LLMチューニングのための強化学習②:GSPO(Group Sequence Policy Optimization)
Qwen3の推論強化チューニング手法であるGSPO(Group Sequence Policy Optimization)について考えたことをまとめます。
過去記事:
horomary.hatenablog.com
GSPO: 学習安定性が向上したGRPO
Group Sequence Policy Optimization (GSPO) は、LLM向け強化学習手法であるGRPO(Group Relative Policy Optimization)に改良を行い、大幅な学習安定性向上に成功した手法です 。

特に、PPOやGRPOなどの従来手法では学習が不安定になりがちであったMoE(Mixture-of-Experts)モデルでの安定性向上が顕著であり、大規模MoEであるQwen3の性能向上に大きく貢献したとされています。
シーケンスレベル重点サンプリングによる分布補正ノイズの低減
GSPOはGRPOの改良手法であり、そのアルゴリズム的差分はアドバンテージ(A)の重点サンプリングをトークンレベルからシーケンス(応答文全体)レベルへと変更したという一点のみです 。ごくわずかな変更でありながら、この改良は重点サンプリングによる分布補正ノイズを低減する効果があるため学習安定性の向上が期待できるとされています。

前提:重点サンプリングとは?
重点サンプリング法とは関心のある確率分布(ターゲット分布)からのサンプルを直接得ることが難しい場合に、異なる分布(提案分布)から得られたサンプルを用いてその分布の特性を評価する手法です。

なお、LLM向けの強化学習において重点サンプリングは本来オンポリシー手法である方策勾配法を近似的にオフポリシー化するために使われます。オンポリシー手法である方策勾配法では本来は1回の勾配更新ごとにすべての学習データを破棄する必要がありますが、オフポリシー化することで古いデータの再利用が可能となるため、全体の計算コストを大幅に削減できます。
ここで、重点サンプリングによる分布補正の精度は提案分布のサンプル数に大きく依存することに注意が必要です。以下のグラフはGemini君にサンプル数によって分布補正の推定精度がどのように変化するかをシミュレーションを行い、プロットしてもらったものです。


チャートから、サンプル数の増加に伴って推定ノイズ(RMSE)が減少することが分かります。このサンプル数による分布補正の精度差こそがPPO/GRPOと比較してGSPOの学習安定性が高いとされている理由の一つです。
サンプル数効果による分布補正の推定精度向上
GSPOがGRPOよりも良好な学習安定性を持つ理由として、論文*1では「トークンレベルでは重点サンプリングの推定精度において重要となる、多数のサンプルによる平均化効果が得られないため*2」であると考察されています。
具体的には、GRPOの目的関数における重要度比 (importance ratio)は、以下のようにトークンレベルで定義されています。


は質問文、
は出力済みの回答文であるので、これはLLMの次トークン予測分布を提案分布として重点サンプリングを行っているということになります。
しかし、この場合トークンごとに提案分布が受け取るコンテクストが異なるために次トークン予測分布もトークンごとに異なるものとなり、これは各トークンごとに異なる提案分布でN=1の重点サンプリングを行っている、とも解釈できます。すなわち重点サンプリングの推定精度で重要となる、複数サンプルでの平均化効果が得られないため分布補正に高分散ノイズが導入されると考えられます。
一方で、GSPOの目的関数における重要度比 は以下のようにシーケンスレベルで定義されています。(
の役割については後述)


この場合、提案分布が受け取るコンテクストがすべてのシーケンスにおいて質問文のみになっていることから、これは同じ提案分布から得られた複数のサンプルで重点サンプリングを行っていると解釈できるため、平均化効果による分布補正の精度向上が期待できます。
大規模MoEモデルの学習安定化効果
重点サンプリングにおける推定ノイズを低減するためには、前述したようにサンプル数が重要であるというのに加えて、提案分布とターゲット分布が十分に近いこと(=重要度比 が1に近い)というのもまた重要です。

とくに大規模MoEモデルにおいては、エキスパートの活性化比率がわずかに変化しただけで次トークン予測分布が劇的に変化し、「重要度比 が十分に近い」という重点サンプリングの前提がしばしば崩壊するために、従来のトークンレベル手法(PPOやGRPOなど)での推論強化トレーニングは深刻な不安定性の問題を抱えていました。

この問題への対症療法として、Qwenチームは従来Routing Replay という訓練戦略を採用していたとのことです。これは古い方策 で活性化されたエキスパート構成をキャッシュしておき、重要度比の計算の際には古い方策πθold と現在方策πθでエキスパートの活性化構成を強制的に同じにするという方法でトークンレベル重要度比の急激な変化を抑制するトリックです。
一方、エキスパートの活性化構成が変化してもセンテンスレベルでの尤度であればそれほど大きく変化しないため、シーケンスレベルでの重点サンプリングを行うGSPOではRouting Replayのような死ぬほど面倒くさいトリック無しでも安定した訓練が実現できることが示されています。
幾何平均による爆発防止トリック
ところで、GSPOの重要度比には がくっついていることにお気づきでしょうか。全体をステップ長|y|で乗根しているこの計算は幾何平均を求めることに相当し、これにより系列全体の確率比を1ステップあたりの平均的な確率比に正規化(ならす)することができます。
たとえば、トークン当たりの重要度比 が仮に1.1だったとしても、300トークンで構成される文章となるとシーケンスレベルでの重要度比は1.1300 ≒ 2.6兆 と容易に値が爆発するため、シーケンスレベルでの重点サンプリングを行う際にはこのような正規化の工夫が必須となります。なお、PPOのクリッピングの仕組みは幾何平均で正規化してもなお重要度比の値が大きく/小さくなりすぎたときの安全装置として機能します。

3.1 Off-Policy Evaluation via Importance Sampling
シーケンス(トラジェクトリ)レベルの重点サンプリングについて、どのような困難やアプローチがあるのかについてはオフライン強化学習の分野で広く研究されてきたトピックのため、興味があったら上記のチュートリアル論文を読んでみると楽しいかもしれません。
メモ:理論的に厳密な重点サンプリング
※これはGSPO論文では言及されていない個人的な考察であることにご注意ください*3
GSPOの安定化理由について、論文では「トークンレベルでは重点サンプリングの推定精度において重要な多数サンプルによる平均化効果が得られないため」と述べられていたのですが、個人的にはPPO(GRPO)は"近似的"な重点サンプリングを行っているのに対して、GSPOはより理論的に厳密な重点サンプリングを行っているというのも安定性の理由としてあるんじゃないかと思ったのでメモを残します。
まず、GRPOのベース手法となっているPPO/TRPOが行っているトークンレベルの重点サンプリングはそもそも近似的なアプローチであり、より厳密にはGSPOのようにシーケンスレベルで重点サンプリングを行うのが理論的には正しいはずです。

具体的に何かというと、PPOでは状態分布 が方策の更新前後で不変であると大胆に近似することによりトークンレベルでの重点サンプリングを可能にしているわけです。

近似的なため重点サンプリング自体の精度は落ちるはずですが、それでもシーケンス(トラジェクトリ)の途中で頻繁に報酬シグナルが発生する一般的な強化学習環境であれば、価値関数(クリティック)のトークンレベルでの学習が迅速に進み、アドバンテージ推定値の分散低減効果を強力に発揮するためトータルではメリットの方が大きくなるのではないかと思います。

しかし、結果報酬モデル(Outcome Reward Model)を用いた言語モデルの推論強化チューニングでは、報酬シグナルがシーケンスの最後にしか発生しないので価値関数の学習がなかなか進まずアドバンテージ推定値の分散低減効果が得られにくいため、重点サンプリングを近似したデメリットの方が大きく出ているのではないか、というのが私の解釈です*4。
GSPO-token: トークン単位で評価可能なバリアント
GSPOではシーケンス単位でアドバンテージの重点サンプリングを行うため、同じセンテンス内であればすべてのトークンでが等しくなります。直感的には、細かい単語のチョイスよりも回答の全体観を重視するアプローチであると言えるでしょう。
しかし、このアプローチは例えばマルチターン強化学習のように報酬が複数ステップに分割して発生するタスクへの適用には不都合が生じます(数学証明タスクで大問が小問1,2に分かれている場合とか)。このようなシナリオに対応するため、GSPO-tokenというトークン粒度でのアドバンテージ調整に対応したGSPOのバリアント手法を同時に提案しています。

サイゼリヤの間違い探しのような難易度ですが、よく見ると重要度比が →
、アドバンテージが
→
と変更されておりセンテンス(=i)だけでなくトークン位置(=t)を考慮できるようになっていることが分かります。
ただし、

は1であるので、結局のところ数値的には重要度比 =
であり、ここではstop_gradientを利用したトリックにより勾配の流れ方だけを変えていることに注意が必要です。シーケンス単位の重点サンプリングでアドバンテージを重みづけしたうえで、さらにそれをトークンごとに按分するようなイメージでしょうか。
勾配を見たほうがやっていることが分かりやすいかもしれません。

うーん、ナイーブなオフライン方策勾配法との区別がつかない...。
参考資料
*1:論文というよりはテクニカルレポートかも
*2:GRPO applies the importance weight πθ (yi,t |x,yi,<t )πθold (yi,t |x,yi,<t ) at each token position t. Since this weight is based on a single sample yi,t from each next-token distribution πθold (·|x, yi,<t), it fails to perform the intended distribution-correction role. Instead, it introduces high-variance noise into the training 2gradients, which accumulates over long sequences and is exacerbated by the clipping mechanism. We have empirically observed that this can lead to model collapse that is often irreversible.
*3:変なこと言ってたらコメントで教えてね!
Jax/Flax NNXで実装する深層強化学習②:PPOによるロボット犬の歩行学習
MuJoCo-XLA (MJX)環境にてロボット犬(UnitreeGo1)の歩行学習のためにPPOをFlax NNXで実装します。
- Jax/Flax NNXとは
- Massively Parallel Reinforcement Learning (大規模並列強化学習)
- 大規模並列強化学習のためのプラットフォーム
- Unitree社のロボット犬
- PPO(Proximal Policy Optimization)
- Sim2Realギャップ問題
- ロボット犬向けPPOの実装
- トレーニング結果
- 次:GRPO

Jax/Flax NNXとは
Flax NNXとはGoogle Deepmindの開発するJAXベースの深層学習ライブラリFlaxの新APIです。2020年リリースの旧API(Flax Linen)では関数型の思想で厳密に状態管理するためコードが煩雑になりがちというつらさがあったのに対して、2024年にリリースされた新API(Flax NNX)では状態管理の透過性を一定あきらめることでPytorchライクなシンプルな記法でコードを記述することが可能となりました。
シェアとしては依然PytorchとTensorflowの2強状態が続いていますが、例えばLLMのRLHF/RLVRのような高計算負荷ユースケースでは分散学習とパフォーマンスに強みを持つJAX/Flaxは有力な選択肢であるため、新APIで他フレームワークユーザーが利用しやすくなったことにより今後Flax活用の裾野が広がることが期待できます。
詳細は前記事を参照:
horomary.hatenablog.com
Massively Parallel Reinforcement Learning (大規模並列強化学習)
過去10年間の深層強化学習研究から得られた一つの経験則として、『高度な推論を必要としないタスクであれば膨大な試行回数を重ねることで、そのほとんどは強化学習で解決可能だ』ということが分かってきました。とはいっても、現実環境で無数の試行を行うことはコスト観点から多くの場合に実現困難ですが、しかし、信頼できるシミュレータが利用可能な環境であれば試行回数でのゴリ押しも実現可能な選択肢となります。
とくにロボティクス分野においては、GPU上で大規模並列実行が可能な物理エンジンを活用し、膨大な試行回数でゴリ押し強化学習を行うMassively Parallel Reinforcement Learning というアプローチが近年のトレンドの一つとなっているようです。

