強化学習におけるLLMの活用パターン調査
- はじめに:実世界における強化学習の課題
- LLM×強化学習
- 1. 報酬モデルとしてのLLM
- 2. 計画モデルとしてのLLM
- 3. 方策モデルとしてのLLM
- 4. 世界モデルとしてのLLM
- おわりに:VLM as 確率方策に期待
はじめに:実世界における強化学習の課題
レトロゲームで人間並みのパフォーマンスを実現したDQN (Deep Q-Network) から登場してわずか10年間で深層強化学習は驚くべき発展を遂げました。しかし、深層強化学習の実世界応用の成功例は一部の例外を除き*1、まだまだ限られています。
過去10年の研究成果として深層強化学習は適切な報酬設計のもとで十分な試行回数を確保することさえできればたいていのタスクを解けるレベルに到達しました。しかし、現実世界の課題で何万回もの試行錯誤を許容できるケースは少ないため、強化学習の実世界応用にはサンプル効率の向上(=必要な試行回数の削減)が重要な課題です。
LLM×強化学習
人間はゼロショット推論によりサンプル効率の良い学習ができる
「モンテスマの復讐」は悪い報酬設計の問題と探索困難環境の問題が悪魔合体したことにより、Atari環境最難関の呼び声高いゲームの一つです。

スパース報酬(鍵をとるまで報酬発生しない)かつランダム探索困難(段差から落ちただけで死ぬ)*2という特徴をもつために、深層強化学習の先端手法(Agent57など)ですら人間レベルのスコアに到達するために何万回の試行錯誤が必要(=サンプル効率が劣悪)です。
対照的に、人間は「鍵をとれば扉が開くだろう」というゼロショット推論にもとづき、目的を達成するために必要な行動を数十回の試行錯誤で見つけ出すことができます。このような高度なゼロショット推論能力を強化学習アルゴリズムに組み込むことが、サンプル効率(=学習効率)を高める鍵となるはずです。
LLMによるゼロショット推論の例
一つの有望なアプローチは、LLMの強力なゼロショット推論性能と強化学習アルゴリズムを融合させることです。
実際に「モンテスマの復讐」を例にしてLLMのゼロショット推論能力を試します。画像入力に対応したLLM(正確にはVLM)であるChatGPT-4Vにこのゲームを探索戦略を尋ねてみました。

驚くべきことにChatGPT-4Vはいっさいの試行無しで「鍵を取得する」「障害物を避ける」というモンテスマの復讐における重要な探索指針を見つけ出すことに成功しています。この単純な事例からも、LLMが仮説を示し、強化学習でそれを検証するという融合アプローチの有望さがわかります。
さまざまなLLM活用パターン
「モンテスマの復讐」ではLLMを計画モデルとして使用しましたが、強化学習におけるLLMの活用方法として様々なアプローチが検討されています。
- 報酬モデルとしてのLLM:LLMに報酬を決めさせることで柔軟な報酬モデルを実現
- 計画モデルとしてのLLM:LLMによる強力なゼロショット推論を利用した探索
- 方策モデルとしてのLLM:LLMによる直接的な行動決定
- 世界モデルとしてのLLM:LLMによる環境ダイナミクスの予測
本稿では、これら強化学習へのLLM活用アプローチに関する研究動向を調査しました。
1. 報酬モデルとしてのLLM
深層強化学習では、報酬モデルの設計が重要ですが、目的が抽象的なタスクではルールベースでの適切な報酬モデル設計は容易ではありません。この問題を解決するために、報酬モデリングにLLMを活用する新たなアプローチが注目されています。
LLMによる代理報酬モデル
たとえば「人狼」のような対人交渉が重要なゲームでは、ルールベースの報酬設計は困難ですが目指すべき状態を言語化することは比較的容易です。そのようなタスクにおいては人間の感覚的な「良かった/悪かった」という評価をLLMで模倣することで、LLMを代理報酬モデルとして利用することができます。
[2303.00001] Reward Design with Language Modelsでは、テキストベースのタスクを用いて強化学習向け代理報酬モデルとしてのLLMのポテンシャルを評価しました。

結果、LLMによる代理報酬モデルを用いたRLエージェントはタスクの意図に沿った優れたパフォーマンスを示しました。テキストベースタスクに限定された結果ではありますが、LLMを報酬モデルとして活用する方向の有望性を示しています。
VLMによる外観ベース代理報酬モデル
ルールベースで適切な報酬関数を設計することは困難だが目指すべき状態を視覚的に判断することは容易であるという状況も、ロボット制御分野などではしばしば発生します。たとえば「ヒューマノイドロボットが180度開脚」というゴール状態をルールベースで評価することは難しいですが、視覚的に良さを判断することは容易です。このような場合、Vision & Language Model(VLM)を代理報酬モデルとして活用することができます。
[2310.12921] Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning では、テキストで定義したゴール状態(例:"a humanoid robot kneeling" )と現在の状態(画像観測)をCLIPでエンコードし、コサイン類似度にもとづいて報酬を決定するというアプローチを提案しています。

