プロンプト戦略のみで大規模言語モデルの医療ドメイン適応に成功したMed-PaLMのアプローチをまとめます。
- ナレッジベースとしての大規模言語モデル
- Med-PaLM:プロンプト戦略によるドメイン適応
- プロンプト戦略:Instruction Prompt Tuning
- 医師とMed-PaLMの回答比較
- 次:?
ナレッジベースとしての大規模言語モデル
十分な事前学習が行われた大規模言語モデル(LLM, Large Language Model)は一般の人間を遥かに超えた知識をそのパラメータに記憶しています。たとえばGPT4などは膨大なWebコーパスを学習しているのですからインターネット知のすべてがそのモデル内に蒸留されているとも表現できるはずです。
ゆえに大規模言語モデルを特定分野のナレッジベース、たとえば体調不良の症状から考えられる病気を検索する簡易診断ツールなど、として使いたいと思うのはごく自然な発想でしょう。しかし、実際にchat-GPTに専門的な質問をしてみると驚くほど間違いが多いことに容易に気が付きます。たとえばジャンガリアンハムスターについて質問してみると、chat-GPT(GPT3.5, 2022年12月に実行)はチンチラとハムスターを混同していることがわかります。

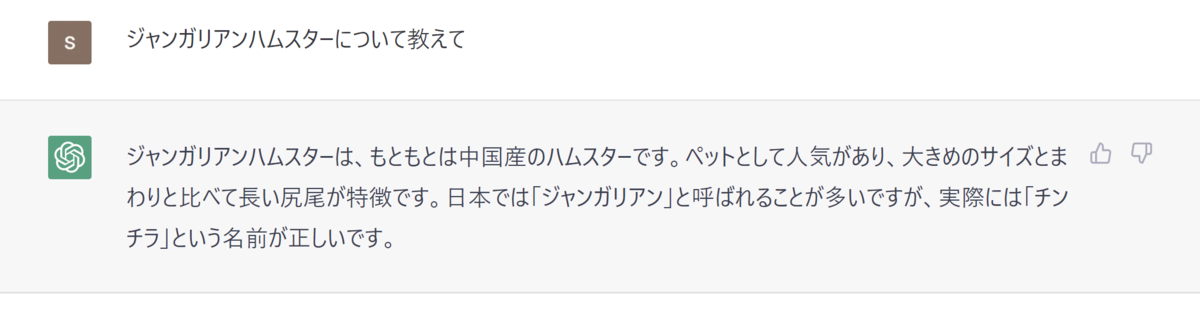
ハムスターのことさえまともに答えられない大規模言語モデルを特定分野のナレッジベースとして活用するのは無謀なのでしょうか? しかし、そもそもGPTは条件付き確率P(Y | X)にもとづいてテキスト生成しているだけであることを鑑みれば、条件付け(X: 質問文)が悪いために言語モデルがパラメータ内に記憶している知識(Y: 回答)をうまく引き出せていないということも考えられます。換言すると、うまく質問文を設計することで言語モデルをより信頼できるナレッジベースとして活用できる可能性があります。
Med-PaLM:プロンプト戦略によるドメイン適応
The Check Up with Google Health 2023 - YouTube (13分くらいから)
GoogleとDeepMindによって2022年12月に発表されたMed-PaLMは、"上手に質問することで言語モデルから効果的に知識を引き出す"というアプローチを突き詰めることにより大規模言語モデルFlan-PaLMのドメイン特化追加学習を一切行わず(!!)、プロンプト戦略のみによって医療ドメインへの適応を成功させました。(なお、Flan-PaLMはGoogleのマルチモーダル基盤モデルPaLMを指示によく従うようファインチューニングしたものです。手法は異なりますが直感的にはFlan-PaLMとPaLMの関係はchat-GPTとGPT3の関係に相当します。)