大規模並列強化学習のためのプラットフォーム
Massively Parallel Reinforcement Learning (大規模並列強化学習)のためのロボティクス向け物理エンジンとして、代表的にはMujoco XLA (MJX)、NVIDIA Isaac Lab、Genesis が利用可能です。本稿ではpipのみで完結するセットアップの手軽さとJAXとの相性の良さからMuJoCo XLA (MJX)を採用しますが、それぞれ異なる特長があるので目的に応じて使い分けるのがよいでしょう。
MuJoCo XLA(MJX): アルゴリズム研究者向け
MuJoCo XLA (MJX)は、連続値向け強化学習アルゴリズムの標準ベンチマークとして長く使われているMujoco物理エンジンをGoogle DeepmindがJAX(XLA)で再実装したものであり、要するにGPU/TPU上で超高速に並列実行できるよう再設計されたMuJoCoと言えます。強化学習ベンチマークとしての実績が豊富、かつpipインストールのみで完結する環境構築の容易さから、強化学習アルゴリズムの開発・検証用途として最適な選択肢でしょう。
NVIDIA Isaac Lab: ロボット開発者向け
Isaac LabはNVIDIAの提供するロボット開発のための統合プラットフォーム*1であり、PhysXエンジンによる高速・高忠実度の物理シミュレーションとフォトリアリスティックなレンダリングを強みとしています。自作ロボットを用いてシミュレータ上で獲得した動作を実世界へ転移するSim2Realワークフローの簡易化を志向していることから、ハードウェア寄りのロボット開発者に最適な選択肢でしょう。 ただし動作要件が厳しいので環境構築にハマると死ぬ*2。

Genesis: 先進的な取り組みに対応
Genesisはtaichiエンジンに支えられた圧倒的なパフォーマンスに加え、従来の剛体物理シミュレータでは扱いにくいソフトロボットや流体環境への対応、生成AIとの組み合わせなど様々な先進的な取り組みを提供するプラットフォームとなっています。Genesisでしかできないことをやりたい場合はもちろん、pytorchユーザーならセットアップが簡単っぽいのでこの種のシミュレータをとりあえず試してみたい、というような際にもお勧めできるかと思います。

Unitree社のロボット犬
本稿では、訓練対象のロボット犬としてUnitree Robotics社のGo1モデルを使用します。
以前からunitree社のロボットは低価格ながら高性能として定評がありましたが、近年は生成AIブームに乗ったことで同社は汎用ロボット市場においてますます存在感を強めています。とくにロボット犬シリーズについてはイケてるスタートアップや大企業のAÌ部門でDX感を演出する狛犬としての採用も広がっているようです。(この場合、だいたいVRヘッドセットと3Dプリンターも一緒に観測される)

Unitree社製ロボットのMujoco向けモデルは、今回使用するGo1だけでなくさらに新型のGo2やヒト型のG1などまでmujoco_menagerieから一通り利用可能です。
PPO(Proximal Policy Optimization)
※画像はJohn Schulmanの講義資料より
強化学習には様々なアルゴリズムがありますが、連続値コントロールタスクにおいてはサンプル効率重視の場合はSAC(Soft Actor Critic)、そうでない場合はPPO(Proximal Policy Optimization)が選ばれることが多いようです*3。今回は大規模並列シミュレータが利用可能につきサンプル効率を気にする必要が全くないのでPPOを採用します。
PPOはTRPOの後継手法という位置づけで提案された手法です。方策勾配定理は報酬を最大化するための方策パラメータの勾配方向を教えてくれますが、適切な更新サイズについては何も教えてくれないためしばしば学習が不安定化します。そこで、TRPOでは現在方策πθとデータ収集方策πθ_oldのKLダイバージェンスを制約項として与えることで極端なパラメータ更新を回避します*4。


TRPOは高性能であるものの、毎回の勾配更新ごとにラグランジュ乗数法で制約付き最適化問題をまじめに解くので計算量が非常に大きく、大規模ニューラルネットワークに適用することができません。この問題の解決のためにシンプル化されたTRPOとして提案された後継手法がPPOです。PPOでは方策更新が大きくなりすぎた場合にはクリップしてしまうことで暗黙的なKL制約を与えるというトリックにより、計算量を大幅に減らしつつTRPOの目的である極端なパラメータ更新防止を実現します。

なお、性能そのものについてはPPOとTRPOでほとんど差がないことが検証論文にて報告されています。論文のベンチマークスコア上ではPPOはTRPOより高い性能を示しますが、これは『実装レベルの細かいテクニック』によって得られたものであり、コアアルゴリズムに由来するものではない、とのことです。
[1709.06560] Deep Reinforcement Learning that Matters
[2006.05990] What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
『実装レベルの細かいテクニック』とは、例えば「確率方策のモデル化方法」「観測のRunningStatsによる正規化」、「パラメータの初期化スキーム」などです。本稿のPPOではこのようなテクニックまで主要なものは実装していきます。
Sim2Realギャップ問題
どんなに精密な物理シミュレーターであっても現実環境とシミュレーション環境における一定の乖離は避けられず、シミュレーション環境内での強化学習で訓練したロボットをそのまま現実環境に持っていってもうまく動作しないという「Sim2Realギャップ」がしばしば問題となります。
Sim2Realギャップ問題は盛んに研究されているトピックであり、さまざまな軽減アプローチがあるのですが、本稿のPPOではドメインランダム化と非対称Actor-Criticの2つのテクニックのみ採用しました。
ドメインランダム化(Domain Randomization)
ロボットの関節動作の滑らかさや床面の摩擦係数/反発係数などは動作獲得において重要なパラメータではあるものの、そもそも個体差もあるためにシミュレーションと現実を完全に一致させることが困難です。そこで、シミュレーション環境でモデルを学習させる際にこれらのパラメータをランダムに変化させることで多様な条件下で動作する頑健性を獲得させよう、というのがドメインランダム化という手法です。これによりシミュレーションで学習した動作を現実環境へスムーズに転移させることが可能となります。
非対称Actor-Critic
非対称アクタークリティックでは、クリティック(価値関数)がアクター(方策関数)よりも多くの情報や特権的な情報(privileged information)を利用して学習します。この「特権的な情報」とは、通常アクターが現実世界で利用できない、シミュレーション環境でしか得られない情報(例:物体までの正確な距離、隠れた物体の位置など)です。特権情報の利用により、クリティックがより正確な価値評価を学習できるため、アクターの訓練を効率的にガイドできるようになります。
クリティックは方策の訓練時にしか使われないため、現実環境で追加訓練をしない場合には特権情報の利用は問題になりません。とはいえ、シミュレーション環境での動作獲得後、現実環境でも微調整のために追加学習を行いたいというのもよくある状況です。このような場合は、Teacher-Student学習により、特権情報を予測するというアプローチをとることができます。

ロボット犬向けPPOの実装
ようやく本題。Mujoco-XLA (MJX)環境にてロボット犬(UnitreeGo1)の歩行学習のためにPPOをFlax NNXで実装します。なお、本稿のPPOをbraxのPPO実装をベースとして、見通しの良さを最優先にFlax NNXで再実装したものであることにご留意ください。
実装全文:
github.com
環境構築
Installation — JAX documentation
CUDA未導入のクリーンな環境であればpipインストールで環境構築が完了します。ただし、NVIDIA GPU driverの事前インストールのみ必要です。
pip install "jax[cuda12]" flax mujoco-mjx playground
トレーニングループの実装
基本的なトレーニングループです。OpenAI Gym形式に慣れている場合はそれほど違和感のないコードになっているはずですが、state内にすべての情報(obs, reward, doneなど)が格納されていることに注意が必要です。
また、環境(env)はjax.vmapによって並列化(ベクトル化)されているため、state にはNUM_ENVS = 4096環境分のstate情報が含まれています。
環境の大規模並列化
MuJoCo XLAのラッパーライブラリであるMuJoCo Playground(mujoco_playground)を使用して環境を呼び出します。MuJoCo PlaygroundはMJXのためのgymといった感じで、環境の並列化やエピソードの自動リセットなどさまざまな便利機能を提供します。
なお、wrapperを使わない場合には、 step_fn = jax.jit(jax.vmap(env.step)) とすれば環境をベクトル化することが可能です。MJXがJAXで実装されているからこそのお手軽な並列化であり、さらにvmapをpmapに変更することで複数GPUでの並列化も簡単に実装可能です。
Squashed Gaussian方策(TanhNomal方策)
PPOの方策関数は確率分布であれば何でもよいので、最もナイーブには観測を入力として正規分布のパラメータ(μ, σ)を出力するガウス方策を使用することができます。しかしロボティクス向けの環境ではアームの角度やモーターのトルクなど、行動が有限な範囲に制限されていることがよくあります。一方で単純なガウス方策は無限の範囲を持つためそのまま使うと学習が不安定になることがあります。
このような有限範囲における連続値コントロール環境では、正規分布をTanhで押しつぶしたSquashed Gaussian方策の採用が推奨されます。

なお、SquashedGaussian方策の確率密度は確率変数の変数変換により、以下のように計算できます。

数式的にはこれでいいのですが、ただ右辺第二項が数値的に不安定(桁落ちでln0が発生しうる)なため、実装上はさらに展開して計算します。

まとめると以下のような実装になります。
なお、連続値コントロールだとactivationにもtanhを使うのがよいとされていますが、元ネタにしたbraxのPPO実装に倣いsiluを採用しました。
観測の正規化
大変地味ながら性能に与える影響が極めて大きいのがRunningStatsによる観測情報の正規化です。バッチノーマライゼーションなどと同様に、訓練中にデータの平均と分散を記録し、その情報を使って推論時にデータを正規化することで学習を安定させます。やるべきこと自体はシンプルなのですが、これをナイーブに実装すると分散の算出のために全データ保持が必要となるため、メモリへの負荷が大変なことになります。
このため RunningStatsではWelford's online algorithm (Wikipedia)というメモリ効率のよい実装を行っています。
GAE(Generalized Advantage Estimation)
アドバンテージ関数としてはGAE(Generalized Advantage Estimation)を採用します。GAEはn-step returnにもとづくアドバンテージ関数の一般化という感じで、ハイパラであるλを0に設定した場合は1ステップリターン、1に設定した場合はモンテカルロリターンに相当します。

代理目的関数の最大化(ロス関数)
これは論文通りに実装するだけなので簡単。

アドバンテージのミニバッチ内正規化とエントロピーボーナスはあってもなくてもさほど性能に影響ないらしいですがせっかくなので実装しました。
トレーニング結果
RTX4080でトータル2億(200M)環境ステップのトレーニングを実行。データ収集は秒速50万環境ステップくらいと十分に高速であるものの、方策更新がボトルネックになるので結局はトータル1時間くらいかかりました。それでも十分速いのでヨシ。
自作PPOでGo1君の走行にようやく成功。初期実装では立つのがやっとだったが、「エントロピーボーナス付きTanhNormal方策」「SiLU活性化関数」「RunningStatsによる観測の正規化」で大幅に性能が向上した。やはり連続値コントロールは難しい... pic.twitter.com/0fP06tIaP0
— めんだこ (@horromary) August 7, 2025
次:GRPO
そのうち
Jax/Flax NNXで実装する深層強化学習①:DQNによるAtari/Breakout攻略
Pytorchスタイルになって書きやすくなったFlaxの新API「NNX」の使用感の確認のため、ALE/Breakout(ブロック崩し)向けにDQNを実装しました。
Jaxとは?
JAXとはGoogleによって開発されている高性能数値計算ライブラリであり、「①NumPyの使いやすさ + ②柔軟な自動微分 + ③マルチCPU/GPU/TPUでの分散並列コンピューティング」をシンプルな記述で実現します。
①Numpyの使いやすさ
JAXはNumpyスタイルのAPIを提供するため、NumPyに慣れている人なら非常に簡単に使い始めることができます。。

