サンプル効率に優れたMuZeroの後継手法EfficientZeroV2を実装。
- 強化学習実用のカギはサンプル効率
- 世界モデルベース強化学習とは
- 前提手法 MuZero: 潜在変数空間上での木探索
- EfficientZeroV2:MuZero派生の全部盛り
- EfficientZeroV2の実装
- 学習結果
- 次:??
関連記事:
サンプル効率強化学習①:Bigger, Better, Fasterの実装 - どこから見てもメンダコ
世界モデルベース強化学習①: DreamerV2の実装 - どこから見てもメンダコ
MuZeroの実装解説(for Breakout) - どこから見てもメンダコ
強化学習実用のカギはサンプル効率
DeepMindのDQNが登場してからわずか10年間で深層強化学習アルゴリズムは大きく発展した一方で、実世界応用の成功例は一部の例外を除きまだまだ限られている。
この原因の一つとして強化学習のサンプル効率が極めて劣悪であること、すなわち強化学習が性能を発揮するためには実環境において膨大な試行錯誤が必要であることが挙げられる。例えば、ある特定のタスクを学習させるだけで現実世界で数万、数十万回の試行錯誤が必要となると、試行失敗によってハードウェア破損や安全リスクが発生しうるロボティクス分野なんかではあまりに使いにくい。
このような背景のもとで強化学習のサンプル効率向上のために様々な研究が行われており、有望なアプローチの一つとしてデータ駆動で環境シミュレータを構築する「世界モデルベースの強化学習」というものがある。世界モデルとは現実世界の挙動(状態遷移)を深層学習により再現した疑似シミュレータである。現実世界ではなく、疑似シミュレータ上での試行錯誤であれば数十万回、数百万回の失敗を重ねようと(計算リソース以外には)何のリスクもコストも発生しないためにサンプル効率の課題を踏み倒すことができるからだ。

世界モデルベース強化学習とは
一口に世界モデルと書いたが、実際には強化学習における「世界モデル」とは、「視覚ベースの世界モデル」と「潜在変数空間ベースの世界モデル」の2つのアプローチが存在する。
前者の「視覚ベースの世界モデル」とは人間が視覚的に理解可能な形式で将来予測を行う環境シミュレータであり、技術的には行動で条件づけされた動画予測モデルと理解できる。代表的な手法としてDreamerシリーズやDIAMONDなどが挙げられる。

https://diamond-wm.github.io/
一方で、後者の「潜在変数空間ベースの世界モデル」とは人間が理解できない潜在変数空間上で将来予測を行う環境シミュレータであり、技術的には広義の状態空間モデルと理解できる。代表的な手法として、MuZeroやTD-MPCなどが挙げられる。
MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind
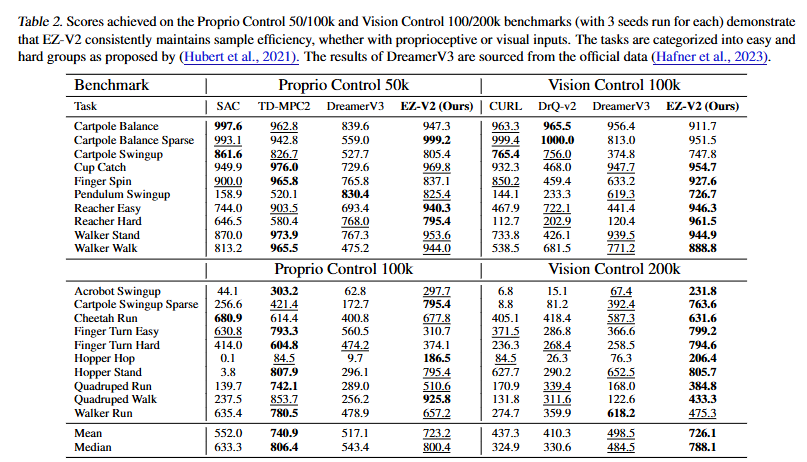
どちらの世界モデルアプローチも盛んに研究されているが、今のところ「視覚ベースの世界モデル」は解釈性と転移性(基盤モデル化)に強みがある一方で、「潜在変数空間ベースの世界モデル」は単純性能に強みがあるように見える。実際、主要なサンプル効率ベンチマークでは、「潜在変数空間ベースの世界モデル」であるEfficientZeroV2(MuZeroの子孫で画像入力タスクに強い)およびTD-MPC2(センサー入力タスクに強い)が「視覚ベースの世界モデル」であるDreamerV3と比較して、多くのタスクで優れたパフォーマンスを発揮している。
本稿ではMuZeroをサンプル効率特化に進化させた手法であるEfficient ZeroV2の理解と実装を行っていく。
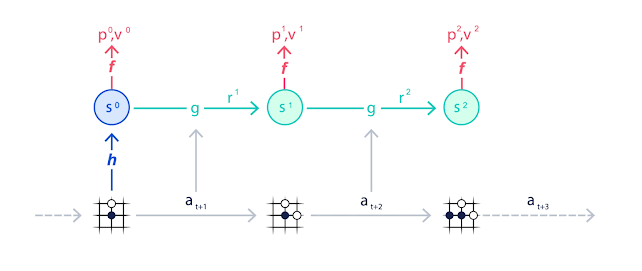
前提手法 MuZero: 潜在変数空間上での木探索
まずはEfficientZeroV2の前提となっている、潜在変数空間ベースの世界モデルの代表的な手法であるMuZeroについて簡単に確認を行う。
MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind
MuZeroは木探索アルゴリズムであるAlphaZeroを拡張した手法である。AlphaZeroは囲碁/将棋で知られる強力なアルゴリズムだが、木探索アルゴリズムゆえに環境のダイナミクス(状態遷移のルール)が完全に既知の系でしか使えないというつらさを抱えていた。そこで、AlphaZeroに環境ダイナミクスの予測機能(=潜在変数空間ベースの世界モデル)を導入することであらゆるタスクを木探索で解けるようにしたのがMuZeroというわけである。
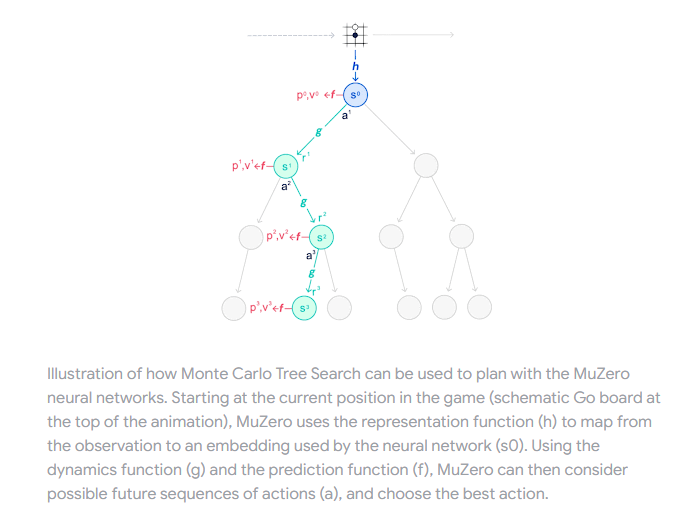
わかりやすく言うと、AlphaZeroはボードゲームなど状態遷移ルールが明示的に与えられているタスクにしか適用できなかったが、MuZeroはビデオゲームやロボット操作など状態遷移ルールが明示的に与えられていないタスクにも適用できるようになった。
MuZeroは単純な性能だけ見ても深層強化学習の最強手法の一つと言えるが、特筆すべきはサンプル効率の良さである。すなわち、MuZeroは潜在変数空間ベースの世界モデル上でのイメージトレーニング(imaginary rollout)を行うことにより、実環境での試行錯誤の回数を大きく減らすことに成功した*1。スポーツの効率的な上達には試合をこなすだけでなく振り返りも大事、と喩えたらわかりやすいだろうか?
