Implicit Q-Learningでは、maxQ(s,a)の評価を期待回帰(Expectile Regression)によって暗黙的に行うことでオフライン強化学習の困難の一つであるサンプル外アクション問題を回避します
オフライン強化学習シリーズ:
オフライン強化学習① Conservative Q-Learning (CQL)の実装 - どこから見てもメンダコ
オフライン強化学習② Decision Transformerの系譜 - どこから見てもメンダコ
オフライン強化学習③ Implicit Q-Learning (IQL)の実装 - どこから見てもメンダコ
オフライン強化学習④: 拡散モデルの台頭 - どこから見てもメンダコ
オフライン強化学習の困難
オフライン強化学習とは
オフライン強化学習とは実環境における試行錯誤を行わず、あらかじめ用意されたデータセットだけを用いて強化学習を行う手法です。実環境における試行=オンライン試行を行わないゆえにオフライン強化学習です。このオフライン強化学習は、たとえば医療ロボットや化学プラント制御など気軽な試行錯誤が許容されないドメインに強化学習を適用するためには非常に重要かつ有用なアプローチです。
しかし強化学習とはそもそも実環境における試行錯誤が暗黙的前提となっている理論のため、オフライン設定で強化学習を行うと様々な問題が発生します。大きな問題の一つは"サンプル外アクションの価値評価"の問題です。
サンプル外アクションの価値評価問題
TD学習において、ある状態sにおける状態行動価値Q(s, a)は次状態s'と即時報酬rを用いて下式のように表せるのですが、オフライン設定では右辺第二項のmaxオペレータが大きな問題を引き起こします。
状態行動価値の関数近似の利点でもあり欠点でもあるのは、任意の状態sと行動aについて、たとえ一度も試行していなくてもQ(s, a)を評価できてしまうことです。この性質とmaxオペレータの組み合せにより、max Q(s_t+1, a') で選択されるアクションa'は実際に試行されたアクションであることが保証されません。つまりは一度も試行したことが無いのに関わらず、想像だけでQ(s_t+1, a')は高い価値を持つと信じているエアプガチ勢状態です。結果としてQ(st, at)が過大評価されることとなります。
オンライン設定であれば、次の試行時にQ(s_t+1, a')が誤って高く評価されていたことに気付き修正が行われます。しかし、実環境での試行錯誤を行わないオフライン設定では根拠のない高評価が永遠に修正されず誤差が蓄積していくこととなります。
OoDアクション(Out of Distribution) の回避
以上の理由により、実環境での試行錯誤を伴わないオフライン強化学習では、データセット内に存在しない状態sと行動aのペア(s, a)の価値評価をいかにして回避するかが重要な論点となります。なお、このようなデータセットに存在しない=データセットを収集した方策が採用しなかったアクションについてOut of Distributionアクションと呼称されます。
有力なオフライン強化学習手法であるCQL (Conservative Q Learning)では、試行実績のあるQ(s, a)がつねに試行実績のないQ(s, a)よりも大きくなるようにQ学習の更新式を工夫することで間接的にOoDアクションを回避しました。実績最重視なので保守的なQ学習 (Conservative Q learning) というわけです。