②柔軟な自動微分
JAXであればNumPyでは不可能な関数の自動微分が可能です。もちろんTensorflowやPytorchでも自動微分は可能ですが、TensorFlowのtf.GradientTapeやPyTorchのloss.backward()が計算グラフを構築し、そのグラフを遡って勾配を計算するのに対し、JAXのgradは「関数を受け取り、その関数の勾配を計算する新しい関数を返す」という純粋な関数変換として動作するため、シンプルかつ柔軟な記述が可能となります。

例えば、jaxでは高階微分を非常にシンプルに記述できます。深層学習ではあまり役立ちません*1が、物理シミュレーションや高度な最適化手法の研究においては強力な記法です。

③マルチCPU/GPU/TPUでの分散並列コンピューティング
JAXは大規模分散並列コンピューティングを前提として設計されているため、マルチデバイスの恩恵を容易に享受することができます。
最も簡単には関数を@jax.jitでラップしてしまえば、あとはXLAコンパイラが「内部処理をどのように分割(パーティション化)するか」「デバイス間の通信をどのようにコンパイルするか」を自動的に解決し並列処理を実現してくれます。
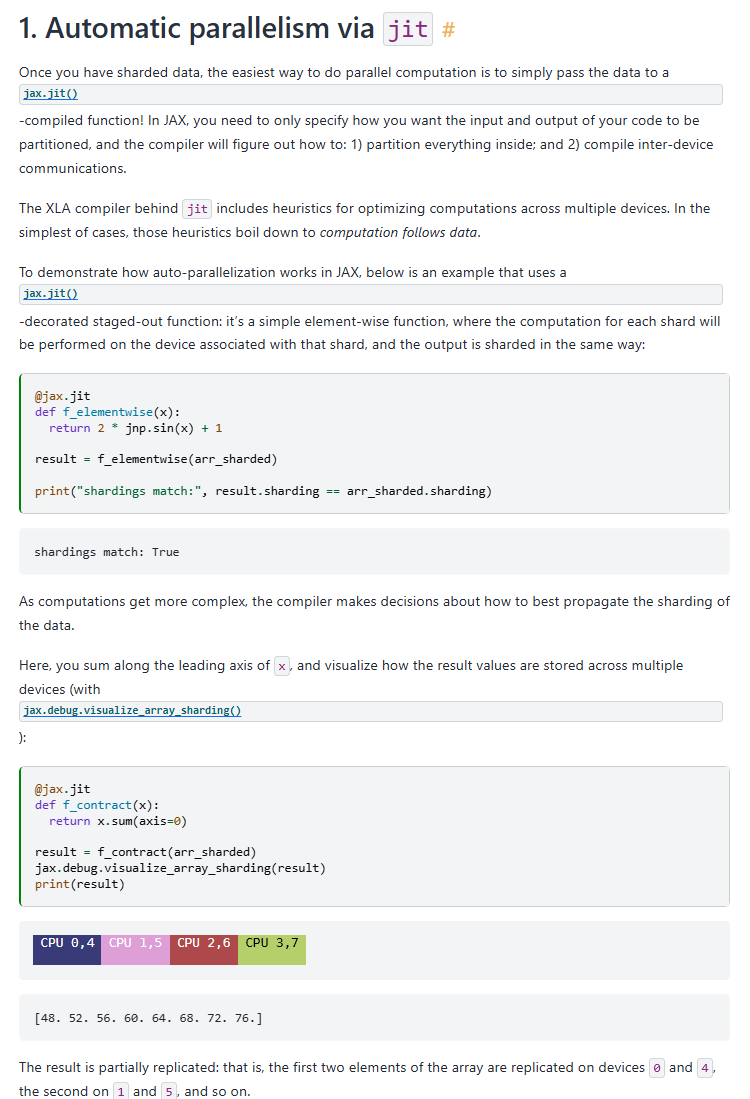
もちろん上記のような自動並列化だけでなく明示的な分割による高度な並列化を行うことも可能です。たとえば以下のチュートリアルではデータパラレル(4分割)とモデルパラレル(2分割)を組み合わせた複雑な分散処理を比較的シンプルな記述で実現しています。
Distributed arrays and automatic parallelization — JAX documentation
Flax NNXとは?
jaxは「Tensorflow vs Pytorch vs Jax」みたいなタイトルでよくtfやtorchと比較されていますが、jaxはあくまで自動微分つき数値演算ライブラリであり深層学習フレームワークではありません。ディープラーニングをやりたい場合、基本的にはjaxをベースとした深層学習フレームワークであるFlaxを使うこととなります
PyTorchスタイルになったFlaxの新しいAPI
Flaxは旧Google research(現Google Deepmind)によって2020年にリリースされたjaxベースの深層学習フレームワークです。
FlaxはJaxを開発するGoogle Research発という背景からエコシステムにおける深層学習フレームワークの大本命となるはずでした。しかし、旧API (Flax Linen API)では関数型の思想があまりにも強く書き味の癖が強かったため他フレームワークからのユーザー流入を獲得できずにいたため、大幅なテコ入れとして2024年にFlaxの新たなAPIであるNNXがリリースされました。Flax NNXという名前からも明らかですが、torch.nn スタイルの記法を踏襲しているため、Pytorchユーザーやtensorflowのsubclassing API ユーザーであれば非常に簡単に使い始めることができます。

jaxエコシステムにおける有力な深層学習フレームワークとして他にDeepMindのhaikuがありましたが、Google Deepmindの発足に伴って機能追加を停止しFlaxを推奨化したことにより、2025年現在ではjaxでディープラーニングするならほぼFlax一択という状況になったかと思います。
余談: Flax NXXまでの経緯
前述のとおり、JAXは数値演算ライブラリであり深層学習フレームワークではありません。
PyTorchやTensorFlowが「モデルの作り方 (nn.Module)」や「訓練ループの作法」まで提供する「全部入り」なのに対し、JAXは強力な計算部品を提供するだけで、モデルをどう作りどう管理するかは完全にユーザーに委ねています。その結果、深層学習フレームワークが乱立する状況が最近まで続いていました。
Flax (Google research):
パラメータは外部の辞書で管理。状態管理も明示的で関数型の思想に忠実だがコーディングがヤバいくらい煩雑*2。Haiku (Deepmind):
PyTorchのようなオブジェクト指向でパラメータ管理を暗黙的に行う。tf sonnetのjax版といった感じで書きやすい。Equinox (Patrick Kidger氏による個人開発):
モデル自体がパラメータを含むPyTreeで最もJAXのデータ構造に忠実。書きやすい。
とくにFlaxとHaikuの内ゲバが完全にjax普及の足を引っ張ってた感があります。最近Google ResearchとDeepMindが統合されてGoogle Deepmindになったことでようやくカオス状態から脱出したため、安心してFlaxを使っていけるようになりました。
なぜ強化学習にJax/Flaxを使うのか?
強化学習のコンテクストにおいてJaxを導入するモチベーションは2つあります。
大規模言語モデル向け強化学習
近年の発展著しい「大規模言語モデルの強化学習チューニング」においては、1GPUに乗り切らない巨大なモデルを複数のGPUに分割して訓練する高度な分散並列コンピューティングが必要となります。このような分散並列コンピューティングはPytorchやTensorflowにもAPIがあるものの、(偏見だけど)明らかに後付けであり無理している感が否めません。一方で後発ライブラリであるjaxは前述のとおり高度な分散並列処理を比較的シンプルな記述で実装することができます。これはLLM向けの強化学習において非常に重要な特性です。
参考: 分散学習基礎講座
フィジカルAI(AIロボティクス)
LLMと同様に近年発展著しい「フィジカルAI」(AIの物理世界への干渉を可能とする試み)、大雑把に言うとAIロボティクス分野では、しばしば何らかの物理シミュレーションを伴います。ここで、物理シミュレーションをJaxで実装することによりm環境そのものが微分可能になり報酬シグナルの逆伝播に基づいて方策ネットワークを直接最適化することができます。
「映像も物理も、微分可能になるとすごいことが起きる」ということの意味を文系にもわかるように説明しようと試みる – WirelessWire News
微分可能なシミュレータ上での方策最適化 - Preferred Networks Research & Development
とはいえ、微分可能プログラミングは正直なところ最近は盛り下がっている感があるので今後に期待。 まあシミュレータ使わなかったとしても、ロボットだとニューラルネットとは別に勾配ベースの最適化計算がいろいろ走る気がするので、GPUで容易に大規模高速微分ができるJaxは採用メリットあるような気がする(ロボットは門外漢なので適当)。
DQN(Deep-Q-Network)の実装
前置きが長くなってしまいましたがFlaxの新しいAPIであるFlax NNXの使用感を確かめるためDQNを実装します。 アルゴリズムの詳細解説はしないので、The Deep Q-Learning Algorithm - Hugging Face Deep RL Courseなどを参照ください。
実装全文:
https://github.com/horoiwa/rl-with-flax-nnx/blob/main/src/dqn.pygithub.com
DQNとは
DeepMindのDQN(2013)とは古典強化学習アルゴリズムのQ学習に深層学習を導入することにより、Atari環境(レトロゲーム環境)において、ゲーム画面のみを入力としたアルゴリズムとしては初めて人間レベルのパフォーマンスを達成し、「深層強化学習」という分野を切り開いたエポックメイキングな手法です。
深層強化学習を学ぶという観点では重要な手法ではあるものの、AdamやらBatchNormalizationやらの深層学習安定化テクニックが普及する前の手法ゆえに、論文通りに実装すると学習がかなり不安定かつ遅いです。このため今回はDQN論文に忠実に実装していないことに留意ください。
Jax(GPU版)/Flaxのインストール
PytorchでもTensorflowでもGPU環境の初期構築には苦労する印象ですが、GPU版Jaxは「最新のNVIDIA GPU Driverがインストール済み」かつ「CUDAが未インストール」の「Linux/WSL2環境」であれば pip install --upgrade "jax[cuda12] flax orbax" だけでインストール可能です。

jax.devices()でCudaDeviceが表示されればOK。
>>> import jax >>> jax.devices() [CudaDevice(id=0)]
NVIDIA GPU Driverについて、WSL2の場合はホストWindows側にインストールされていればOKっぽい。Linuxの場合は頑張って自力インストールしましょう。私はめんどくさかったのでGCPでNVIDIA GPUドライバプリインストール済みUbuntuイメージ(Ubuntu 24.04 LTS Accelerated)を使ってスポットVMを作成しました。
令和最新版:Atari環境の構築
次に強化学習の標準ベンチマークとして使用されているAtari(Arcade Learning Environment: ALE)環境を構築します。