元モデル(Flan-PaLM)のパラメータに一切の変更を加えていないにもかかわらずMed-PaLMは顕著な性能向上を示しています。MedQA-USMLE(アメリカ医師国家試験にもとづく多肢選択式の質問応答)ベンチマークではAIモデルとしてはじめて合格ライン(60%以上)を上回る67.6%のスコアを記録し、さらにこのスコアは次バージョンのMed-PaLM2でさらに85%にまで向上した(ソース)ことが23年3月に発表されています。
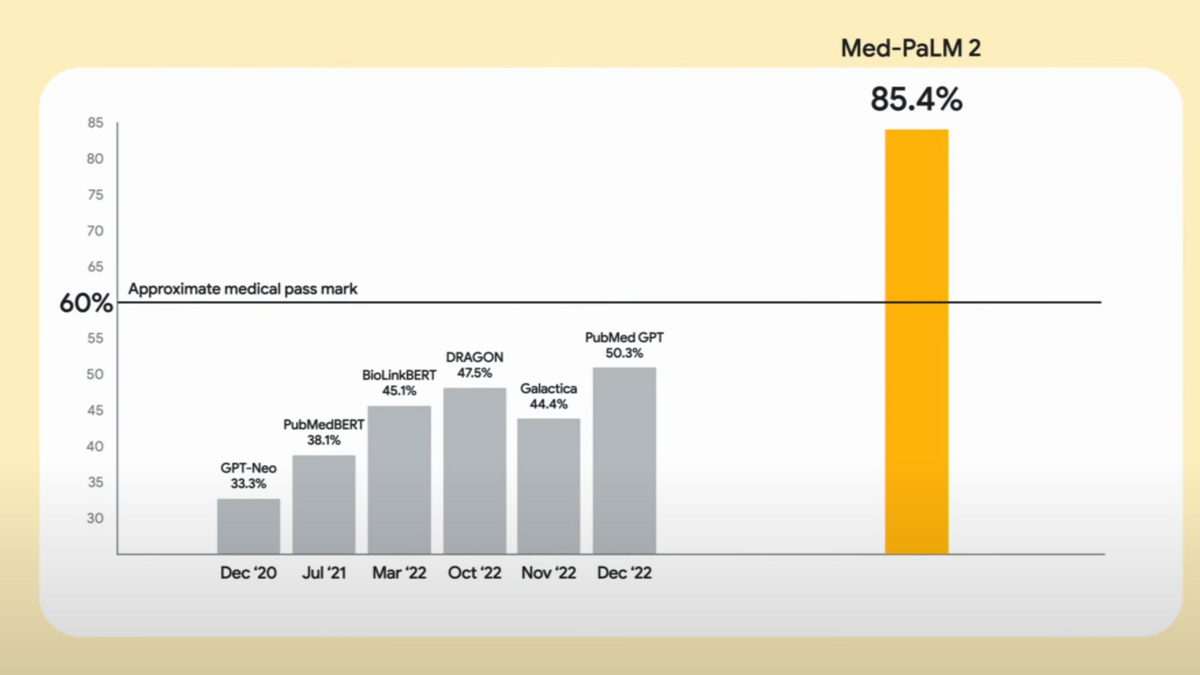
試験問題だけでなく、より実用的な問題設定であるHealthSearchQAベンチマークにおいても専門家に比肩する性能を発揮しています。HealthSearchQAとは、「医療関連で患者からよくある質問」に自由記述で回答するというAIにとっては挑戦的なベンチマークです。このベンチマークにおいて、元モデルのFlan-PaLMでは医学的に正しい回答ができたのは62%であったのに対して、Med-PaLMではプロンプト戦略によって専門家に相当する92%を実現しています。

これまで大規模言語モデルの産業応用の大きな障壁のひとつであったのは、ドメイン適応のためのファインチューニング用データセット構築です。しかし、Med-PaLMでははるかに省エネなアプローチであるプロンプト戦略によって実用レベルのドメイン適応が可能であることを示しました。これによって高品質スモールデータ(専門家が作成したマニュアルなど)の活用がますます進んでいくと思われます。
プロンプト戦略:Instruction Prompt Tuning
(2022/3/22: soft promptの説明の誤りを修正)
Med-PaLMのプロンプト戦略はソフトプロンプトとハードプロンプトを組み合わせたハイブリッドアプローチであり、これを指してInstruction Prompt Tuningと呼称しています。ここで、ソフトプロンプトとは高品質スモールデータを教師とした誤差逆伝播で獲得された、最適ではあるが人間には解釈不能な、自然言語換算で100トークン(Med-PaLMの場合)に相当するembeddingです。ハードプロンプトとは人間によってデザインされたプロンプトであり、たとえば「ステップバイステップで考えましょう」という指示をプロンプトに含めると回答の論理性が向上するというものです。
(ソフトプロンプト、ハードプロンプトともにそれ自体は既出手法ですが、Med-PaLM論文ではprefixとしてのsoft-prompt, few shot exemplarsとchain of thoughtを備えたハードプロンプトの組み合わせ方が新しいと主張しています)
ハードプロンプト: 人間によってデザインされたプロンプト