また、GPTを使用するオフライン強化学習手法であるDecision Transformerは、そもそもが教師あり学習(条件付き模倣学習)であるためにOoDアクション問題を考える必要がありません。価値ベースのオフライン強化学習手法と比べてオンラインでの追加学習による性能向上の余地が小さいという欠点はあるものの、OoD問題に悩まされないというメリットの大きさからさまざまな派生手法が考案されています。
SARSAアプローチ
本稿で実装するIQL(Implicit Q learning)では、オンポリシーTD学習であるSARSAに近いアプローチを採用することによってOoDアクションを回避します。 オンポリシーTD学習であるSARSAでは、下式から明らかなようにデータセットを収集した挙動方策πβが実際に試行した状態, 行動のみを学習に用いるためにOoDアクション問題を考える必要がありません。
オンライン強化学習手法としては教科書以外ではあまり見ることがないSARSAですが、OoDアクション問題の影響を受けないためにオフライン強化学習としては強力なアプローチであり、タスクがシンプルかつデータセットに高パフォーマンスなトラジェクトリが十分に存在するような場合には十分にperformすることが期待できます。
一方で、オフライン設定のSARSAアプローチによって獲得されるQ関数は挙動方策πβに対する状態行動価値であり、最適状態行動価値ではないという点に限界があります。オフラインSARSAは模倣学習に近いため、良くも悪くもパフォーマンスがデータセットを収集した挙動方策に影響されすぎるのです。また、データセットを収集した挙動方策が単一ではない(多くの人によって収集されたデータセット)、という現実にありがちな状況に弱いことも深刻な問題です。
そこで、IQLではデータセット内サンプルだけを使ってmaxQ(s,a)を推定するトリックにより、Q学習のように最適状態行動価値を近似しつつもSARSAのようにOODアクション問題を回避すること目指しています。
Implicit Q learning:暗黙的なQ学習
下式はIQLの目的関数です。maxQ(s,a)にπβ(a | s)>0という制約がついていること以外はQ学習の目的関数と同じであることから、OoDを回避することさえできれば最適に近い状態価値関数が獲得できることが期待できます。

IQLでは、①状態価値V(s)は行動aに由来するランダム性をもつ確率分布であると考え、②V(s)の上振れ値を期待回帰によって評価することで、サンプル外アクションのQ(s, a)を直接評価せずにmaxQ(s,a)を算出するというエレガントなトリックを提案しました。
①状態価値V(s)は行動選択に由来するランダム性をもつ確率分布である
データセットにおいては、行動aが挙動方策πβという確率分布によって選択されているゆえに、状態価値V(s)もまた確率分布であると捉えることができます。このV(s)の分布形状を推定することができれば、その上振れ値とは最良のアクションを選択した場合の価値=maxQ(s,a)であると見なすことができます。よって、maxQ(s,a)の算出とはV(s)の分布形状推定の問題であると理解できます。
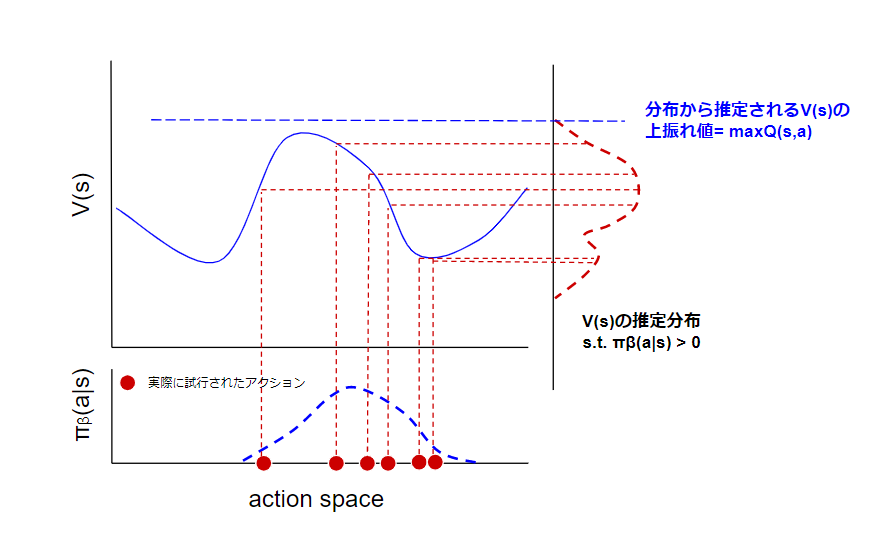
