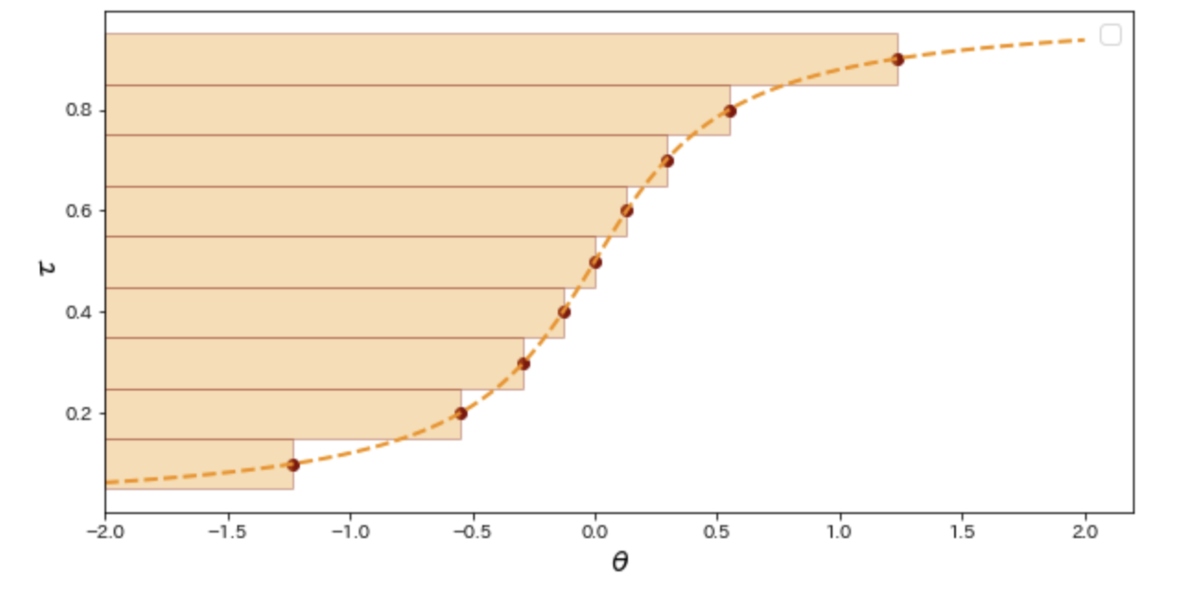
IQNでは、QR-DQNはあらかじめ設定された均等幅の分位しか予測しないため真の状態価値分布を近似することができないという課題に対して、Qネットワークに状態sとともにランダムサンプリングされた分位τを与えて、対応する分位点を予測させるIQNアーキテクチャを提案しました。訓練済みのIQNネットワークは任意の分位τについて分位点を予測することができるので、十分に多くの数の分位τをサンプリングすれば滑らかな状態価値分布を近似することができるはずです。
FQFとは:いい感じのτを提案する機構付きのIQN
IQNで提案されたQ関数に任意の分位τの分位点を予測させるアーキテクチャでは、十分に多くの分位τをQ関数に入力することで実質的に状態価値の累積分布関数の逆関数
を近似することができます。しかし、IQNアーキテクチャでは与えられる分位τの数に応じてニューラルネットワークのパラメータ数が増え学習が不安定になるため、可能ならばできるだけ少ない分位の予測で済ませたいところです。
少ない分位で
をうまく近似するには、
累積分布関数の形状(=状態価値分布の形状)に応じていい感じにτを選ぶことが必要です(下図)。そこで、状態sに応じていい感じの分位τセットを提案するネットワークをIQNに追加したのがFQFであると理解できます。
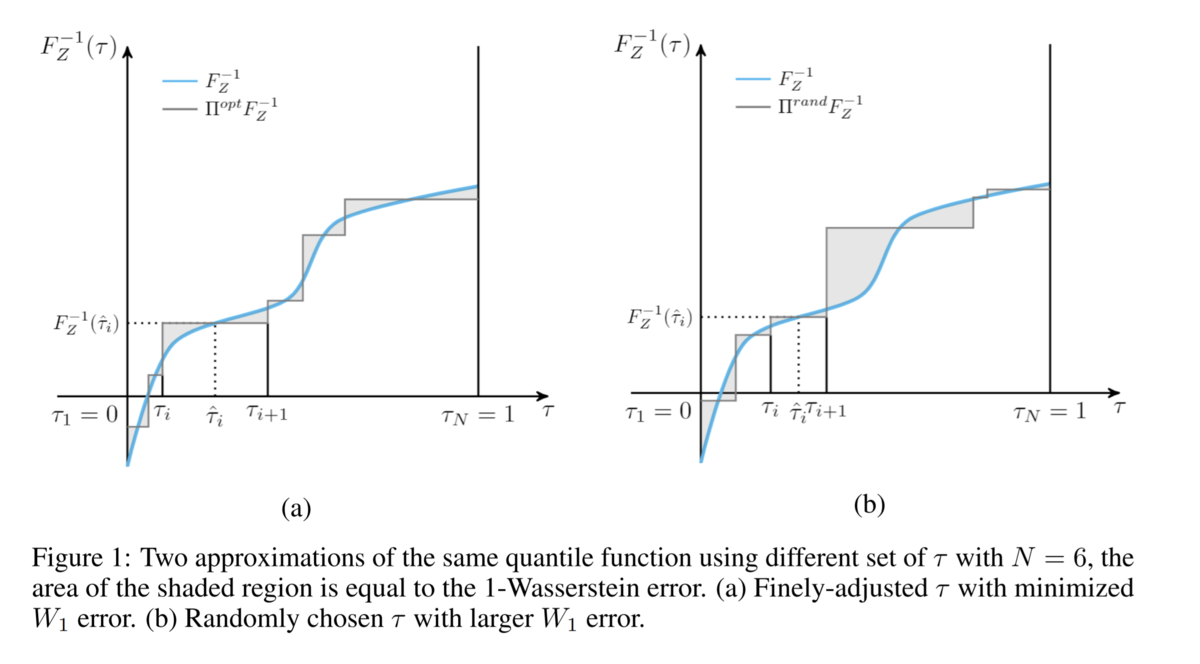
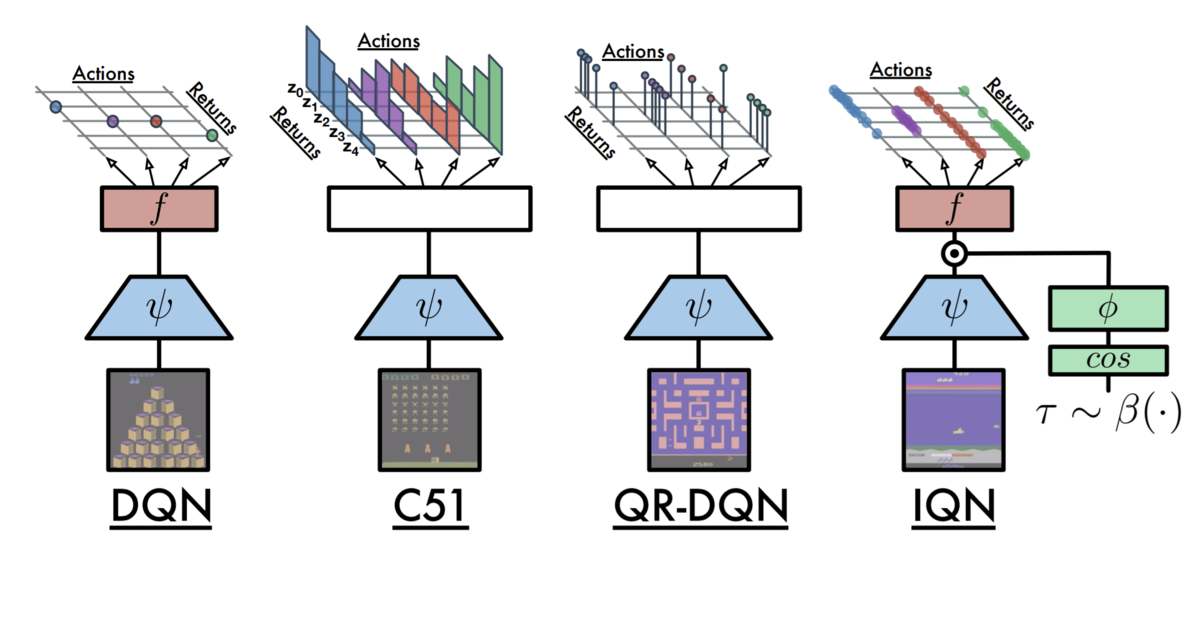
