Pythonの分散並列処理ライブラリであるRayとTensorflow2を使って分散強化学習の主要な手法を実装していきます。 まずは分散強化学習の草分け的な手法であるA3C (Asynchronous advantage actor-critic、非同期アドバンテージアクタークリティック) です。

- はじめに
- Rayとは
- A3C(Asynchronous advantage actor-critic)
- 1. 非同期処理(Asynchronous)
- 2. アドバンテージ関数 (Advantage)
- 3. Actor-Critic
- CartPole-v1での学習結果
- 次:A2C
- 付録:Agentクラスの実装
はじめに
主要な強化学習手法の多くが分散並列学習を前提にしている一方で、Pythonは並列処理もノード分散処理もそれほど得意ではなく、とくに非同期並列処理のPython実装にはプログラミング的な高い障壁が存在していました。
しかし、近年 rayライブラリが救世主的に登場したことにより、Pythonでの分散並列処理の敷居は大きく下がることとなりました。
Ray provides a simple, universal API for building distributed applications.
- Rayは、分散アプリケーションを構築するためのシンプルでユニバーサルなAPIを提供します。
rayは素晴らしく使いやすいのに日本ではまだまだ認知度が低いライブラリですので、応援の意味も込めてrayによる分散強化学習の実装例を紹介していきます。※rayは強化学習だけでなく並列分散処理が必要なすべての処理で便利なライブラリです。
Rayとは
rayはpip install可能なpythonパッケージであり、rayライブラリを使用することで既存のライブラリよりもはるかにシンプルでPythonicなコードで分散並列処理を実装できるようになります。マシン内での並列処理が簡単に記述できるのも良いところですが、さらに素晴らしいのはマシン内並列処理そのままのコードでクラスタ間での分散並列処理にスケールアップできることです。ただし、rayライブラリは並列処理の開始時のオーバーヘッドがわりと大きいので軽いタスクの並列化には向かないことには留意ください。
rayライブラリの基本的な使い方については本記事では省略しますので、公式ドキュメントや過去記事を参照ください。
Tips for first-time users — Ray v2.0.0.dev0
A3C(Asynchronous advantage actor-critic)
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning
A3Cは深層強化学習において分散並列学習の有用性を当時のatari26000環境のSOTAという結果で示した重要な手法です。その一方で(当時の)Pythonでは実装するのがクソ面倒くさい手法でもありました。これはA3Cに非同期(Asynchronous)並列処理という言語特性上の理由でPythonと非常に相性の悪い処理が入っていることが原因です。
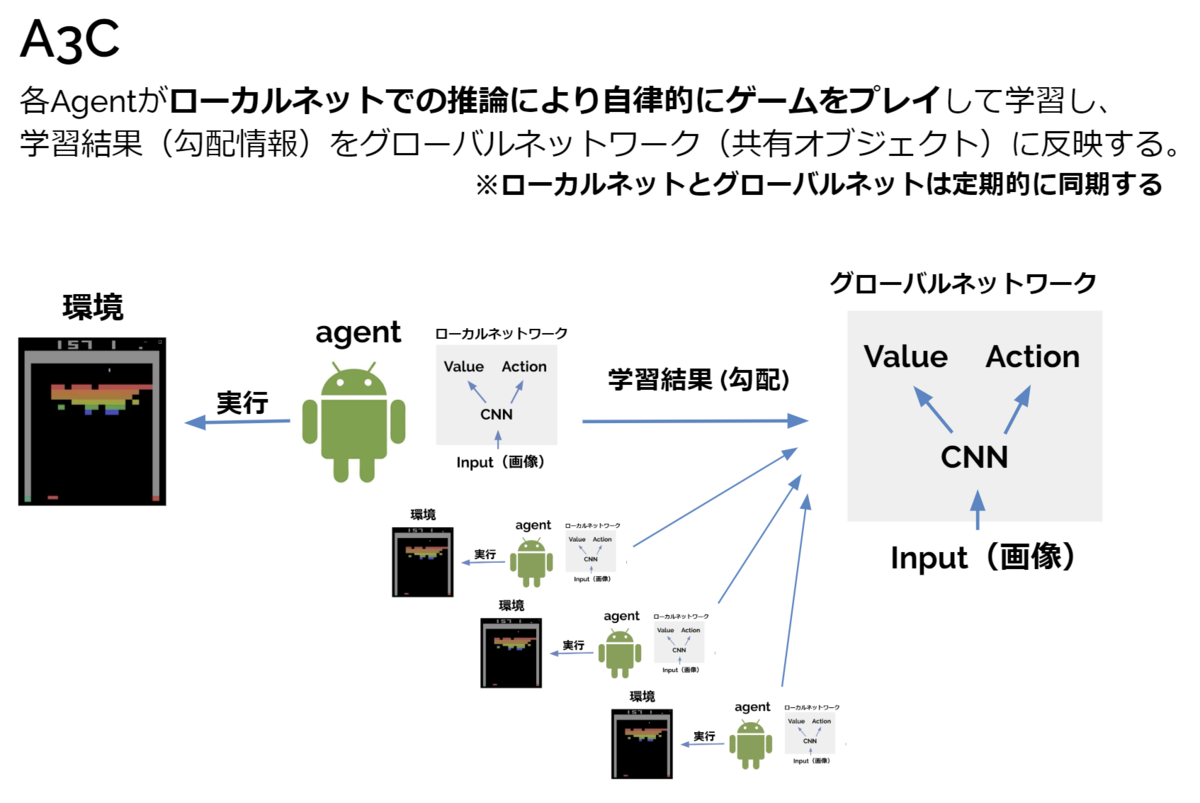
A3Cでは並列化されたagentが自律的にrolloutを行い、好き勝手なタイミングで勾配計算してその勾配情報をパラメータサーバに送り付けてきます。この好き勝手なタイミングというのが本当にPythonと相性が悪く、過去記事ではthreadingモジュールを使用して非同期処理もどきの実装で妥協しました。そこで、本記事ではrayによる実装でA3Cにリベンジを行います。