以前までは、OpenAI GymからAtari環境を利用していたのですが、紆余曲折ありOpenAI Gymは更新終了したため、引継ぎ先であるGymnasiumをインストールします。
>>> pip install "gymnasium[atari,other]" opencv-python
NOTE: gymnasium[accept-rom-license] は最新バージョンでは不要*3。
NOTE: 依存解決がうまくいっていないっぽく、opencv-pythonを明示的にインストールしないとUbuntu環境ではlibGL.so.1: cannot open shared object file: No such file or directoryというエラーが発生。上記のopencv直接インストールでもダメならapt update && apt install libgl1。
Gymnasiumは強力なWrapperを揃えており、Atari環境向けには以下のようにWrapperをネストして適用すると前処理(リスケールとかグレスケ化とか)や一定エピソードごとの動画記録などを自動でやってくれて便利。
Environments - ALE Documentation
List of Wrappers - Gymnasium Documentation
フレームスタックWrapperはPytorchのスタイルに従ってChannel First形式(CHW)でStackする。JaxとTensorflowはChannel Lastなので継承してHWCに修正していることに留意。
NOTE: import ale_py をimport gymnasium as gymより先に記述しないと「ROMが見つからない!!」と怒られることがある。そのうち修正されるはず。
モデルの定義
flax.nnxでDQN-CNNを定義したのが以下のコード。Pytorchとの間違い探しみたいですが、わかりやすい違いはすべてのレイヤーが乱数シードrngs: nnx.Rngsを引数として要求する点でしょう。ちょっと面倒かもですが、実験の再現性が確実に保証されるメリットは大きいです((厳密にやるならトレーニングループ内のε-greedy選択でも標準ライブラリ(random.random)を使うのではなくjax.randomで乱数生成すべき))。
ロスの定義

ロスの定義方法についてはjaxの関数型プログラミングの思想が反映されているためPytorchとはだいぶ雰囲気が異なります。
具体的には勾配計算の対象となるnnx.Moduleだけを引数にとるロス関数(loss_fn)を定義し、これをnnx.value_and_gradでラップすると戻り値としてロスと勾配を返す関数となります。なお、nnx.Module以外に必要なデータは関数の外側から渡す必要があるため高階関数としてtrain_stepを定義します。好みが分かれるかもですが、私はこの記法わかりやすくて好きですよ。
加えて、とても地味ながら特筆すべきは以下の一行。
q_values_selected = q_values[jnp.arange(len(data["actions"])), data["actions"]]
そうです、jax/flaxではnumpyとほぼ同等のFancy Indexingが利用可能なため、tf.gather_ndとかtorch.gatherによるパズルを解かなくてよいのです。これはありがたい。
トレーニングループの実装
サンプル収集しながら4ステップ(16フレーム)ごとにネットワーク更新するだけ。収集したサンプルはlz4で圧縮してReplayBufferに保持するようにしてあるので数GBのRAMで問題なく実行可能です。
ここで、jaxの関数型スタイルの良さをtarget_networkとonline_networkの重み同期処理から垣間見ることができます。
"""Copy weights from online network to target network."""
_graphdef, _state = nnx.split(online_network)
nnx.update(target_network, _state)
nnx.splitにより、nnx.Moduleをグラフ定義(_graphdef)と内部状態(_state)に分割することができるため、あとは取り出した内部状態でtarget_networkを上書きすれば2つのネットワークが完全に同期されます。
学習結果
GCPのvCPU:2 RAM:13GB GPU: T4のVMで12時間くらいかけて2Mステップの学習を行いました。
2Mステップの学習でも最大300点くらいとれており、DQN論文では50Mステップ*4学習して400点くらいであることから、問題なく再現できていると判断できます。

Jax/Flax.NNXでDQNを実装。NNXではPytorchの書き味とJaxのパフォーマンス&スケーラビリティが両立されてていい感じ pic.twitter.com/CLGSP6w2FB
— めんだこ (@horromary) July 5, 2025
ちなみに参考まで、一般的な教師あり学習とは異なり深層強化学習(Q学習)では獲得報酬の増大に伴ってlossがだんだん大きくなっていきます。

次:PPO
*1:深層学習はパラメータ多すぎて二次以上の微分は計算量的に無理なため
*2:本質的に状態の塊であるDeepLearningで関数型原理主義をやるとコードがクッソ煩雑になるのは不可避なのである
*3:We have remove pip install "gymnasium[accept-rom-license]" as ale-py>=0.9 now comes packaged with the roms meaning that users don't need to install the atari roms separately with autoroms.
Gymnasium Release Notes - Gymnasium Documentation
*4:frameskip=4設定なので実フレームでは200Mステップとなる
サンプル効率強化学習②:EfficientZeroV2
サンプル効率に優れたMuZeroの後継手法EfficientZeroV2を実装。
- 強化学習実用のカギはサンプル効率
- 世界モデルベース強化学習とは
- 前提手法 MuZero: 潜在変数空間上での木探索
- EfficientZeroV2:MuZero派生の全部盛り
- EfficientZeroV2の実装
- 学習結果
- 次:??
関連記事:
サンプル効率強化学習①:Bigger, Better, Fasterの実装 - どこから見てもメンダコ
世界モデルベース強化学習①: DreamerV2の実装 - どこから見てもメンダコ
MuZeroの実装解説(for Breakout) - どこから見てもメンダコ
強化学習実用のカギはサンプル効率
DeepMindのDQNが登場してからわずか10年間で深層強化学習アルゴリズムは大きく発展した一方で、実世界応用の成功例は一部の例外を除きまだまだ限られている。
この原因の一つとして強化学習のサンプル効率が極めて劣悪であること、すなわち強化学習が性能を発揮するためには実環境において膨大な試行錯誤が必要であることが挙げられる。例えば、ある特定のタスクを学習させるだけで現実世界で数万、数十万回の試行錯誤が必要となると、試行失敗によってハードウェア破損や安全リスクが発生しうるロボティクス分野なんかではあまりに使いにくい。
このような背景のもとで強化学習のサンプル効率向上のために様々な研究が行われており、有望なアプローチの一つとしてデータ駆動で環境シミュレータを構築する「世界モデルベースの強化学習」というものがある。世界モデルとは現実世界の挙動(状態遷移)を深層学習により再現した疑似シミュレータである。現実世界ではなく、疑似シミュレータ上での試行錯誤であれば数十万回、数百万回の失敗を重ねようと(計算リソース以外には)何のリスクもコストも発生しないためにサンプル効率の課題を踏み倒すことができるからだ。

世界モデルベース強化学習とは
一口に世界モデルと書いたが、実際には強化学習における「世界モデル」とは、「視覚ベースの世界モデル」と「潜在変数空間ベースの世界モデル」の2つのアプローチが存在する。
前者の「視覚ベースの世界モデル」とは人間が視覚的に理解可能な形式で将来予測を行う環境シミュレータであり、技術的には行動で条件づけされた動画予測モデルと理解できる。代表的な手法としてDreamerシリーズやDIAMONDなどが挙げられる。