FQFとは具体的には下図(論文著者の解説記事より転載)のようになります。このFQFアーキテクチャから分位提案ネットワーク(frction proposal network)が除去されるとQR-DQNとなります。また、分位提案ネットワークが一様分布からのサンプリングに置き換えられるとIQNとなります。CNN層 (future network) & Quantile function network の訓練と 分位提案ネットワークの訓練は独立して別のロス関数で行うことに留意してください。詳細は後述。
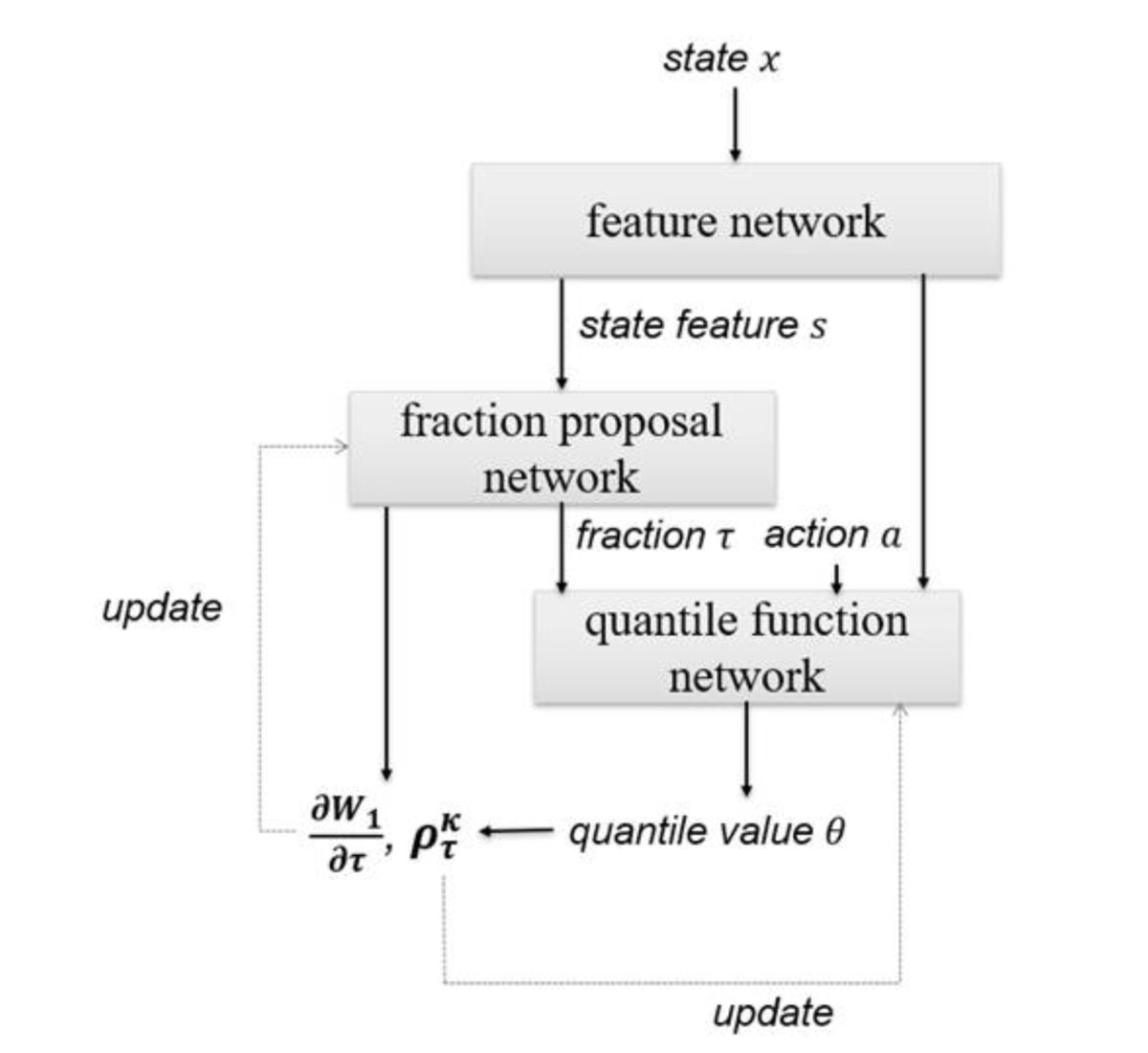
FQFネットワークの実装
※この実装はMicrosoftによる公式実装 を参考にしています。基本のトレーニングループについては基本とDQNと変わらないので割愛します。
コード全文:
FQFアーキテクチャ
上のアーキテクチャ図に示したようにFQFは複数のネットワークで構成され、そのままでは扱いづらいのでそれらをとりまとめるFQFモデルを実装します。(各構成要素についての詳細は後述。)
このモデルはまず入力として受け取った状態sをFeature Networkに通して特徴抽出を行います。さらに抽出された状態特徴(state_embedded)を分位提案ネットワークに入力することにより分位のセットおよびその中点
を提案させます。
たとえばnum_quantiles=4のときに =[0, 0.2, 0.6, 0.9, 1.0]のように分位τが提案された場合は、この中点