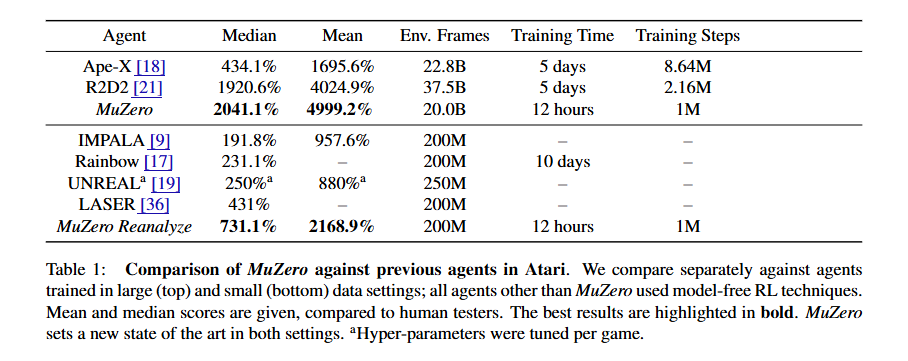
EfficientZeroV2:MuZero派生の全部盛り
EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data
MuZeroは斬新かつ強力な手法である一方で、多くの研究余地が残されていたため様々な観点での改良手法が提案されることとなった。余談だけれども、何かのコラムで「エポックメイキングな論文がブルドーザーのように道を切り開き、後追いの研究者は残された石を拾って道を舗装する」と表現されていた方がいた*2。MuZeroはまさにそういう手法だったと思う。
本稿で実装するEfficientZero V2はそのように様々提案されたMuZeroの派生から以下の3手法をまとめあげたものであると表現できる。
EfficientZero: SimSiamスタイルの自己教師あり表現学習の導入によりMuZeroのサンプル効率を大幅に改善
Gumbel MuZero: 行動選択を担うバンディットアルゴリズムの改良によりシミュレーション回数が少ない場合でも方策改善を保証
Sampled MuZero: 離散アクションにしか対応できなかったMuZeroを連続アクションタスクにも対応できるよう拡張
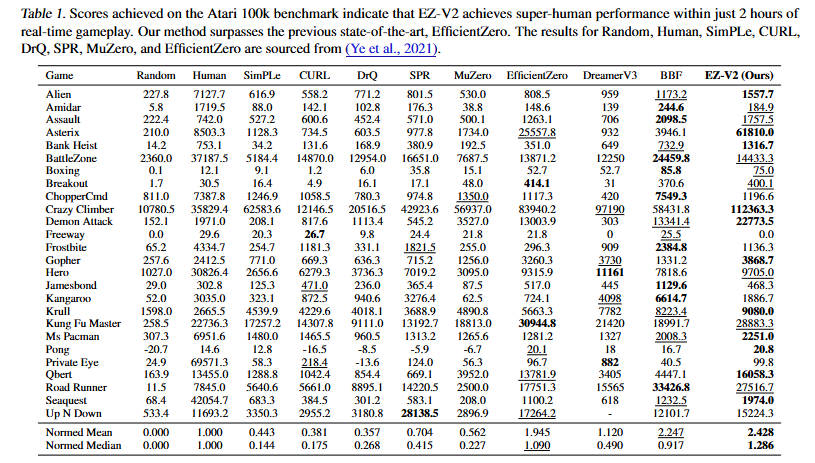
このようなRainbow的な全部盛りアプローチに加えて、Search based Value Estimation (SVE) というオフライン学習を頑健にするトリックの提案により、EfficientZeroV2は主要なサンプル効率ベンチマークにおいて、以下の図に示すようなつよつよ性能を実現することとなった。
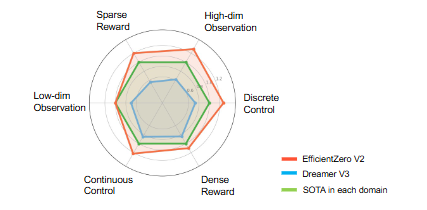
EfficientZeroV2の実装
公式実装:EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data
Tensorflowで再現実装を行った。ただし、重すぎる計算負荷を軽減するためにいろいろな簡易化を入れたことにより完全な再現とはなっていない(具体的な内容はREADMEを参照)。実環境での試行錯誤コストよりも計算コストのほうがはるかに安いという思想は全くもってその通りなのだが、趣味でやってる身としてはマルチGPUが前提になっている手法というのはなかなかつらいものである。
アタリのような離散アクション環境の場合だと実装はMuZeroとさほど変わりないのだが、手法追加による変更点となっている①Gumbel-MCTSと②自己教師あり学習ロスあたりが解説ポイントだろうか。
実装全文:
github.com
① Gumbel-MCTS
POLICY IMPROVEMENT BY PLANNING WITH GUMBEL
MCTSについて、MuZeroと考え方の枠組み自体は大きく変わっていないが、Gumbel-Sequential Halving アルゴリズムの導入により、ルートノードにおけるバンディットアルゴリズムでの行動選択方法が大きく変更されている。
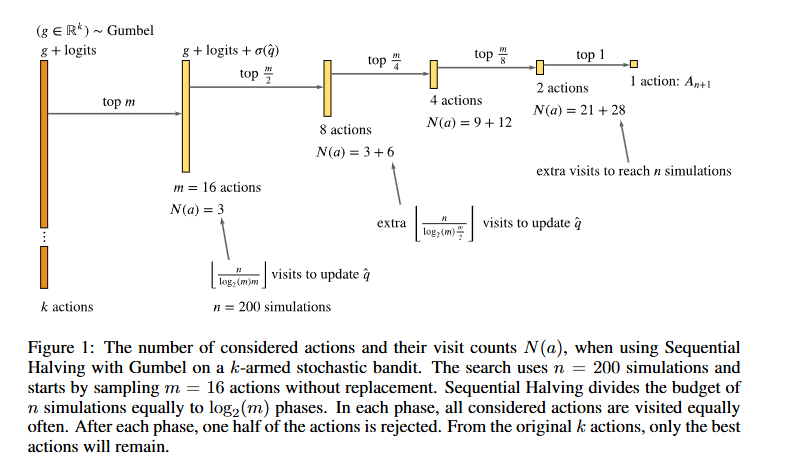