https://diamond-wm.github.io/
一方で、後者の「潜在変数空間ベースの世界モデル」とは人間が理解できない潜在変数空間上で将来予測を行う環境シミュレータであり、技術的には広義の状態空間モデルと理解できる。代表的な手法として、MuZeroやTD-MPCなどが挙げられる。
MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind
どちらの世界モデルアプローチも盛んに研究されているが、今のところ「視覚ベースの世界モデル」は解釈性と転移性(基盤モデル化)に強みがある一方で、「潜在変数空間ベースの世界モデル」は単純性能に強みがあるように見える。実際、主要なサンプル効率ベンチマークでは、「潜在変数空間ベースの世界モデル」であるEfficientZeroV2(MuZeroの子孫で画像入力タスクに強い)およびTD-MPC2(センサー入力タスクに強い)が「視覚ベースの世界モデル」であるDreamerV3と比較して、多くのタスクで優れたパフォーマンスを発揮している。
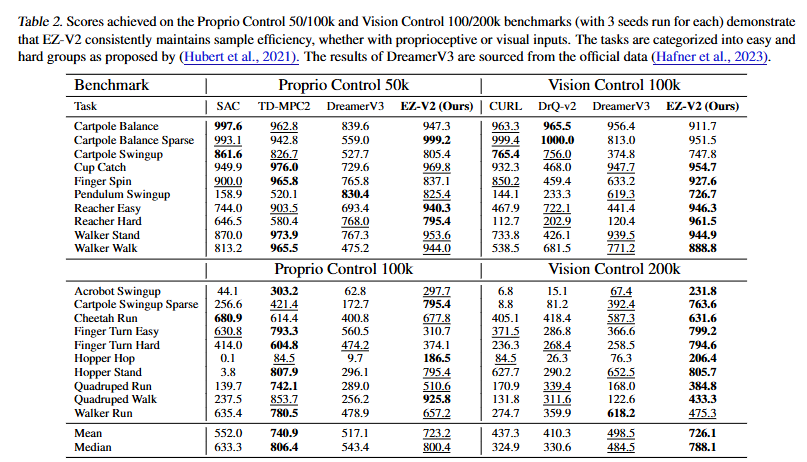
本稿ではMuZeroをサンプル効率特化に進化させた手法であるEfficient ZeroV2の理解と実装を行っていく。
前提手法 MuZero: 潜在変数空間上での木探索
まずはEfficientZeroV2の前提となっている、潜在変数空間ベースの世界モデルの代表的な手法であるMuZeroについて簡単に確認を行う。
MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind
MuZeroは木探索アルゴリズムであるAlphaZeroを拡張した手法である。AlphaZeroは囲碁/将棋で知られる強力なアルゴリズムだが、木探索アルゴリズムゆえに環境のダイナミクス(状態遷移のルール)が完全に既知の系でしか使えないというつらさを抱えていた。そこで、AlphaZeroに環境ダイナミクスの予測機能(=潜在変数空間ベースの世界モデル)を導入することであらゆるタスクを木探索で解けるようにしたのがMuZeroというわけである。
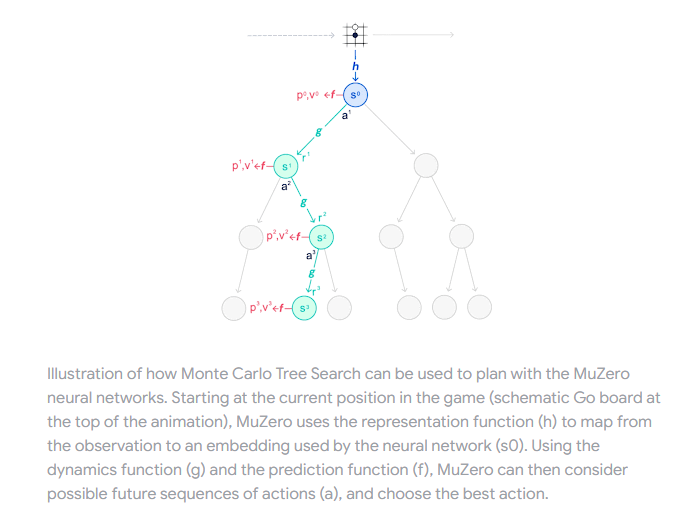
わかりやすく言うと、AlphaZeroはボードゲームなど状態遷移ルールが明示的に与えられているタスクにしか適用できなかったが、MuZeroはビデオゲームやロボット操作など状態遷移ルールが明示的に与えられていないタスクにも適用できるようになった。
MuZeroは単純な性能だけ見ても深層強化学習の最強手法の一つと言えるが、特筆すべきはサンプル効率の良さである。すなわち、MuZeroは潜在変数空間ベースの世界モデル上でのイメージトレーニング(imaginary rollout)を行うことにより、実環境での試行錯誤の回数を大きく減らすことに成功した*1。スポーツの効率的な上達には試合をこなすだけでなく振り返りも大事、と喩えたらわかりやすいだろうか?
EfficientZeroV2:MuZero派生の全部盛り
EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data
MuZeroは斬新かつ強力な手法である一方で、多くの研究余地が残されていたため様々な観点での改良手法が提案されることとなった。余談だけれども、何かのコラムで「エポックメイキングな論文がブルドーザーのように道を切り開き、後追いの研究者は残された石を拾って道を舗装する」と表現されていた方がいた*2。MuZeroはまさにそういう手法だったと思う。
本稿で実装するEfficientZero V2はそのように様々提案されたMuZeroの派生から以下の3手法をまとめあげたものであると表現できる。
EfficientZero: SimSiamスタイルの自己教師あり表現学習の導入によりMuZeroのサンプル効率を大幅に改善
Gumbel MuZero: 行動選択を担うバンディットアルゴリズムの改良によりシミュレーション回数が少ない場合でも方策改善を保証
Sampled MuZero: 離散アクションにしか対応できなかったMuZeroを連続アクションタスクにも対応できるよう拡張
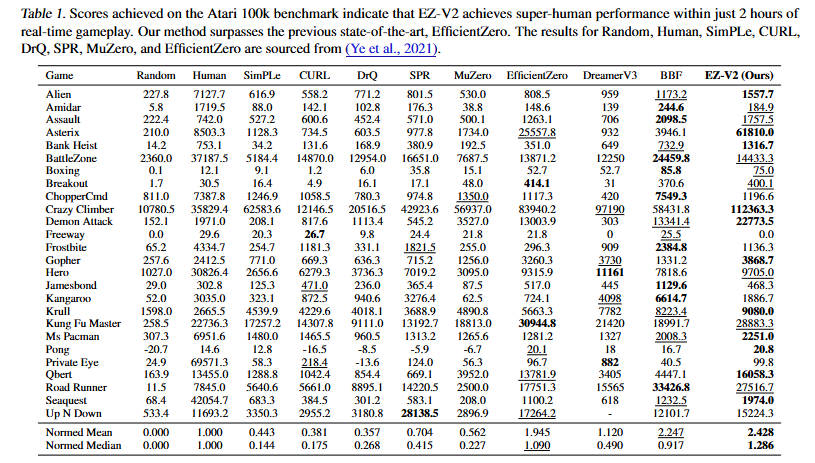
このようなRainbow的な全部盛りアプローチに加えて、Search based Value Estimation (SVE) というオフライン学習を頑健にするトリックの提案により、EfficientZeroV2は主要なサンプル効率ベンチマークにおいて、以下の図に示すようなつよつよ性能を実現することとなった。
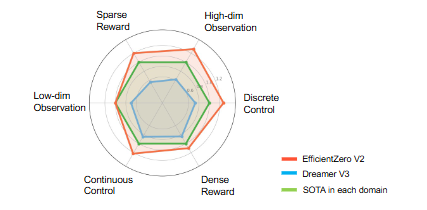
EfficientZeroV2の実装
公式実装:EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data
Tensorflowで再現実装を行った。ただし、重すぎる計算負荷を軽減するためにいろいろな簡易化を入れたことにより完全な再現とはなっていない(具体的な内容はREADMEを参照)。実環境での試行錯誤コストよりも計算コストのほうがはるかに安いという思想は全くもってその通りなのだが、趣味でやってる身としてはマルチGPUが前提になっている手法というのはなかなかつらいものである。
アタリのような離散アクション環境の場合だと実装はMuZeroとさほど変わりないのだが、手法追加による変更点となっている①Gumbel-MCTSと②自己教師あり学習ロスあたりが解説ポイントだろうか。
実装全文:
github.com
① Gumbel-MCTS
POLICY IMPROVEMENT BY PLANNING WITH GUMBEL
MCTSについて、MuZeroと考え方の枠組み自体は大きく変わっていないが、Gumbel-Sequential Halving アルゴリズムの導入により、ルートノードにおけるバンディットアルゴリズムでの行動選択方法が大きく変更されている。
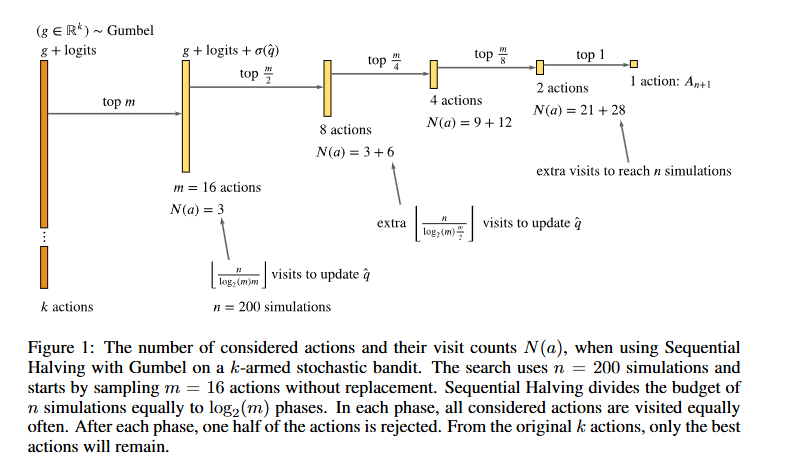
Gumbel MuZeroの行動選択を一言で表現するならサドンデス方式でのバトルロワイアルだ。一定回数のシミュレーションが完了するごとに各行動のスコア(=事前方策+Q値)を比較して、スコア下位半数の行動を脱落させることを繰り返す。なお、スコアにはGumbel分布から発生したノイズを乗せることである程度の探索力を持たせる。
このような行動選択方式をとることにより、シミュレーション回数がアクション回数より少ない場合であっても方策改善が保証されるらしい。ちなみにGumbel-MCTSの著者にはDavid Silverが入っている。
② SimSiamスタイルの自己教師あり学習
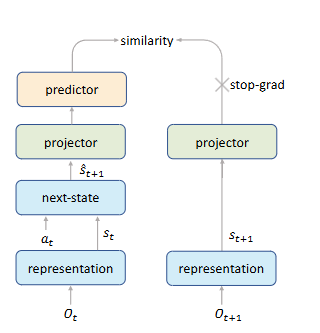
Mastering Atari Games with Limited Data
強化学習において、経験再生(Experience Replay)はサンプル効率を向上させるための定石だがやりすぎると過学習に陥ってしまう。しかし、EfficientZero(V1)は、SimSiamスタイルの自己教師あり学習の導入が過学習を防止するため(過剰に経験再生してもよくなるので)サンプル効率を大きく向上させることが可能であることを示した。
基本的にはSimSiam以上でも以下でもないのだが、一般的なSimSiamでは元画像xと画像加工されたx'のコサイン類似度を最大化するのに対して、EfficientZeroではダイナミクス関数によって予測されたS_t+1と実際のS_t+1のコサイン類似度を最大化するのが重要な違い。ちなみに、同様のアプローチは Data-Efficient Reinforcement Learning with Self-Predictive Representations などでも成功している(こっちはSimSiamでなくBYOL)。
学習結果
GPU一枚(T4)で3日間学習を行った結果、100Kステップで120点くらいといい感じのスコア。計算負荷軽減のために簡易化入れていることもあって論文掲載スコアである400点よりはだいぶ低いが、スコアがサチっている感じもないし検証としては十分なスコアかと思う。計算資源不足でシンプルに勾配更新回数が足りていないのだ。
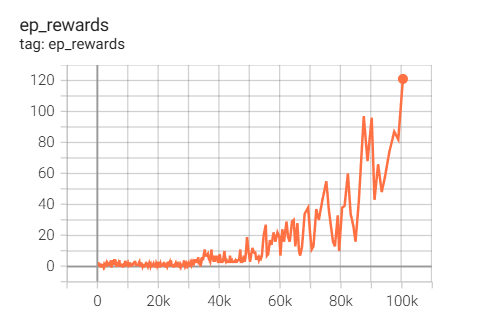
Reimplementation of EfficientZeroV2 (Atari Breakout 100K).
— めんだこ (@horromary) May 24, 2025
While I couldn’t fully reproduce it due to limited computational resources, it still delivered impressive performance with just 100K frames — one of the most sample-efficient RL methods. pic.twitter.com/s2XpLPAQKD
重すぎる計算負荷を軽減するためにいろいろな簡易化を入れたうえで、それでもたった100Kステップに三日かかっていることから計算量のやばさを察していただきたい。
次:??
LLMでのアシストとかかな。
論文メモ:AI co-scientistによる科学的発見の加速
マルチエージェントシステムによる研究仮説提案(AI共同科学者)論文を読んだメモ。
※本記事のすべての画像は以上のリンクが出典
- GoogleのAI co-scientist(AI共同研究者)
- マルチエージェントによる仮説提案フロー
- 具体事例:急性骨髄性白血病(AML)に対するドラッグリポジショング
- 今後の方向性:ツール連携の強化
- ポエム: 研究開発組織はAIの知能ではなく泥臭さに敗北する
GoogleのAI co-scientist(AI共同研究者)
研究仮説提案のためのマルチエージェントシステム
2025年2月にGoogle&DeepMindが発表した"AI co-scientist"(AI共同科学者)では、「新規性」と「妥当性」を両立した研究仮説立案をLLM(大規模言語モデル)によって遂行するマルチエージェントシステムを提案している。

新規性の無い研究仮説を検証する価値はなく、妥当性の低い研究仮説は投資対効果に見合わない。ゆえに「新規性」と「妥当性」のトレードオフへのバランス感覚を備えたAI共同科学者は、経済的合理性を無視できない民間企業での研究開発において重要な役割を担う可能性が高いと見込まれる。
これは別に「人間の研究者の仕事がAIに奪われる!」ということを言いたいのではなく、単純に研究テーマ設定という何千万、何億円規模の投資の意思決定においてAIを利用しない理由が無いというだけだ。
ランクマッチ対戦による仮説の「新規性」「妥当性」改善ループ
LLMと文献検索の組み合わせにより、AI生成された仮説について「新規性」と「妥当性」のあり/なしだけ検証すること自体はいまやそれほど難しいタスクではない。すなわち、過去の文献すべてと突合して新規性があるか、過去の報告と矛盾がないかをLLMに検証させればよい。
難しいのは複数の提案仮説の中でどの仮説がもっとも「新規性」と「妥当性」を両立しているかを定量的に判断することだ。この問題の解決のためにAI共同科学者はランクマッチアルゴリズムによる提案仮説トーナメントを導入する。