=[0.1, 0.4, 0.75, 0.95] となります。このうち、
をQuantile function networkに入力し、対応する分位点を出力します。
については分位提案ネットワークの更新にのみ使用します。
Feature network:特徴抽出ネットワーク
状態Sから特徴抽出するネットワークですが、これはただのDense層を除いたDQNアーキテクチャなので解説不要ですね。入力がDQN論文と同じ(84, 84, 4)であれば出力は(3136,)となります。
Fraction proposal network:分位提案ネットワーク
FQFのキモである状態特徴を入力として分位τを提案するネットワークです。出力する分位τが 単調増加 かつ 0≦τ≦1 であることを保証するために、softmaxを取った後に累積分布を計算します。さらに、0.01や0.99など極端に0 or 1に近い数の提案を許可すると学習が不安定化したため、この実装ではtf.clip_by_valueで提案できる分位を0.1から0.9の範囲に制限しています。
Quantile function network:分位点予測ネットワーク
構成要素で一番ややこしいのが。状態特徴state_embeddedと提案分位quantiesを入力として、提案分位に対応する分位点を予測する分位点予測ネットワーク(Quantile function network)です。難解ではなくややこしいだけです。
状態特徴state_embeddedと提案分位quantiesを入力として分位点を予測するネットワーク構造は(たとえばDDPGのように入力直後にconcatするなど)いろいろと考えられますが、FQFでは IQN論文 で提案されたものをそのまま使用します。すなわちCosine embedding(下式)によりquantilesの次元を状態特徴state_embeddedと同じ3136次元まで増幅した後、state_embeddedとの要素積をとります。
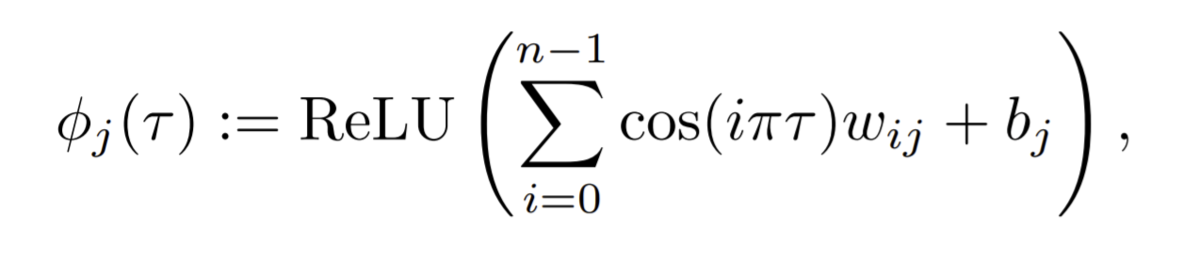
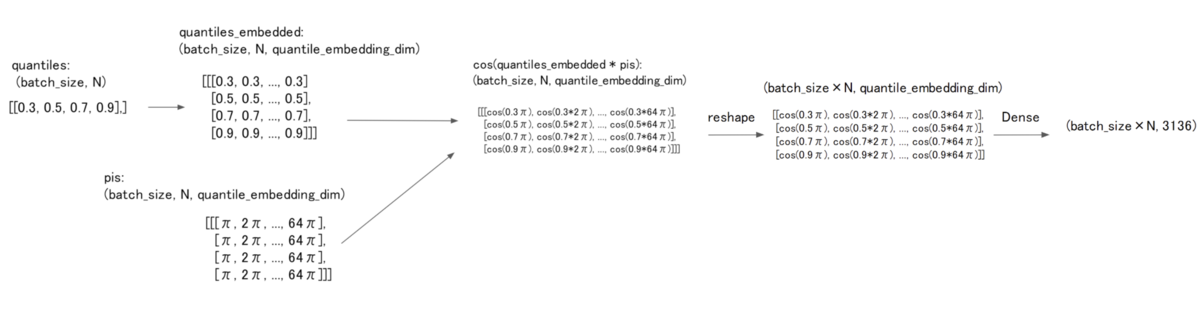
Cosine Embedding周りのshape操作が煩雑でわかりにくいのでshapeの遷移図を描きました。
FQFネットワークの更新
前述の通り、(Feature network + Quantile function network ) と (Fraction proposal network) は別のロス関数で独立した訓練を行います。
(Feature network + Quantile function network )のネットワーク更新はQR-DQNとほぼ同じです。ただし、ベルマンオペレータの適用において、オンラインネットワーク*1が提案した分位τおよびオンラインネットワークが出力したターゲットネットワークでも利用していることにだけ注意してください。
分位提案ネットワークの更新
前述の通り、分位提案ネットワークの役割はいい感じの分位τを提案することです。そして分布強化学習におけるいい感じの分位とは2つの分布間のWasserstein距離が最小化されるような分位τです。
