マルチエージェントシステムによる研究仮説提案(AI共同科学者)論文を読んだメモ。
※本記事のすべての画像は以上のリンクが出典
- GoogleのAI co-scientist(AI共同研究者)
- マルチエージェントによる仮説提案フロー
- 具体事例:急性骨髄性白血病(AML)に対するドラッグリポジショング
- 今後の方向性:ツール連携の強化
- ポエム: 研究開発組織はAIの知能ではなく泥臭さに敗北する
GoogleのAI co-scientist(AI共同研究者)
研究仮説提案のためのマルチエージェントシステム
2025年2月にGoogle&DeepMindが発表した"AI co-scientist"(AI共同科学者)では、「新規性」と「妥当性」を両立した研究仮説立案をLLM(大規模言語モデル)によって遂行するマルチエージェントシステムを提案している。

新規性の無い研究仮説を検証する価値はなく、妥当性の低い研究仮説は投資対効果に見合わない。ゆえに「新規性」と「妥当性」のトレードオフへのバランス感覚を備えたAI共同科学者は、経済的合理性を無視できない民間企業での研究開発において重要な役割を担う可能性が高いと見込まれる。
これは別に「人間の研究者の仕事がAIに奪われる!」ということを言いたいのではなく、単純に研究テーマ設定という何千万、何億円規模の投資の意思決定においてAIを利用しない理由が無いというだけだ。
ランクマッチ対戦による仮説の「新規性」「妥当性」改善ループ
LLMと文献検索の組み合わせにより、AI生成された仮説について「新規性」と「妥当性」のあり/なしだけ検証すること自体はいまやそれほど難しいタスクではない。すなわち、過去の文献すべてと突合して新規性があるか、過去の報告と矛盾がないかをLLMに検証させればよい。
難しいのは複数の提案仮説の中でどの仮説がもっとも「新規性」と「妥当性」を両立しているかを定量的に判断することだ。この問題の解決のためにAI共同科学者はランクマッチアルゴリズムによる提案仮説トーナメントを導入する。

ここでランクマッチ*1とはオンライン対戦ゲームでしばしば使用される順位決めアルゴリズムのことである。この方法では近い実力のプレイヤー同士でのマッチングを繰り返すことにより、少ない対戦回数で効率的に妥当な全体順位を推定することができる。同様に、複数の仮説の良さをいきなり順位付けすることは難しくとも、2つの仮説のどっちのほうが良さそうかという2択であれば判断容易であることを利用し、AI共同研究者では仮説を1対1で戦わせ続けることで仮説の妥当な全体順位を推定する。つまりは"俺より強い仮説に会いに行く"。
AIによる仮説提案の既存研究は多いが、大量の生成仮説を全体感を持ってマネージする仕組みがないゆえに結果の不確実性や視野狭窄の問題を抱えており実用レベルに到達していなかった印象がある。一方で、AI共同科学者はランクマッチ方式の導入により大量に生成された提案仮説から有望な仮説を選別し、全体感を更新し、次の仮説生成につなげる改善ループを実現する。とても巧い仕組みだ。
創薬分野の3事例において有効な仮説提案に成功
Towards an AI co-scientistによるとAI共同研究者は単なる机上のアイデア提案ではなく、すでに創薬分野の3事例において実験的に有効性が確認された仮説提案に成功しているとのこと。ウェット実験への誠実さはDeepMindの美点だ。
急性骨髄性白血病(AML)に対するドラッグリポジショニング:既存薬剤からAMLに対して有効な可能性のある新規候補薬を複数提案、in vitroにおいて腫瘍の生存能力を阻害することを示した