ここでランクマッチ*1とはオンライン対戦ゲームでしばしば使用される順位決めアルゴリズムのことである。この方法では近い実力のプレイヤー同士でのマッチングを繰り返すことにより、少ない対戦回数で効率的に妥当な全体順位を推定することができる。同様に、複数の仮説の良さをいきなり順位付けすることは難しくとも、2つの仮説のどっちのほうが良さそうかという2択であれば判断容易であることを利用し、AI共同研究者では仮説を1対1で戦わせ続けることで仮説の妥当な全体順位を推定する。つまりは"俺より強い仮説に会いに行く"。
AIによる仮説提案の既存研究は多いが、大量の生成仮説を全体感を持ってマネージする仕組みがないゆえに結果の不確実性や視野狭窄の問題を抱えており実用レベルに到達していなかった印象がある。一方で、AI共同科学者はランクマッチ方式の導入により大量に生成された提案仮説から有望な仮説を選別し、全体感を更新し、次の仮説生成につなげる改善ループを実現する。とても巧い仕組みだ。
創薬分野の3事例において有効な仮説提案に成功
Towards an AI co-scientistによるとAI共同研究者は単なる机上のアイデア提案ではなく、すでに創薬分野の3事例において実験的に有効性が確認された仮説提案に成功しているとのこと。ウェット実験への誠実さはDeepMindの美点だ。
急性骨髄性白血病(AML)に対するドラッグリポジショニング:既存薬剤からAMLに対して有効な可能性のある新規候補薬を複数提案、in vitroにおいて腫瘍の生存能力を阻害することを示した
肝線維症の新規治療標的の発見: 肝線維症治療のための3つのエピジェネティック修飾因子およびそれを標的とする4つの薬剤を提案、ヒト肝臓オルガノイドにおいて抗線維化活性を確認
抗菌薬耐性メカニズムの説明: 細菌の進化における新規遺伝子導入メカニズムについて、未発表(査読中)論文の新規仮説を再現することに成功
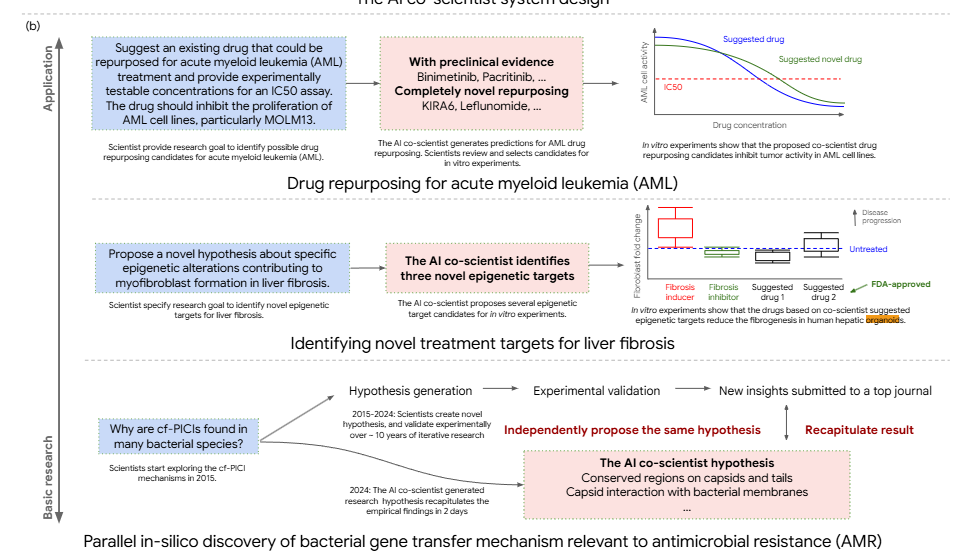
ドラッグリポジショニング(あるいはドラッグリパーパシング)と治療標的発見については製薬会社にとって垂涎の応用事例だろう。実用的なレベルでこれができるなら調査一回のコストが数百万円でも安い。ここで恐ろしいのはAI共同科学者は創薬特化LLMを一切使用せずGemini2.0のみで新規仮説提案を実現していること。つまりは製薬会社はその気になれば明日にでもAI共同科学者の再現実装を開始することができるのだ。
マルチエージェントによる仮説提案フロー
7人のAIエージェント
研究目的を与えられたAI共同研究者システムは①仮説の生成、②仮説の順位付け、③仮説探索方針の策定の3ステップを繰り返すことで提案仮説を改善させていく。このプロセスでは異なる役割を持つ7つの専門AIエージェントによる協働が行われている。
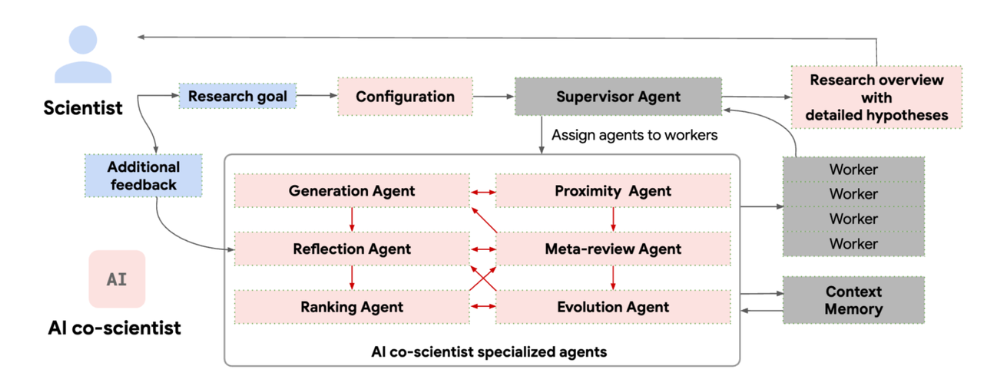
以下に各専門エージェントの名称と役割を示す(日本語名は適当な意訳)。各専門エージェントのプロンプトはTowards an AI co-scientistのAppendixに記載があるので興味があれば参照されたし。
- 生成エージェント(Generation agent):
- 文献探索や模擬議論、条件付き推論など様々な手法を用いて新たな仮説を生成
- 査読エージェント(Reflection agent):
- 査読者のように批判的な視点から、生成された仮説の妥当性、新規性を評価
- 順位付けエージェント(Ranking agent):
- Eloベースのトーナメント(≒ランクマッチ)での対戦において仮説の相対的な優劣を判断
- 近接エージェント(Proximity agent):
- ランキング内の仮説について類似性に基づいたクラスタリングを通して仮説の多様性向上を促進
- 進化エージェント(Evolution agent):
- 上位にランク付けされた仮説を洗練し、精度を向上
- メタレビューエージェント (Meta-review agent):
- レビューや議論のパターンを分析し研究計画へのフィードバックを生成
- 監督エージェント (Supervisor agent):
- 研究目標に基づいて、各エージェントのタスクを定義し、実行順序を決定
- 各エージェントの処理状況を監視し、必要に応じてタスクの優先順位を変更
- メタレビューエージェントからのフィードバックを各エージェントに伝達し、学習と改善を促進
- 最終的な研究計画をまとめ、人間の専門家(研究者)に提示
こう見ると監督エージェントのやることが多い。管理職は大変だな。
①仮説の生成
担当: 生成エージェント
初期仮説は生成エージェントにより、4つのアプローチで構築される(仮説の出力例)。
- Web文献検索:
- 時系列に沿って関連文献の要約とレビューを実施、その結果に基づいて新たな仮説を提案。プロンプトはシンプル。
- 模擬議論:
- LLM同士でディスカッションを行い仮説を洗練。こちらもシンプルなプロンプト。
- 仮説の分解:
- 提案仮説を検証可能なサブ仮説に分解し、研究・実験計画をデザインする。仮説の出力例で言うと”Experimental design and validation”を作ってるのだと思われる。
- 仮説の拡張:
- 既存研究のサマリおよびメタレビューエージェントからのフィードバックに基づき、有望そうだが研究が不十分な領域にあたりをつける。

生成エージェントにトリッキーな要素は無い。”関連文献を時系列的・網羅的にレビューして既存知見をまとめる”、”既存知見から示唆を抽出し議論を通して洗練する”、”検証可能な仮説としてデザインする”という研究者として至極真っ当なことをやっているように見える。
②仮説の順位付け
担当: 査読エージェント、ランキングエージェント、近接エージェント
生成された仮説はまず査読エージェント(Reflection agent)により多段階の徹底的な検証が行われる。既存知見との矛盾がないか、新規性があるかといった批判的検証はもちろん、仮説の根拠を強化できる関連文献がないかを検索するなど協力的な検証も行われる。
査読が完了した仮説はランクマッチトーナメントに投入されElo ratingによって順位付けされる。
イロレーティング (Elo rating) とは、対戦型の競技(2人のプレイヤーまたは2つのチームが対戦して勝敗を決めるタイプの競技)において、相対評価で実力を表すために使われる指標の一つ。数学的裏付けのある最も著名なレーティングシステムである。(wiki)
ランキングエージェントは仮説同士の対戦(複数ターンの科学的議論)における勝敗判定を担う。ランキングエージェントの出力例を見るとわかりやすいが、OpenReviewっぽいことをやっている。

ここで、近接エージェント(Proximity agent)は仮説ランキングの多様性向上のために補助的な役割を担う。すなわち、類似性にもとづいたクラスタリングにより仮説の多様性を促進する、対戦ににおいて類似した仮説同士でのマッチングにより重複排除を促進することなど行う。
③仮説探索方針の策定
担当: メタレビューエージェント、進化エージェント、監督エージェント
メタレビューエージェントはこれまでの各仮説のレビュー/議論の要約から、共通の論点を特定してメタレビューを作成する。メタレビューは探索方針策定において中心的な役割を担う。
進化エージェントはメタレビューで特定された問題点を考慮し、既存の仮説から新しい仮説を生成する/複数の仮説を組み合わせる/視点を変えるなどの方法でより洗練された仮説を作成する。
Appendixを見ると進化エージェント用のプロンプトは、フィージビリティ向上/斬新なアイデア提案など用途別に複数用意されているようだ。

監督エージェントはメタレビュー(など)に基づいて各エージェントへのリソース割り当て優先度を調整しシステム全体の動作を最適化する役割を担う。
このように、メタレビューエージェント、進化エージェントそして監督エージェントの協働体制が全体感を踏まえた仮説生成と改善を実現する仕組みを提供する。
具体事例:急性骨髄性白血病(AML)に対するドラッグリポジショング
※ 4.5.2 The AI co-scientist identifies novel drug repurposing candidates for acute myeloid leukemiaのAI要約
AI共同科学者による仮説提案:
- 探索範囲は33種類のがんに対する2,300の承認済み薬剤に限定
- このため「生成エージェント」および「ランキングエージェント」 のプロンプトを調整し、制約された検索空間内で仮説生成するように設定
- 仮説の最終順位付けでは計算生物学解析(
DepMapスコア)の結果も考慮
- DepMapスコア:特定のがん細胞株で、その遺伝子がどれほど必須であるかを確率的に表す指標
薬剤候補の選定(5種類):
AI共同科学者によって提案されたトップ30の薬剤候補仮説は専門の腫瘍学者と共有され、ウェットラボ実験に進める ドラッグリポジショニング候補の選定のための評価が実施されました。 結果として以下の5つの薬剤が、AMLにおける作用機序の可能性 に基づいてウェットラボ検証の対象として選ばれました。
- Binimetinib(MEK1/2阻害剤)
- RAS/RAF/MEK/ERK経路 を阻害し、NFκB(核因子カッパB) の活性を低下させる可能性。
- MEK阻害により、IKK複合体の破壊を介してNFκBの恒常的活性化を抑制し、AML細胞の増殖・生存シグナルに影響を与える。
- STAT3やc-Mycなどの転写因子 を制御し、AMLの再発リスクを低減できる可能性。
- Pacritinib(JAK2/FLT3二重阻害剤)
- STAT3/5を活性化 し、NFκBを介して炎症性サイトカインの産生やPI3K/AKT経路の活性化 に関与。
- FLT3阻害により、AML細胞の生存を維持する耐性経路の発達を防ぐ。
- Dimethyl fumarate(DMF)
- Cerivastatin(スタチン類)
- Pravastatin(スタチン類)
- 代謝・炎症リプログラミング を誘導し、急速に増殖する細胞の小胞輸送に直接影響を与える可能性。
in vitroでの検証結果:
5種類の薬剤をin vitroで検証 した結果、以下の3種類の薬剤が細胞生存率の抑制 を示した。
- Binimetinib
- Pacritinib
- Cerivastatin
特に、Binimetinib(転移性メラノーマ治療薬として承認済み) は、AML細胞に対して IC50 = 7 nM という非常に強い阻害効果を示した。
今後の方向性:ツール連携の強化
汎用性の実証を優先し現在のAI共同科学者のツール連携は基本的にはWeb検索のみのようだが、必然的な発展の方向性として各種研究ツールとの連携が考えられる。実際、論文内でもiPS細胞の重要因子であるOCT4(オクタマー結合転写因子4)タンパク質の配列最適化の提案をAlphaFoldで評価する例が示されている(Appendix 5)。
分子動力学計算ソフトウェアと連携すればリガンド構造の最適化ができるだろうし、SciFinderやReaxysと連携すれば最適な合成経路を考えてくれるだろう。このようにドライのタスクがAIで加速すると今度はウェットの実験がボトルネックになってくる。数年後のトレンドはAI×ロボティクスによる自動実験だろうか。
ポエム: 研究開発組織はAIの知能ではなく泥臭さに敗北する
担当者の好き嫌いや成功体験が優先されて過去文献の調査すら不十分なまま走り出した研究テーマが、その半年後に過去研究から筋悪が判明してポシャるとか、他社特許を思いっきり踏んでることを指摘されてピボットするなんてことは大企業の研究開発組織あるあるなんじゃないかと思う。
一方、AI共同科学者は関連する過去文献すべてを徹底的に調査し、考えられる仮説を抽出し、批判的思考による価値検証するサイクルを無数に繰り返すことで研究テーマを進化させていく。あまりにも真っ当で誠実な仮説構築プロセスだ。しかし、こんな泥臭いプロセスをやり切れる研究開発組織はどれだけあるのだろうか?
現時点のAI共同科学者の「知能」(主に論理的思考力)が人間の研究者を超えているとは思わない。しかし、その超人的な「泥臭さ」だけであっても研究開発組織に大変革をもたらしうるポテンシャルがあると感じた。
*1:わかりやすさのためにランクマと表現したが正しくはEloレーティング
LLMチューニングのための強化学習①:GRPO(Group Relative Policy Optimization)
DeepSeek-R1にも採用されたLLMチューニングのための強化学習手法 GRPO(Group Relative Policy Optimization)について考えたことをまとめます。
- GRPO: DeepSeek-R1の強化学習ファインチューニング手法
- 前提手法:TRPO/PPO
- GRPOとPPOの差分:①アドバンテージ算出と②参照モデルからのKL距離制約
- 変更点①: アドバンテージAの算出方法
- 変更点 ②: 参照モデル(SFTモデル)からのKL距離制約
- まとめ
- 次:GSPO(Group Sequence Policy Optimization)
GRPO: DeepSeek-R1の強化学習ファインチューニング手法
GPT-o1モデルに匹敵する性能を示す DeepSeek-R1 が話題となっています。DeepSeek-R1は商用可能なオープンウェイトモデルかつ破壊的に安価なAPIを利用可能であるため、様々なLLMユースケースにおいて大きな影響が予想されます。
テクニカルな観点では、DeepSeek-R1のRLチューニングではGRPO(Group Relative Policy Optimization)というPPOをLLMチューニングに特化させた強化学習手法が提案されていることが興味深い点となっています*1。