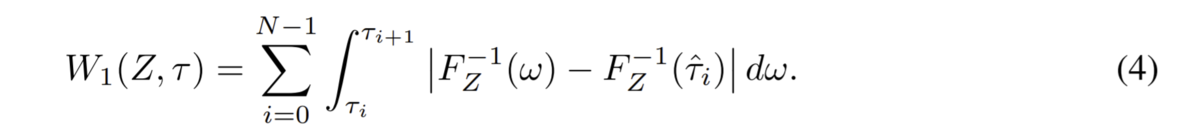
よって、安直にはWasserstein距離をロス関数として分位提案ネットワークを訓練したいところですが、しかしWasserstein距離は直接計算することが現実的ではないため*2 このアプローチは不可能です。
代替案として、FQF論文ではWasserstein距離を直接計算するのは困難だけども、提案分位τについての1-Wasserstein距離の微分なら近似的に計算できるよ、ということを証明(Appendix: Proof for proposition 1)しました。
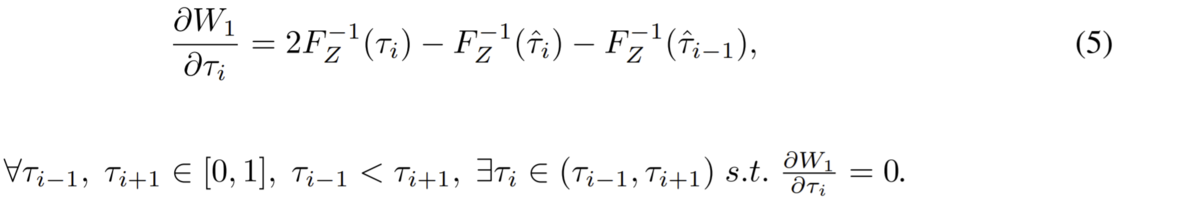
分位提案ネットワークのパラメータをθとすると、θについての1-Wasserstein距離の微分は連鎖律を利用して、
と表せます。ここで
は論文が示す計算式によって、また
はtensorflowの自動微分によって計算できるので分位提案ネットワークを訓練できるようになりました。
実装上の注意として論文にも記載があるのですがtensorflowで明示的に連鎖律を使用するときは、tensorflow1.Xではtf.gradient(taus, network_params, grad_ys=dw_dtau) のようにgrad_ys引数を利用します。*3。一方、tensorflow2.X系でwith GradientTape() as tapeを使う場合は引数名が変わり tape.gradient(taus, network_params, output_gradients=dw_dtau) とします。