肝線維症の新規治療標的の発見: 肝線維症治療のための3つのエピジェネティック修飾因子およびそれを標的とする4つの薬剤を提案、ヒト肝臓オルガノイドにおいて抗線維化活性を確認
抗菌薬耐性メカニズムの説明: 細菌の進化における新規遺伝子導入メカニズムについて、未発表(査読中)論文の新規仮説を再現することに成功
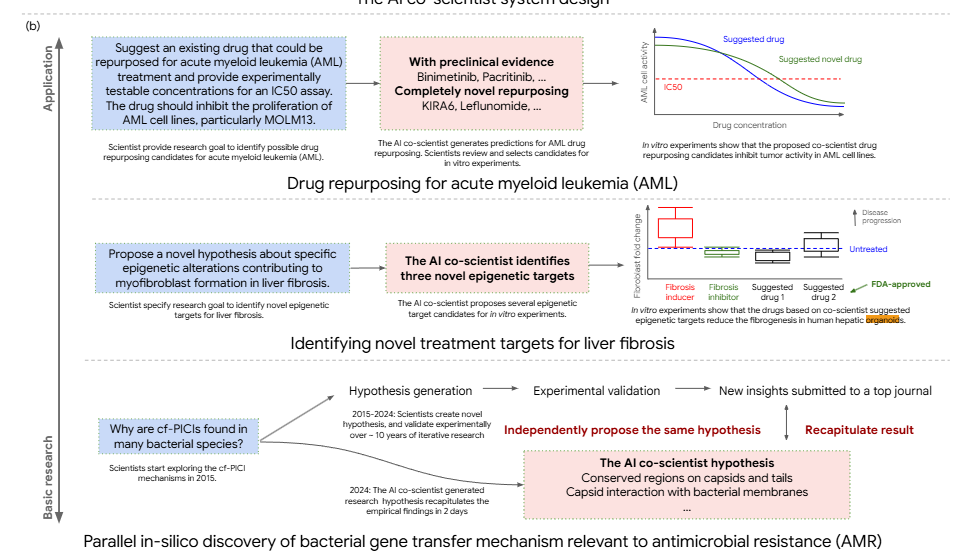
ドラッグリポジショニング(あるいはドラッグリパーパシング)と治療標的発見については製薬会社にとって垂涎の応用事例だろう。実用的なレベルでこれができるなら調査一回のコストが数百万円でも安い。ここで恐ろしいのはAI共同科学者は創薬特化LLMを一切使用せずGemini2.0のみで新規仮説提案を実現していること。つまりは製薬会社はその気になれば明日にでもAI共同科学者の再現実装を開始することができるのだ。
マルチエージェントによる仮説提案フロー
7人のAIエージェント
研究目的を与えられたAI共同研究者システムは①仮説の生成、②仮説の順位付け、③仮説探索方針の策定の3ステップを繰り返すことで提案仮説を改善させていく。このプロセスでは異なる役割を持つ7つの専門AIエージェントによる協働が行われている。
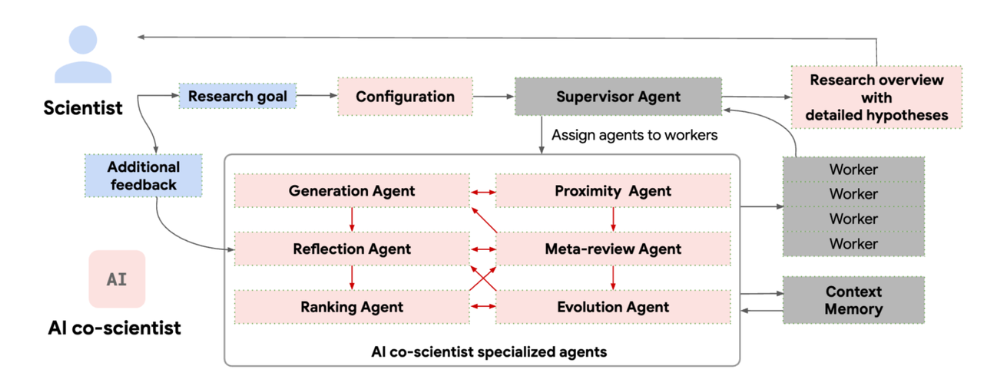
以下に各専門エージェントの名称と役割を示す(日本語名は適当な意訳)。各専門エージェントのプロンプトはTowards an AI co-scientistのAppendixに記載があるので興味があれば参照されたし。
- 生成エージェント(Generation agent):
- 文献探索や模擬議論、条件付き推論など様々な手法を用いて新たな仮説を生成
- 査読エージェント(Reflection agent):
- 査読者のように批判的な視点から、生成された仮説の妥当性、新規性を評価
- 順位付けエージェント(Ranking agent):
- Eloベースのトーナメント(≒ランクマッチ)での対戦において仮説の相対的な優劣を判断
- 近接エージェント(Proximity agent):
- ランキング内の仮説について類似性に基づいたクラスタリングを通して仮説の多様性向上を促進
- 進化エージェント(Evolution agent):
- 上位にランク付けされた仮説を洗練し、精度を向上
- メタレビューエージェント (Meta-review agent):
- レビューや議論のパターンを分析し研究計画へのフィードバックを生成
- 監督エージェント (Supervisor agent):
- 研究目標に基づいて、各エージェントのタスクを定義し、実行順序を決定
- 各エージェントの処理状況を監視し、必要に応じてタスクの優先順位を変更
- メタレビューエージェントからのフィードバックを各エージェントに伝達し、学習と改善を促進
- 最終的な研究計画をまとめ、人間の専門家(研究者)に提示
こう見ると監督エージェントのやることが多い。管理職は大変だな。
①仮説の生成
担当: 生成エージェント
初期仮説は生成エージェントにより、4つのアプローチで構築される(仮説の出力例)。
- Web文献検索:
- 時系列に沿って関連文献の要約とレビューを実施、その結果に基づいて新たな仮説を提案。プロンプトはシンプル。
- 模擬議論:
- LLM同士でディスカッションを行い仮説を洗練。こちらもシンプルなプロンプト。
- 仮説の分解:
- 提案仮説を検証可能なサブ仮説に分解し、研究・実験計画をデザインする。仮説の出力例で言うと”Experimental design and validation”を作ってるのだと思われる。