価値は確率分布であるというアイデア自体はC51やQR-DQNなどに代表されるようにごく一般的な考え方ですが、これらの手法では価値の不確実性は環境のダイナミクスに由来すると見なしています。一方、IQLでは価値の不確実性が行動選択に由来すると見なします。
②期待回帰(Expectile Regression)によるmaxQ(s, a)の暗黙評価
maxQ(s,a)の算出とはV(s)の分布形状推定の問題であると書きましたが実際には上振れ値だけがわかればOKなので、V(s)の期待値の(たとえば)99.9%分位の推定を行います。ここで分位点回帰(Quantile Regression)によりV(s)の上振れを推定するのではなく、期待回帰(Expectile regression)によりV(s)の期待値の上振れを推定することがポイント。分位点回帰でなく期待回帰を採用した場合には、分位を50%に設定するとIQLはSARSAと一致するためです。
エクスペクタイル(expectile)は(Newey and Powell 1987) によって導入された統計汎関数 (statistical functional; SF)の一種であり,期待値(expectation)と分位数(quantile)を合わせた概念である.簡単に言えば,中央値(median)の一般化が分位数(quantile)であるのと同様に,期待値(expectation)の一般化がエクスペクタイル(expectile)である.(Juliaで学ぶ計算論的神経科学より)(下記リンク)
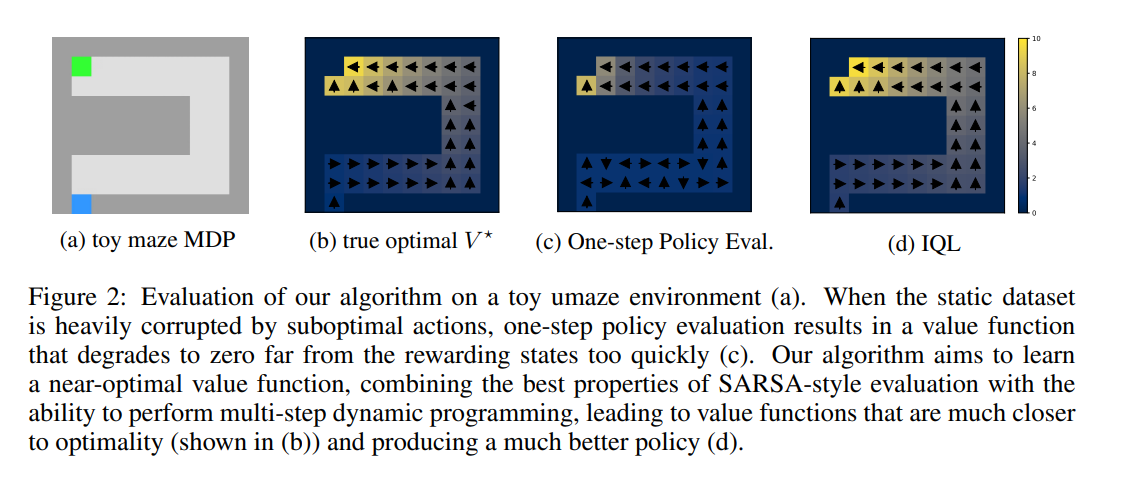
この期待回帰によって暗黙的にmaxQ(s,a)を評価するトリックによって、IQLはOoDアクションを回避できるというSARSAの良さを保ちながらもQ学習のように最適に近い価値関数を獲得できることが論文fig2に示されています。
TF2での実装
実装全文:
github.com
オフィシャル実装:
GitHub - ikostrikov/implicit_q_learning
Q関数の更新
実装としては状態価値のτ%上振れ値を評価する関数Vτ(s)とQ(s, a)は別関数として学習します。この結果、目的関数はQ学習におけるmaxQ(s,a)をVτ(s)で置き換えたものになります。

maxQ(s,a)をVτ(s)に置き換わっていること以外はQ(s,a)の更新は通常のQ学習と同じです。ただし、性能向上のためにTD3のClipped-Double-Q-Learningが採用されています。
期待回帰によるVτ(s)の実装もほぼ分位点回帰と同じなのでシンプルです。
Advantage weighted regression による方策抽出
連続値コントロール環境では価値関数だけでなく方策も訓練する必要があるので、Advantage weighted Regressionという手法でQ関数から方策を抽出します。AWRはβ=0の場合にはlogπ(a, s)を最大化するだけなので模倣学習に一致します。

基本は模倣学習だけどもオフライン学習したアドバンテージの大きさにもとづいて優先順位をつけるイメージ。こちらも実装は簡単。
学習結果
Gymのbox2d/Bipedalwalker-v3でテスト。オフラインデータセットはSoft-Actor-Criticで自作。BipedalWalker-v3は簡単すぎるのでIQLでなくただのSarsaでもうまくいくような気がする。なお当初はD4RLを使おうとしたがdeepmind版mujoco環境のセットアップに失敗した模様。