Gumbel MuZeroの行動選択を一言で表現するならサドンデス方式でのバトルロワイアルだ。一定回数のシミュレーションが完了するごとに各行動のスコア(=事前方策+Q値)を比較して、スコア下位半数の行動を脱落させることを繰り返す。なお、スコアにはGumbel分布から発生したノイズを乗せることである程度の探索力を持たせる。
このような行動選択方式をとることにより、シミュレーション回数がアクション回数より少ない場合であっても方策改善が保証されるらしい。ちなみにGumbel-MCTSの著者にはDavid Silverが入っている。
② SimSiamスタイルの自己教師あり学習
Mastering Atari Games with Limited Data
強化学習において、経験再生(Experience Replay)はサンプル効率を向上させるための定石だがやりすぎると過学習に陥ってしまう。しかし、EfficientZero(V1)は、SimSiamスタイルの自己教師あり学習の導入が過学習を防止するため(過剰に経験再生してもよくなるので)サンプル効率を大きく向上させることが可能であることを示した。
基本的にはSimSiam以上でも以下でもないのだが、一般的なSimSiamでは元画像xと画像加工されたx'のコサイン類似度を最大化するのに対して、EfficientZeroではダイナミクス関数によって予測されたS_t+1と実際のS_t+1のコサイン類似度を最大化するのが重要な違い。ちなみに、同様のアプローチは Data-Efficient Reinforcement Learning with Self-Predictive Representations などでも成功している(こっちはSimSiamでなくBYOL)。
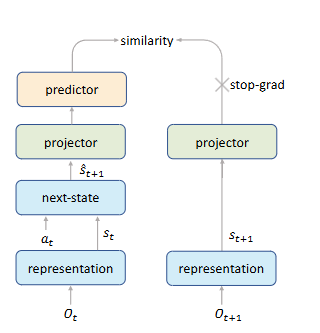
学習結果
GPU一枚(T4)で3日間学習を行った結果、100Kステップで120点くらいといい感じのスコア。計算負荷軽減のために簡易化入れていることもあって論文掲載スコアである400点よりはだいぶ低いが、スコアがサチっている感じもないし検証としては十分なスコアかと思う。計算資源不足でシンプルに勾配更新回数が足りていないのだ。
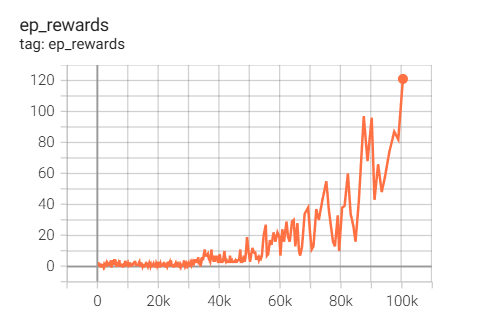
Reimplementation of EfficientZeroV2 (Atari Breakout 100K).
— めんだこ (@horromary) May 24, 2025
While I couldn’t fully reproduce it due to limited computational resources, it still delivered impressive performance with just 100K frames — one of the most sample-efficient RL methods. pic.twitter.com/s2XpLPAQKD
重すぎる計算負荷を軽減するためにいろいろな簡易化を入れたうえで、それでもたった100Kステップに三日かかっていることから計算量のやばさを察していただきたい。
次:??
LLMでのアシストとかかな。