- 仮説の拡張:
- 既存研究のサマリおよびメタレビューエージェントからのフィードバックに基づき、有望そうだが研究が不十分な領域にあたりをつける。

生成エージェントにトリッキーな要素は無い。”関連文献を時系列的・網羅的にレビューして既存知見をまとめる”、”既存知見から示唆を抽出し議論を通して洗練する”、”検証可能な仮説としてデザインする”という研究者として至極真っ当なことをやっているように見える。
②仮説の順位付け
担当: 査読エージェント、ランキングエージェント、近接エージェント
生成された仮説はまず査読エージェント(Reflection agent)により多段階の徹底的な検証が行われる。既存知見との矛盾がないか、新規性があるかといった批判的検証はもちろん、仮説の根拠を強化できる関連文献がないかを検索するなど協力的な検証も行われる。
査読が完了した仮説はランクマッチトーナメントに投入されElo ratingによって順位付けされる。
イロレーティング (Elo rating) とは、対戦型の競技(2人のプレイヤーまたは2つのチームが対戦して勝敗を決めるタイプの競技)において、相対評価で実力を表すために使われる指標の一つ。数学的裏付けのある最も著名なレーティングシステムである。(wiki)
ランキングエージェントは仮説同士の対戦(複数ターンの科学的議論)における勝敗判定を担う。ランキングエージェントの出力例を見るとわかりやすいが、OpenReviewっぽいことをやっている。

ここで、近接エージェント(Proximity agent)は仮説ランキングの多様性向上のために補助的な役割を担う。すなわち、類似性にもとづいたクラスタリングにより仮説の多様性を促進する、対戦ににおいて類似した仮説同士でのマッチングにより重複排除を促進することなど行う。
③仮説探索方針の策定
担当: メタレビューエージェント、進化エージェント、監督エージェント
メタレビューエージェントはこれまでの各仮説のレビュー/議論の要約から、共通の論点を特定してメタレビューを作成する。メタレビューは探索方針策定において中心的な役割を担う。
進化エージェントはメタレビューで特定された問題点を考慮し、既存の仮説から新しい仮説を生成する/複数の仮説を組み合わせる/視点を変えるなどの方法でより洗練された仮説を作成する。
Appendixを見ると進化エージェント用のプロンプトは、フィージビリティ向上/斬新なアイデア提案など用途別に複数用意されているようだ。

監督エージェントはメタレビュー(など)に基づいて各エージェントへのリソース割り当て優先度を調整しシステム全体の動作を最適化する役割を担う。
このように、メタレビューエージェント、進化エージェントそして監督エージェントの協働体制が全体感を踏まえた仮説生成と改善を実現する仕組みを提供する。
具体事例:急性骨髄性白血病(AML)に対するドラッグリポジショング
※ 4.5.2 The AI co-scientist identifies novel drug repurposing candidates for acute myeloid leukemiaのAI要約
AI共同科学者による仮説提案:
- 探索範囲は33種類のがんに対する2,300の承認済み薬剤に限定
- このため「生成エージェント」および「ランキングエージェント」 のプロンプトを調整し、制約された検索空間内で仮説生成するように設定
- 仮説の最終順位付けでは計算生物学解析(
DepMapスコア)の結果も考慮
- DepMapスコア:特定のがん細胞株で、その遺伝子がどれほど必須であるかを確率的に表す指標