この研究ではVLMのモデルサイズが大きくなるほどより優れた代理報酬モデルが得られるというスケーリング効果が確認されたことも重要なポイントです。マルチモーダルLLMの今後の発展はほぼ確定路線であるため、このアプローチは今後さらに有用性を増していくことが期待できます。
外部知識にもとづく報酬モデル設計
通常の強化学習ではエージェントは環境についての事前知識なしに訓練されます。しかし、もしタスクの説明書/マニュアルが利用可能ならそれを使うことで強化学習アルゴリズムのサンプル効率が向上することは直感的にも明らかです。
[2302.04449] Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals では、Atariのゲーム環境でLLMを用いて説明書にもとづく補助報酬モデルを導入することで、SOTA手法と比べて1000倍のサンプル効率改善に成功しました*3。

この手法では、まずLLM(とTF-IDF)を利用して ①説明書から「ゲームの目的」と「主要なオブジェクト間のインタラクション」に関するQA集を作成 します、次に ②QA集の回答(Yes/No)にもとづいてゲーム内の特定のイベント(上図 Skiingの例では木とプレイヤーの衝突に-5のペナルティ報酬など)に補助報酬を割り当てます。これにより、外部知識にもとづいた探索の効率化を実現することができます。
2. 計画モデルとしてのLLM
複雑な大目標を達成するためには、それをより簡単で具体的なサブ目標に階層的に分割して段階的に解いていくというのが多くの場合に効率的*4 です。これをLLMを行わせることで強化学習のサンプル効率向上が期待できます。
LLMによるセマンティック計画
LLMは抽象的な大目標をサブタスクに分割することに長けています。この能力を活用し、LLMをサブタスクレベルの指示を行うセマンティックコントローラとして使用し、強化学習エージェントがこれらのサブタスクを実行するという枠組みが有望です。
GoogleとEveryday Robotsから発表された PaLM-SayCan はまさにそのような役割分担をロボティクスにおいて実現した手法となっています。

たとえば「私はカフェイン入りのソーダが好きではありません、ほかに何か飲み物を持ってきてもらえますか?」という指示であれば、まずLLMがこの抽象的な指示を解釈し、「水を見つける」というサブタスクに変換します。つづいてロボットは模倣学習によって習得した動作スキルを用いてこのサブタスクを遂行します。*5
SayCanではサブタスク遂行のために模倣学習によってロボット動作スキル獲得を行っていますが、Microsoftの ChatGPT for Robotics ではサブタスク遂行のための動作スキルのコードをLLMで生成することにより、LLMのみで完結する自律エージェントを提案しています。

同様に、Minecraft環境においてもVoyager | An Open-Ended Embodied Agent with Large Language ModelsがChatGPT for Roboticsと同様に生成的コーディングによってサブタスクを遂行するアプローチで成果を上げています。

LLM×ロボティクスにおいて生成的コーディングと強化学習/模倣学習のどちらが主流になるのかは今後の動向に注目です。
LLMによる構造的な探索計画
強化学習の劣悪なサンプル効率の一因となっているのは非効率なランダム探索(ε-Greedy や エントロピー方策)です。ここ数年で「内発的報酬(好奇心駆動探索)」などランダム探索に指向性を与える手法が提案されていますが、これら手法でさえも中心にあるのはランダム探索です。
そこで、[2302.06692] Guiding Pretraining in Reinforcement Learning with Large Language Models では、現在の状態にもとづいてLLMに動的にサブ目標を提案させ、エージェントがLLM提案サブ目標に従った場合に追加報酬を出すことで指向性のある探索を実現しました。