ただし、論文には記載されてませんが Mictosoftの公式実装 のREADMEでは の二乗をロス関数として使うことを推奨しています*4。こちらの方が実装がわかりやすいので下の例ではL2ロスを採用しています。
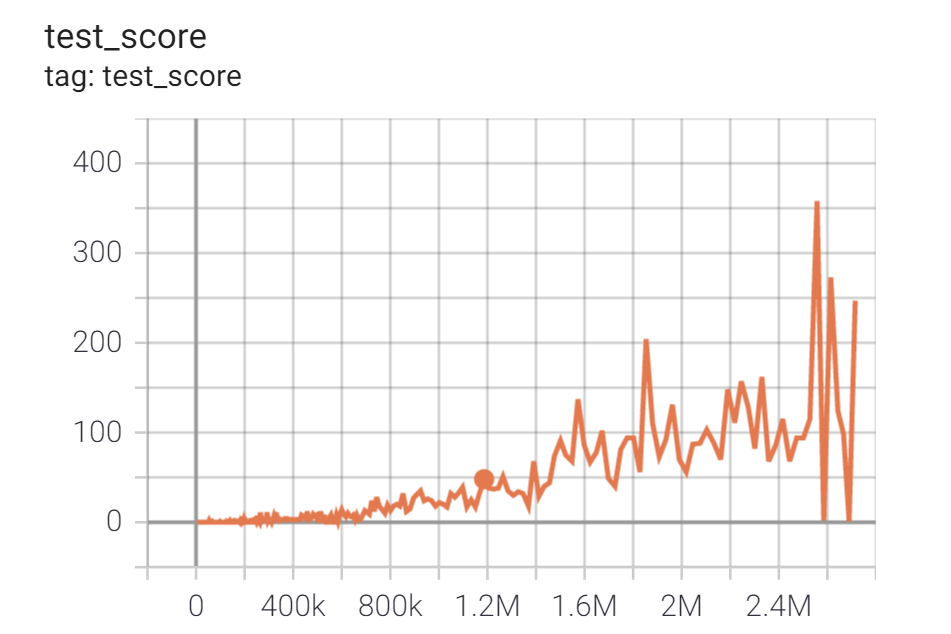
学習結果:Breakout環境
BreakoutDeterministic-v4環境(ブロック崩し)において、GCPのn1-standard-4(4-vCPU, 15GBメモリ) + GPU K80 のプリエンティブルVMインスタンスを使って24時間学習を行い、妥当な性能が得られることを確認しました。アーキテクチャが複雑なのでやはり計算処理が重く、速度パフォーマンスはQR-DQN比較でざっくり60%程度となりました。
*1:target networkじゃないほう
*2:このあたりの議論はC51論文を参照
*3:tensorflow - tf.gradients, how can I understand `grad_ys` and use it? - Stack Overflow
*4:Readme.md, BugFixedの項:It is recommended to use the L2 loss on gradient for probability proposal network