薬剤候補の選定(5種類):
AI共同科学者によって提案されたトップ30の薬剤候補仮説は専門の腫瘍学者と共有され、ウェットラボ実験に進める ドラッグリポジショニング候補の選定のための評価が実施されました。 結果として以下の5つの薬剤が、AMLにおける作用機序の可能性 に基づいてウェットラボ検証の対象として選ばれました。
- Binimetinib(MEK1/2阻害剤)
- RAS/RAF/MEK/ERK経路 を阻害し、NFκB(核因子カッパB) の活性を低下させる可能性。
- MEK阻害により、IKK複合体の破壊を介してNFκBの恒常的活性化を抑制し、AML細胞の増殖・生存シグナルに影響を与える。
- STAT3やc-Mycなどの転写因子 を制御し、AMLの再発リスクを低減できる可能性。
- Pacritinib(JAK2/FLT3二重阻害剤)
- STAT3/5を活性化 し、NFκBを介して炎症性サイトカインの産生やPI3K/AKT経路の活性化 に関与。
- FLT3阻害により、AML細胞の生存を維持する耐性経路の発達を防ぐ。
- Dimethyl fumarate(DMF)
- Cerivastatin(スタチン類)
- Pravastatin(スタチン類)
- 代謝・炎症リプログラミング を誘導し、急速に増殖する細胞の小胞輸送に直接影響を与える可能性。
in vitroでの検証結果:
5種類の薬剤をin vitroで検証 した結果、以下の3種類の薬剤が細胞生存率の抑制 を示した。
- Binimetinib
- Pacritinib
- Cerivastatin
特に、Binimetinib(転移性メラノーマ治療薬として承認済み) は、AML細胞に対して IC50 = 7 nM という非常に強い阻害効果を示した。
今後の方向性:ツール連携の強化
汎用性の実証を優先し現在のAI共同科学者のツール連携は基本的にはWeb検索のみのようだが、必然的な発展の方向性として各種研究ツールとの連携が考えられる。実際、論文内でもiPS細胞の重要因子であるOCT4(オクタマー結合転写因子4)タンパク質の配列最適化の提案をAlphaFoldで評価する例が示されている(Appendix 5)。
分子動力学計算ソフトウェアと連携すればリガンド構造の最適化ができるだろうし、SciFinderやReaxysと連携すれば最適な合成経路を考えてくれるだろう。このようにドライのタスクがAIで加速すると今度はウェットの実験がボトルネックになってくる。数年後のトレンドはAI×ロボティクスによる自動実験だろうか。
ポエム: 研究開発組織はAIの知能ではなく泥臭さに敗北する
担当者の好き嫌いや成功体験が優先されて過去文献の調査すら不十分なまま走り出した研究テーマが、その半年後に過去研究から筋悪が判明してポシャるとか、他社特許を思いっきり踏んでることを指摘されてピボットするなんてことは大企業の研究開発組織あるあるなんじゃないかと思う。
一方、AI共同科学者は関連する過去文献すべてを徹底的に調査し、考えられる仮説を抽出し、批判的思考による価値検証するサイクルを無数に繰り返すことで研究テーマを進化させていく。あまりにも真っ当で誠実な仮説構築プロセスだ。しかし、こんな泥臭いプロセスをやり切れる研究開発組織はどれだけあるのだろうか?
現時点のAI共同科学者の「知能」(主に論理的思考力)が人間の研究者を超えているとは思わない。しかし、その超人的な「泥臭さ」だけであっても研究開発組織に大変革をもたらしうるポテンシャルがあると感じた。
*1:わかりやすさのためにランクマと表現したが正しくはEloレーティング