GRPOについて、PPOからの最大の変更点はアドバンテージ(A)をエピソード報酬(r)から直接算出することにより状態価値V(s)の関数近似を不要としたことです。この変更により、従来のPPOではRLチューニング時に方策関数(=LLM)と状態価値関数V(s)の2つのネットワークを同時訓練する必要があったところを、GRPOでは方策関数(=LLM)の訓練だけを行えばよくなりました。訓練すべきネットワークが一つになったことは要求計算量の減少はもちろん、学習の安定性向上にも大きく寄与していると考えられます。
さらに、学習が安定していると大きなモデルと大量データでの訓練が容易になるため、おそらくは間接的に性能向上にも寄与していると思われます。
前提手法:TRPO/PPO
GRPOの前提手法であるTRPOとPPOについて John Schulmanの講義資料 から抜粋して簡単に説明します。
TRPO: Trust Region Policy Optimization
方策勾配定理は報酬を最大化するための方策パラメータの勾配方向を教えてくれますが、適切な更新サイズについては何も教えてくれないためしばしば学習が不安定化します。そこでTRPOでは方策更新において、更新後方策πθと更新前方策πθ_oldにKL距離を制約項として与えることで極端なパラメータ更新を回避します。
ここで、目的関数
 は 重点サンプリング法 によって導出されます。
は 重点サンプリング法 によって導出されます。
TRPOではサンプル収集→ 複数回の勾配更新 → サンプル収集→ 複数回の勾配更新 を繰り返すため、データ収集を行った方策πθ_old と現在方策πθが必ずしも一致しません。 そこで上記のように重点サンプリングによって目的関数の補正を行う必要があります。
[1502.05477] Trust Region Policy Optimization
PPO: Proximal Policy Optimization
TRPOは毎回の勾配更新ごとにラグランジュ乗数法で制約付き最適化問題をまじめに解くので計算量が非常に大きくなってしまうため、大規模なニューラルネットワークに適用することができません。この問題の解決のために簡易化されたTRPOとして提案された後継手法がPPOです。
PPOではimportance ratioが大きくなりすぎた(あるいは小さくなりすぎた)場合にはクリップしてしまうというアルゴリズムで暗黙的なKL距離制約を与えことで、TRPOの目的である極端なパラメータ更新防止を実現します。
[1707.06347] Proximal Policy Optimization Algorithms
その他参考資料:
Introduction - Hugging Face Deep RL Course
ハムスターでもわかるTRPO ①基本編 - どこから見てもメンダコ
ハムスターでもわかるProximal Policy Optimization (PPO)①基本編 - どこから見てもメンダコ
GRPOとPPOの差分:①アドバンテージ算出と②参照モデルからのKL距離制約
[2402.03300] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
目的関数を見ると、GRPOとPPOの主要な差分は2点のみであることがわかります。
PPOの目的関数:

GRPOの目的関数:

① アドバンテージAの算出方法:
従来のPPOでは方策関数(=LLM)とは別に訓練される状態価値V(s)の関数近似を用いてアドバンテージを算出していましたが、GRPOでは報酬rのみでアドバンテージを算出するため状態価値V(s)の関数近似が不要となっています。
② 参照モデル(SFTモデル)からのKL距離制約の置き場所:
従来のPPOでは参照モデル(SFTモデル)からのKL距離制約は報酬rに含められていましたが、GRPOでは明示的に目的関数内にペナルティ項として追加されています。
言い換えると上記2点以外はPPOと全く変わらないのですが、それでも①のアドバンテージ算出方法変更についてはシンプルながら強い納得感と高い実用性を備えたエレガントなアイデアであると感じます。②は計算量減ってうれしいくらい。
変更点①: アドバンテージAの算出方法
REINFORCE: 価値関数近似なし方策勾配法
方策勾配定理より、行動選択が方策関数πθに従うときに期待される累積報酬 J(θ) の勾配を次式よりモンテカルロ推定することができる。
ここで、Q(s_t, a_t)は状態行動価値であり、状態s_tにおける行動選択a_tの良さを表す指標である。また、b(s_t)はaに依存しない任意の関数でありベースライン関数と呼称される。ベースライン関数は勾配推定(∇J)の期待値には影響しないが適切に設定することで勾配推定の分散を低減することができる。任意関数であるので例えば一様にb(s)=0 とすることもできるが、E[Q(s, a) - b(s)] = 0となるようb(s)を設計できると勾配推定の分散が低減され収束性が向上する。
Qは様々な方法で推定することができるが、もっとも単純なのは時刻t以降の報酬和( )を状態行動価値Qの推定値とする方法である。この方法は一般にREINFORCEと呼称される。
ベースライン関数b(s)としては計算の容易さからリターン(エピソード合計報酬)の推定平均値が採用されることが多い。しかしこの方法は(重要)報酬がエピソードの最終ステップにのみ発生する特殊な環境を除き、時刻t=0以外ではE[Q(s, a) - 平均リターン] ≠ 0 であるためそれほど良いベースライン設計ではない。
このようにREINFORCEでは状態行動価値Q(s, a)の算出においてもベースライン関数b(s)においても価値の関数近似を行わず報酬から直接推定するため、訓練するネットワークは方策関数のみとなる。
PPO(Actor-Critic): 価値関数近似あり方策勾配法
ベースライン関数の自然な選択肢の一つは状態価値V(s)の関数近似である。
最適方策において E[Q(s, a) - V(s)] = 0となるため、V(s)は良いベースライン関数となる。
Q(s, a) - V(s)は一般にアドバンテージ関数Aと呼称される。直感的にはアドバンテージ関数は状態sにおける行動aの相対的な価値を表現していると理解できる。価値を相対化することにより、ある状況Sでどの行動Aを選ぶべきなのかを強調することが可能となる。
V(s)の関数近似を用いたアドバンテージ関数に基づく方策勾配法アーキテクチャは一般にActor-Criticと呼称される。PPOもまたActor-Critic系手法の一つである。
Actor-Criticでは方策関数と価値関数の2つのネットワークを共進化的に訓練する必要から学習不安定性の課題があるものの、多くの場合ではそれに優る性能向上が得られるため、さまざまな強化学習タスクにおいて方策勾配系手法の主流アーキテクチャとなっている。
なお、Q(s, a)をどのように推定するかによりアドバンテージ関数にバリエーションが存在する。たとえば Q(s, a) = r_t + V(s_t+1)より状態行動価値Qを状態価値Vから推定する方法があり、これは1ステップアドバンテージと呼称される(たぶん)。
PPOではGAE(Generalized Advantage Estimation) という、より精緻なアドバンテージ計算手法が採用されているが上記の1ステップアドバンテージと本質的な違いはない。
GRPO: スケーリングされたREINFORCE
「回答完了時に初めて報酬が発生する」というLLM報酬モデルの特性を鑑みると、価値の関数近似はやめてREINFORCEに近い方法でアドバンテージ算出するのが効率良いのでは?と提案しているのがGRPOであると個人的に理解しています。
まずはREINFORCEの更新式に立ち戻ります。
LLMの報酬モデルのように、報酬が最終ステップ(回答完了時)のみで発生する場合には時刻T以外での報酬r_tが0となるため、時刻t以降の報酬和は開始時刻tに依存せずr_Tとなります。すなわち、
ここで最終ステップの即時報酬r_Tは与えられた質問(question)への回答完了(output)に対する報酬モデルの出力であるので、 と表記してREINFORCEの更新式を書き直します。
次にベースライン関数b(s_t)の設計を考えます。
前述したとおり、 となるようにb(s)を設計することができれば勾配推定の分散が低減され学習が安定化されるため、b(s)として推定すべきは
の期待値であり、そのためのもっとも簡単な方法はモンテカルロ推定です。すなわち、1つの質問(question)について多数の回答(output)のサンプリングを行い、シンプルに平均値をとることでr_out|questionの期待値を推定することができます。

ある質問qからG個の回答グループ(o1, o2 ... oG)がサンプリングされたとき、各回答についての報酬r_iを用いてREINFORCEを次のように書き直すことができます。
当然、E[r - mean(r1, ... , rG)]=0であるのでこれはよいベースライン関数設計であると言えます。さらに、回答グループの報酬についての標準偏差を用いてスケーリングすることでGRPOのアドバンテージ関数を得ることができます。
このように、LLM報酬モデルの性質を鑑みてベースライン関数b(s)として状態価値V(s)の関数近似ではなく、報酬期待値のモンテカルロ推定を採用したのがGRPOです。ベースライン関数の設計という観点からシンプルかつ納得感のあるエレガントな設計となっていることがわかります。ポイントはランダムな質問群に対して多数の回答をサンプリングするのではなく、一つの質問に対して多数の回答をサンプリングすることにより、高い精度での期待値推定が可能となることです。これがGroup Relative Policy Optimizationたる所以となっています。
GRPOのアドバンテージ算出方法であれば従来のPPOとは異なり状態価値V(s)の関数近似が不要であるため、2つのネットワークを共進化させる必要性ゆえに学習が不安定なActor-Criticアーキテクチャを回避することができます。
変更点 ②: 参照モデル(SFTモデル)からのKL距離制約
従来は参照モデル制約は報酬に含められていた
LLMの強化学習チューニングではモデルがpretraining時の記憶を失うことを防ぐため、訓練前モデル(pretrainedモデル / SFTモデル)とのKL距離が離れすぎないように制約を与えることが一般的です。このKL距離制約は従来(Instruct-GPTなど)は報酬の一部として暗黙的に埋め込まれていました。