1. 非同期処理(Asynchronous)
非同期処理の実装
参考:Asynchronous Advantage Actor Critic (A3C) — Ray v2.0.0.dev0
A3Cの最初のAである非同期(Asynchronous)とは上述の通り、並列化されたagentが自律的にrollout → 勾配計算し、勾配計算が終わった順に勾配情報をパラメータサーバに送付してくるような処理です。この勾配計算が終わった順に処理する実装が既存ライブラリでは本当にめんどくさいポイントだったのですが、rayのray.waitを使用するとシンプルに記述できます。
たとえば、ray.waitを使って処理が終わった順に結果を取得してまた新たな処理を追加する流れは下のように記述できます。
Agentクラスインスタンスごと並列プロセスにしているのが重要なポイントで、これは状態をもつ並列プロセスを容易に実装できるということです。これは強化学習をするうえで超便利です。
この例ををそのままA3Cに転用したのが下のコードです。
tf2で実装する場合の注意:
tensorflow2(tensorflow.keras.Model)で実装する場合は、ネットワークを別ファイルに定義しないとTypeError: can't pickle _thread.lock objectを吐きます。rayは並列化プロセスの開始時に同一ファイル内のオブジェクトはpickle化して分岐させるのに対して、tensorflow.keras.Modelは簡単にpickle化できないことに原因があるのではないかと想像しています*1。ゆえに別ファイル内に定義してimportする、あるいはAgentクラス内にtensorflow.keras.Modelを定義することでエラーを回避できます。
分散学習の効果
並列分散学習を行うことは単純にCPUリソースに応じて学習が高速化するという恩恵もありますが、経験の自己相関を低減し学習を安定化する効果が期待できます。経験の自己相関による学習の不安定化は強化学習が長く抱えてきた課題です。例えば、DQN (2013)では オフポリシー手法であることを生かしたExperience Replay (経験再生) 機構 でバッファに蓄積した経験をランダムに取り出しミニバッチを作成することで経験の自己相関を低減しています。
これに対してA3Cではサンプルを集めるAgentを並列化することで自己相関を低減するという手段をとりました。この並列化アプローチは非常に効果的である上、他手法でも容易に転用可能なアイデアであるのでA3Cの発表後には強化学習分野には分散並列化ブームが到来することとなります。
2. アドバンテージ関数 (Advantage)
参考: Vanilla Policy Gradient — Spinning Up documentation
A3Cの2つめのAであるAdvantageとはアドバンテージ関数を使用して方策勾配を計算することを指します。
ここで、
アドバンテージ関数を使用しない場合はQ(s, a)を使用して方策勾配を計算するのに対し、アドバンテージ関数を使用する場合はA(s, a) = Q(s, a) - V(s, a) を 使用して方策勾配を計算します。V(s, a)とは すべてのaについてのQ(s, a)の期待値であるはずなので、どちらの方法で計算しても勾配の平均値には影響ありませんが、アドバンテージ関数を使うと勾配の分散が小さくなり学習が安定化します。
アドバンテージ関数の実装
※簡単のため割引率γは表記無し
上述のように、アドバンテージ関数とは状態行動価値 Q(s, a)からベースラインである状態価値V(s, a)を引いた値と定義されています。