指示の与え方によって言語モデル(というかChat-GPT)の応答品質が全く変わってくるというのは良く知られた事実ですが、 [2210.11416] Scaling Instruction-Finetuned Language Modelsではchain-of-thought(思考ステップ)とfew-show exemplars(同形式別問題の解答例)をプロンプトに明示すると言語モデルの性能が格段向上することを詳細検証しています。

このような人間によるプロンプト設計が性能向上に有効だという話はすでに広く知られた事実ありweb上にいくらでも情報があるのでここで詳細な説明は行いません。
ソフトプロンプト: 学習によって獲得する最適プロンプト
[2104.08691] The Power of Scale for Parameter-Efficient Prompt Tuning
ソフトプロンプトとは高品質スモールデータを教師データとした誤差逆伝搬によって獲得される、人間には解釈不可能だが回答をいい感じにしてくれる、自然言語換算で100トークン(Med-PaLMの場合)に相当するembeddingです。このような最適プロンプトに相当するembeddingを直接学習する手法はPrompt tuningと総称されます。
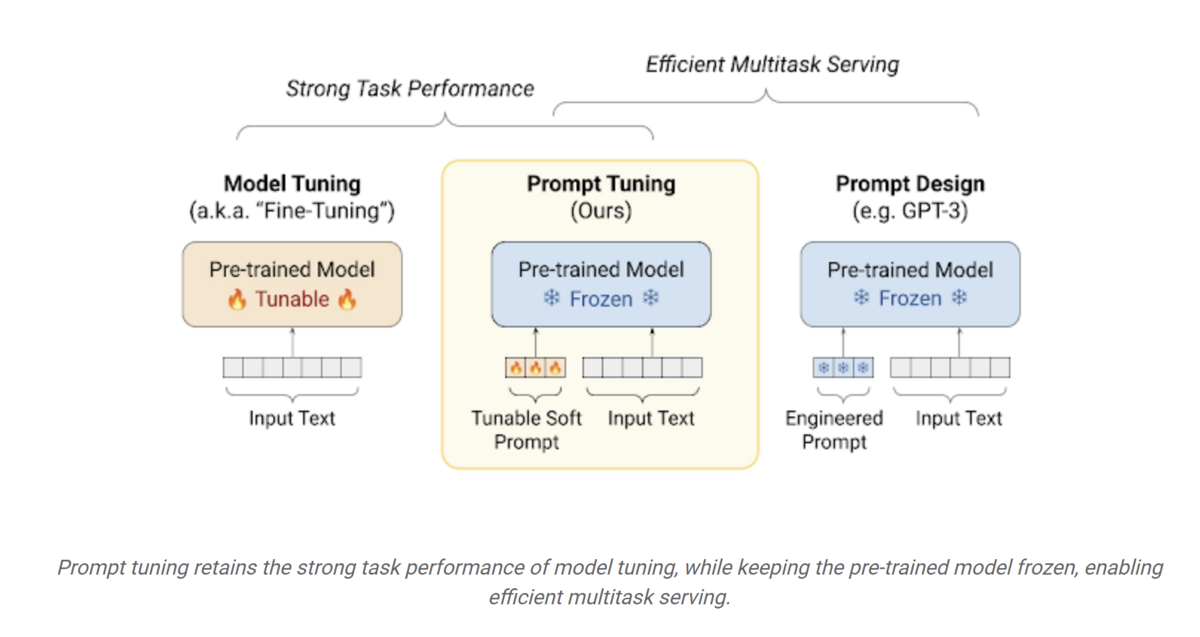
prompt tuningによる最適embeddingの獲得手順は元モデルのファインチューニングの手順とほぼ同様です。すなわち、自然言語で100トークンに相当するランダムなベクトルをプロンプトのprefixとして与え、あとはこのベクトルのみをtrainable paramterとし、元のモデルの重みは固定してファインチューニングを行うことでembeddingを最適化することができます。
ファインチューニングと比較すると、prompt tuningでは元モデルの重み固定であるためにはるかに計算量が少なく、かつtrainableパラメータ数が少ないためにはるかに少ない教師データで実行することができます。また、最適なプロンプトを探すだけなので過学習の心配もそれほどありません。
なお、Med-PaLMでは40の自由記述式問題を3人の臨床医に回答してもらうことでデータセットを構築しprompt tuningを行っています。文字通りならば120の質問/回答ペアで十分なパフォーマンス向上が得られたということであるので驚くべき省エネ性能です。
(Appendix A1: Med-PaLMのsoft prompt用のEmbedding層は1.84Mのパラメータを持ち100トークン相当のsoft promptを出力)
医師とMed-PaLMの回答比較
Med-PaLMのほうが説明が丁寧で情報量が多い印象。医師がナレッジベース兼説明アシスタントとして使うならすぐ実用できそう。

次:?
ドメイン特化LLMについては継続的に調べていきたい