一方、GRPOでは制約項D_klが目的関数に明示的に組み込まれています。

この変更理由の一つは、アドバンテージ関数の計算グラフをシンプルにして計算量を減らすことを狙ったのだと思われます。また、上述したようにGRPOのベースライン関数は「回答完了時に初めて報酬が発生する」というLLM報酬モデル特有の性質を前提にしているため、報酬にKL制約ペナルティを含めることで途中報酬が発生するのを嫌ったのではないかと思います。
KL距離のモンテカルロ推定
KL距離はモンテカルロ推定によりサンプリングベースで算出するのですが、論文の式が見慣れない感じになっています。

前提として、πθとπrefのKL距離はもっとも単純には以下の式に従いサンプリングベースで推定することができます。
しかし、この推定値は不偏ではあるものの分散が大きく安定しません。そこで 制御変量法 というトリックを用いると分散を減らすことができます。制御変量法を用いたKL距離のモンテカルロ推定について結論だけ述べると、以下の算出式によって良好な推定値を得ることができます。

詳細はJohn Schulmanの記事 ”Approximating KL Divergence”を参照。
まとめ
- GRPOは「回答完了時にのみ報酬が発生する」というLLM報酬モデル特有の性質を前提に、REINFORCEのベースライン関数b(s)をうまく設計することでPPOにおいて状態価値V(s)の関数近似を不要とした
- 状態価値V(s)の関数近似が不要となったことで計算量が減るのはもちろん、学習の安定性が向上し結果として性能向上につながった(と思われる)
次:GSPO(Group Sequence Policy Optimization)
GRPOの学習安定性を改善した手法。Qwen3にて採用。 horomary.hatenablog.com
*1:なお、GRPOの初出はDeepSeek-R1ではなくDeepSeek-Math
サンプル効率強化学習①:Bigger, Better, Fasterの実装
たった2時間のゲームプレイで人間相当性能に到達可能なサンプル効率の高い強化学習手法 ”Bigger, Better, Faster”を実装します。
背景: 強化学習実用の課題は劣悪なサンプル効率
レトロゲームで人間並みのパフォーマンスを実現したDQN (Deep Q-Network) が登場してからわずか10年間ほどで深層強化学習は驚くべき発展を遂げましたが、一方で深層強化学習の実世界応用の成功例は一部の例外を除き*1まだまだ限られています。
強化学習の実用のための最大の課題はサンプル効率(学習効率)です。
Atari環境(レトロゲームベンチマーク)において最先端の手法であるMuZeroは人間をはるかに超えたパフォーマンスを発揮しますが、その超人性能は実ゲームプレイ時間に換算しておよそ4000時間もの試行錯誤に支えられています。しかし、ゲームやシミュレータならともかく実世界のビジネスにおいて4000時間の多数の大失敗を含む試行錯誤が可能な状況はほとんどなく、これが実用上の大きな課題となっています。
一方で人間はわずか十数分の試行錯誤で一定のパフォーマンスに到達することが可能*2であり、そのサンプル効率(学習効率)は最先端の強化学習よりもはるかに良好です。もし、このような人間レベルの高いサンプル効率(学習効率)を備えた強化学習手法があるならば、強化学習実用の場が大きく広がることが期待できます。

強化学習におけるサンプル効率向上アプローチ
評価指標: Atari-100Kベンチマーク
強化学習分野において、Atari環境では200M環境ステップ(=4000時間のゲームプレイ相当)完了時の性能でアルゴリズムを評価することが慣例となっていますが、しかし前述のように4000時間の試行錯誤はあまりにも非現実的な設定であるため、より実用を意識したアルゴリズムにはAtari-100K(100K環境ステップ=2時間のゲームプレイ相当)が評価に使われるようになっています。
2024年現在、Atari-100Kにおける有力なアプローチは大きく2つに分類できます。
- ①リセット法によるリプレイ率増大
- ②環境シミュレータ(世界モデル)のデータ駆動構築

①リセット法によるリプレイ率の増大
該当手法: SR-SPR(2022), BBF: Bigger, Better, Faster(2023)
Q学習のようなオフ方策強化学習アルゴリズムにおいてサンプル効率を上げたいならばリプレイ率(経験再生の頻度)を上げることが手っ取り早い解決策のように思いますが、実際には学習が極めて不安定になるためうまくいきません。これはリプレイ率を上げすぎることにより初期段階で価値関数の過学習が発生し同じ行動ばかり選択するようになるため、試行錯誤によってより良い経験を取得することができなくなり性能向上が頭打ちになるためです。*3
この問題の解決策としてSR-SPRでは価値関数を定期的にソフトリセットすることで過学習を防ぐという荒業でリプレイ率の増大を実現する「リセット法」を提案しました。本稿ではSPRの後継手法である BBF(Bigger, Better, Faster) の実装を紹介します。
②環境シミュレータ(世界モデル)のデータ駆動構築
該当手法: DIAMOND(2024), EfficientZeroV2(2024), DreamerV3(2023) など多数
もしも環境の高精度シミュレータが存在するならばノーコストで試行錯誤ができるのでそもそもサンプル効率が論点になりません、このために教師あり学習により環境シミュレータ、いわゆる世界モデル(World Models)を構築します。このアプローチは実空間に復元可能なシミュレータを構築する方法と、潜在変数空間のみのシミュレータを構築する方法の大きく2流派が存在します。
前者の”実空間に復元可能なシミュレータ”を構築する方法は、動画予測というタスクの困難さにより従来それほどうまくいっていなかったのですが、近年登場した拡散モデルの恩恵を受けた高性能なアルゴリズムが出現し始めています。

後者の"潜在変数空間のみのシミュレータ"を構築する方法は、シミュレータと言いつつ人間には何が起こっているのかまったくわからないという説明可能性上の弱みはあるものの高い性能を発揮することが分かっています。ここに分類される代表的なアルゴリズムとしてはMuzeroのサンプル効率改善版である EfficientZero や、その後継の EfficientZeroV2 などが挙げられます。
Bigger Better Faster: BBF (2023)
本稿では「①リセット法によるリプレイ率の増大」アプローチの最新手法であるBBF (Bigger, Better, Faster) の簡単な解説とTF2による再現実装を行います。BBFはAtari-100K環境において当時のほぼSOTAという性能面での優秀さだけでなく、「実装がシンプル」かつ「GPU効率も良好」というお手軽さが魅力の手法です。
手法解説
BBFは同じ著者による3連作(SPR→SR-SPR→BBF)の最新手法のため順に概要を解説していきます。
SPR(2020)
[2007.05929] Data-Efficient Reinforcement Learning with Self-Predictive Representations
SPR(Self-Predictive Representations)はQ学習の補助タスクとして自己教師あり表現学習を行うことで、「過学習の低減」と「より良い表現抽出」を可能にする手法です。この工夫によりNature DQN では0.25に設定されていたリプレイ率(=4環境ステップごとに1回ネットワーク更新)を1.0(=1環境ステップごとに1回ネットワーク更新)まで増大させることに成功しています。
自己教師あり学習の方法について、基本的にはネガティブサンプル不要な対照学習手法 BYOLに従いますが、CV一般向けのBYOLでは元画像とaugmentationした画像の類似度を最大化するのに対して、SPRのBYOLでは「現在状態」と「kステップ前の過去状態から将来予測によって得られた現在状態」の類似度を最大化します(下図)。

SR-SPR (2022)
Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier | OpenReview
SR-SPRは、上述のSPRにネットワークを定期的にソフトリセットする「リセット法」を追加することにより、リプレイ率を増やすほど性能が増加する「リプレイ率のスケール則」を発見した手法です。より具体的にSR-SPRのリセット法とは、40K回のネットワーク更新ごとにEncoder CNN と transition model以外の層の重みを完全リセット(再初期化)する、Encoder CNNとtransition modelについては現在のweightとランダム初期化によって得られたweightで8:2で重みづけ和を取ることによりソフトリセットを行うというものです。リセット法が初期の過学習低減のための強制的な忘却機構として働くために効果的な表現抽出が行えることで性能が向上するのであると考えられます。
論文中に脳科学についての言及は一切ありませんが、個人的には人間の学習機構ともつながりがありそうだなと思ってます。全然倒せなくて行き詰っていたボスが一晩寝てもう一回やったらすんなりクリアできた、みたいな。

Bigger, Better, Faster (2023)
https://arxiv.org/pdf/2305.19452
Bigger, Better, Faster (BBF) は SR-SPRのハイパラ検討を詳細に行うことでIQM1.0 (人間相当性能)超えの大幅な性能向上に成功した手法です。SR-SPRから手法的にはほぼ変わっていないですがBBFの大きな貢献として、大きなモデルであればより強くリセットすることで「モデルサイズのスケール則」が成立することを発見したことがあります。
これによりCVやNLPなどの他分野では数年前から行われてきた「モデルサイズ増大による性能向上」の恩恵を強化学習分野でも受けることができるようになります。

Tensorflow2による実装
実装全文: github.com
基本的にはDQN+αであり実装上の難解な部分は少ないため、ここでは2つの重要なポイントだけを紹介します。
- A. リセット法によるネットワーク摂動
- B. SPRの自己教師あり表現学習向けtransition model
※なお、BBF論文ではベースDQNとしてRainnbowを採用していますが、実装がめんどいのでここではベースDQNとしてQR-DQNを採用してます。
A. リセット法によるネットワーク摂動
BBFのリセット法とは、40K回のネットワーク更新ごとにEncoder CNN と transition model以外の層の重みを完全リセット(再初期化)する、Encoder CNNとtransition modelについては現在のweightとランダム初期化によって得られたweightで5:5で重みづけ和を取ることによりソフトリセットを行うというものです。この実装はとてもシンプルです。
B. SPRの自己教師あり表現学習向けtransition model
前述のとおり、SPRのBYOLでは「現在状態」と「kステップ前の過去状態からの将来予測によって得られた現在状態」のコサイン類似度を最大化します。実装自体は基本的にただのBYOLなので難しくないのですが、将来予測のためのtransition modelの構造がややトリッキーなので実装を紹介します。Transition Modelでは過去状態S_tから行動履歴に従って時間発展させることでS_t+kを予測します。ちなみにMuZeroのtransition modelと同じ実装が採用されています。
※なお、コサイン類似度の最大化は単位ベクトルの二乗和誤差を取るのと同等なのでまじめにコサイン類似度を計算する必要はない。
学習結果
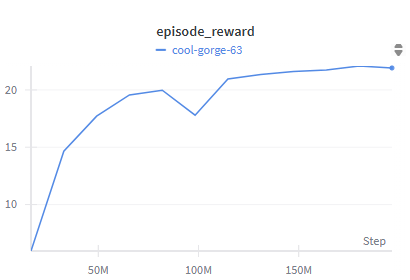
Breakoutの人間平均は30点くらいであるのに対して再現実装したBBFのスコアは300を超えにつき、たった100Kステップの学習でも十分な性能を発揮することを確認できました。
Bigger Better Faster (Atari-Breakout 100K step, Unofficial re-implementation in TF2) pic.twitter.com/cajO00dPGi
— めんだこ (@horromary) 2024年11月1日

ちなみに、リセット法により定期的(40K勾配更新ごと)にネットワークに摂動が与えられるためlossの履歴は心電図みたいになります。

次: EfficientZeroV2
*1:最強AI「MuZero」とは ルールを知らないのにゲームで勝ちまくる:日経クロストレンド, 核融合炉を強化学習で制御する | 日経Robotics(日経ロボティクス)
*3:この話をまじめに書くには余白が足りないので興味のある方は 過去記事: オフライン強化学習 や 強化学習(第2版)11章を参照