アドバンテージの定義
このアドバンテージの算出には様々な選択肢が存在していることがA3Cの理解をややこしくしている理由のひとつです。例えば、もっともシンプルなアドバンテージ関数は、1step先までの即時報酬の情報(1step return)を使用した下記のような実装です。
1-step return advantage
あるいは、n-step先までの即時報酬の情報(n-step return)を使用することもできます。
N-step return advantage
A3CではこのN-step returnが混合されたものが使われます。
たとえばミニバッチとして連続する5stepを切り出してきた場合、1step目では5-stepアドバンテージを、2step目では4-stepアドバンテージを、・・・、5step目では1-stepアドバンテージを計算します。ゆえに論文では mix of n-step return と表現されています。
正直コード見るのが一番わかりやすいかと思います。
3. Actor-Critic
パラメータ共有型ネットワーク
Actor-Criticでは、一般的には*2 方策関数(Actor)と状態価値関数V(Critic)*3を別々に関数近似します。これに対してA3CではCNNを使用するドメイン(つまりatari2600環境)に限って、方策関数と状態価値関数を一部のパラメータを共有する分岐型ネットワークとしてまとめて実装します。
今回はCartPoleなのでCNNは使わないのですがせっかくなのでパラメータ共有型のモデルで実装してみます。
CNNのときのみ分岐型ネットワークで実装するとなぜ良いのかは論文内では明言されていません*4が、CNNにおいて入力に近い層は表現抽出の役割を担っていると言われるので、方策関数と価値関数でネットワークを共有した方が学習が安定するだろう、という一般論的な考察ができます。
A3Cのロス関数
共有型ネットワークでは当然ロスも共有なので、方策ロスと価値ロスをまとめて、”-1×(アドバンテージ方策勾配項 + 方策エントロピーボーナスH(π) ) + 価値関数ロス” としたものがロス関数となります。※方策勾配と方策エントロピーは最大化したいので×-1しています。
ここで突然出てきた方策エントロピーボーナスH(π)とは方策のランダムさの指標です。ランダム性の高い方策(=エントロピーの大きい方策)にボーナスを与えることで早すぎる方策の収束による局所解への停滞を防ぐ効果があります。カテゴリ分布の方策エントロピーは下式で計算します。
例えば、[π(a1|s), π(a2|s), π(a3|s)] = [0.1, 0.1, 0.8 ] の方策と [π(a1|s), π(a2|s), π(a3|s)] = [0.3, 0.3, 0.4 ] の方策であれば後者がよりエントロピーの大きい方策となります。*5
価値関数ロスについてはシンプルに1step returnを使って と計算してもよいのですが、アドバンテージ方策勾配法のためにn-step returnを計算済みなので、n-step return と現在状態価値
の二乗誤差、つまりAdvantageの二乗を価値関数のロスとします。
アドバンテージ方策勾配項については上述した通りです。ただし方策勾配においてアドバンテージは定数項の扱いなのでtf.stop_gradientして勾配が流れないようにする必要があることにだけ注意してください。
CartPole-v1での学習結果

次:A2C
付録:Agentクラスの実装
実装全文はgithubへ: https://github.com/horoiwa/deep_reinforcement_learning_gallery