従来の内発的報酬アプローチでは状態の新規性によって追加報酬が発生するのに対して、この手法ではLLMの提案した仮説が検証されることによって追加報酬が発生するような仕組みなっているため、常識力(ゲーム慣れ?)の要求されるタスクにおいてLLMのゼロショット推論に基づいた効率的な探索が可能となっています。
3. 方策モデルとしてのLLM
LLMは一般的な状況における常識的な判断力を備えているために、単純なタスクであれば追加学習なしでも妥当な行動決定が可能である=方策モデルとして使えることが期待されます。
LLM as 確率方策
強化学習/方策勾配法における方策モデルの要件は現在状態を受け取り、次行動の確率分布”を出力する微分可能なモデルであることです。ここで、GPTアーキテクチャは現在までの文脈を受け取り、②次単語の確率分布を出力する微分可能なモデルであるため、GPTは方策モデルとしての要件を完全に満たしています。
[2302.02662v2] Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning ではLLM(FLAN-T5)を確率方策モデルとして使用し、強化学習(PPO)を行うことによりサンプル効率が大きく向上することを報告しました。


このアプローチでは、以下の手順に従って行動決定を行います。
タスクの目的、現在の状況および可能なアクションをテキストで表現
テキストをLLMに入力し各アクションの選択確率を算出
算出した確率分布からアクションをサンプリングすることで次行動を決定
この方法で収集したサンプルを用いて、通常の強化学習(方策勾配法/PPO)によりネットワーク更新を行います。従来のオンライン強化学習の枠組みから外れずにLLMを活用するシンプルで強力なアプローチと言えます。
マルチモーダルLLM as 確率方策
LLM as 確率方策のコンセプトをマルチモーダルLLM(Vision & Language Model, VLM)に転用すればテキストと視覚情報が両方そなわり最強にみえる。
Appleの論文Large Language Models as Generalizable Policies for Embodied Tasksでは、協調ロボティクス環境でVLM as 確率方策のコンセプトをすでに実現しています。
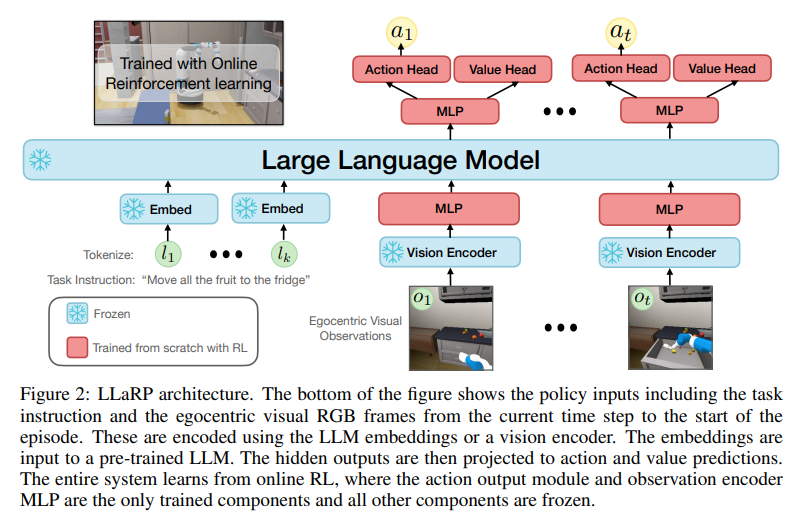
VLM as 方策モデルでも大幅なサンプル効率の向上と抽象的で動的なタスク(指示)への適応に成功。こちらもネットワーク更新はPPO(の派生手法)を採用しています。
参考:GPTアーキテクチャの転用
GPTのネットワーク構造を条件付き模倣学習に転用する手法がオフライン強化学習分野で近年注目されています。
4. 世界モデルとしてのLLM
LLMは一般常識を備えており、ニュートン力学的な世界の理解も獲得しているためある程度の将来予測が可能です。これはLLMを強化学習の文脈における「World model」として利用できる可能性を示唆しています。

Language Models Meet World Models (あとで書く)
NeurIPS 2023のチュートリアル「Language Models Meet World Models」の内容をまとめる予定
おわりに:VLM as 確率方策に期待
様々な観点からLLMと強化学習の融合研究を調査しましたが、LLM as 方策モデルは実装がシンプルかつ強化学習研究の過去資産をそのまま活用できるという点でもっとも有望に見えます。来年にはVLM as 方策モデルがAtariのサンプル効率SOTAになってそうです。
しかし、強化学習(RLHF)によってenpoweredされた大規模言語モデルが強化学習を飲み込もうとしているとはなんとも面白い状況ですね。
*1:最強AI「MuZero」とは ルールを知らないのにゲームで勝ちまくる:日経クロストレンド, 核融合炉を強化学習で制御する | 日経Robotics(日経ロボティクス)
*2:モンテスマはPOMDPの難しさもあるがここでは割愛
*3:SkiingタスクでAgent57との比較
*4:「階層型強化学習」などの枠組みでこのようなアプローチが検討されてきたが、ほとんどの場合サブ目標への分割がヒューリスティックであるため汎用性に課題