MuZero = 状態遷移モデル+AlphaZero を簡単に解説しつつ、atari環境のBreakout(ブロック崩し)向けにtensorflow2での実装例を紹介します
Deepmind's MuZero (reimplementation for Breakout) #ReinforcementLearning pic.twitter.com/JWvnwFC1Om
— めんだこ (@horromary) 2021年8月3日
前提手法: Alpha Zero
horomary.hatenablog.com
DeepMind Blog: MuZero: Mastering Go, chess, shogi and Atari without rules
論文: Mastering Atari, Go, chess and shogi by planning with a learned model | Nature | arxiv版
MuZeroとは
MuZeroはゲームに関する一切の事前知識無しで囲碁・チェス・将棋において超人的パフォーマンスに到達することに成功した、AlphaZeroの後継手法です。AlphaZeroではゲームのルールブックが与えられていましたが、MuZeroではゲームのルールもまた学習の対象です。たとえばオセロで言えば「自分の石で相手の石を挟むと挟まれた石が裏返る」という盤面の状態遷移ルールまで学習します。
これによって古典ボードゲームのような盤面の状態遷移(ダイナミクス)が厳密にルール化されている系だけでなく、ビデオゲームのような状態遷移ルールが未知の系においてもAlphaZeroのアルゴリズムが適用可能になったため飛躍的に汎用性が高まりました。

MuZeroの高い汎用性を示すのが、囲碁・チェス・将棋と同じアルゴリズムでビデオゲームをプレイするという事実であり、しかもatari環境ではSotAを達成しています。さらにアルゴリズムを多少変更することでサンプル効率を飛躍的に高めることが可能であることも示されています。
高い汎用性とサンプル効率を備えるMuZeroはさまざまな現実の問題への応用が期待できる手法であり、実際すでにyoutubeのための動画圧縮手法開発への適用を検討しているとのことです。*1
※2022年2月:youtube動画圧縮についての続報が発表されました
deepmind.com
アルゴリズムの概要
モンテカルロ木探索
MuZeroのアルゴリズム自体はAlphaZeroとほとんど同じであり、モンテカルロ木探索による先読みシミュレーションに基づいて行動を決定します。

モンテカルロ木探索(MCTS)とはゲーム木の探索アルゴリズムです。ある盤面の「良さ」をその盤面から始まる無数のランダムプレイ試行によって評価することで効率的にゲーム木を探索していきます。AlphaZeroではこのモンテカルロ木探索に深層学習を導入することで探索性能を大きく改善することに成功しました。
スッキリわかるAlphaZero - どこから見てもメンダコ

上図に示すように、AlphaZeroのモンテカルロ木探索では盤面の状態遷移をルールブックを参照してシミュレートすることでゲーム木の探索を行い最適行動を決定します。これは言い換えると、盤面の状態遷移のルールがわからないような系ではAlphaZeroは適用できないということになります。状態遷移の仕組みが既知という状況はボードゲームならともかく現実ではそうありませんので、AlphaZeroが解決できる現実の問題というのはごく限られたものになってしまいます。
MuZero版モンテカルロ木探索
MuZeroもまたAlphaZeroのモンテカルロ木探索(PV-MCTS)をそのまま引き継いでおり、探索アルゴリズムそのものに変更はありません。ただし、AlphaZeroではゲームのルールブックに基づいて盤面遷移をシミュレートしていましたが、MuZeroでは盤面の状態遷移のシミュレートにおいてルールブックを参照しません。これは、MuZeroではニューラルネットによって盤面遷移の仕組み(≒ルールブック)を学習する仕組みを備えているためです。

MuZeroにおいて新たに導入され、盤面状態遷移のルールブックの役割を担うのがダイナミクス関数 g(s, a)→s' です。これは状態sと行動aを入力として遷移先の状態s'を予測するニューラルネットであり、その実体はほぼResNetです。ついでにatariのような即時報酬が発生する環境においてはR(s, a)も予測します*2。ルールブックに依存したくないならニューラルネットでルールブックを関数近似すればいいじゃない!というのは素直な発想ですが実現してしまうのがすごいですね、というか実現できちゃうんですね。
さらに、AlphaZeroでは現実の盤面状態のゲーム木を探索していましたが、MuZeroでは生の盤面状態ではなく表現関数 h(o)→s によって抽出された潜在変数空間*においてゲーム木を探索します。ダイナミクス関数と同じくこの表現関数も実体はほぼResNetです。ResNetで表現抽出→全結合層→P(s), V(s) の予測というネットワーク構造(図右)はAlphaZeroと全く同じです。
※ RESNetの中間出力に対して潜在変数と表現するのは正しくないとは思うが適切なwordingがわからない
VAE系世界モデルとの比較
MuZeroにおける潜在変数空間における状態遷移モデルと行動計画というコンセプト自体は、これまでも世界モデル(World model)系のモデルベース強化学習手法で使われてきたものです。とくにPlaNetとはMuZeroと状態遷移のダイナミクスのモデル化の方法がよく似ています。
Google AI Blog: Introducing PlaNet: A Deep Planning Network for Reinforcement Learning

このようなVAEベースの手法では潜在変数から実状態を復元できるために、上図に示すようにモデルがどのような未来予測をしているのかを視覚化することができます。こういうのは目に楽しいので論文映えしますよね。
一方、多くの世界モデル系手法とは異なり、MuZeroは状態を表現する潜在変数*3をVAEではなくResNetで取得しています。よって潜在変数はResNetの中間出力以上の意味は持たないので当然ながら実状態に復元することもできません。
このような潜在変数に解釈性を求めないアプローチを採用したことについてDeepMindのブログには下記のようなコメントがあります。
The ability to plan is an important part of human intelligence, allowing us to solve problems and make decisions about the future. For example, if we see dark clouds forming, we might predict it will rain and decide to take an umbrella with us before we venture out. Humans learn this ability quickly and can generalise to new scenarios, a trait we would also like our algorithms to have.
~中略~
After all, knowing an umbrella will keep you dry is more useful to know than modelling the pattern of raindrops in the air.
(google翻訳)計画する能力は人間の知性の重要な部分であり、問題を解決し、将来について決定を下すことができます。たとえば、暗い雲が形成されているのを見ると、雨が降ると予測して、出かける前に傘を持って行くことにします。人間はこの能力をすばやく習得し、新しいシナリオに一般化することができます。これは、アルゴリズムにも持たせたい特性です。
~中略~
結局のところ、傘があなたを乾いた状態に保つことを知ることは、空中の雨滴のパターンをモデル化するよりも知るのに役立ちます。
MuZero: Mastering Go, chess, shogi and Atari without rules
おそらく、実空間に復元できるような潜在変数には報酬に関係の無い多くの余分な情報が含まれてしまうので無駄が多い、ということを言っているのかと思いますが、なんか禅問答めいているのでもう少し具体的な例で理解してみます。
たとえば、東京に住んでいるあなたが傘を持っていくかどうかの意思決定をするためには山梨~神奈川あたりの雨雲レーダーだけを見れば十分です。MuZeroの表現ネットワーク(ResNet)も東京近郊の雨雲レーダー情報だけを抽出するのでしょう。一方でVAE系の世界モデル手法では、実状態への復元可能性を保証するために北陸や東北の雨雲レーダー情報まで潜在変数に含まれてしまうため無駄が多い、ということです。

怒られそうな喩えですが、VAEの潜在変数とは霞が関スライド*4 みたいなものと理解しています。すなわち大量の情報を、できるだけ情報量を落とさないように一枚のスライドに圧縮した表現です。一方でMuZero(というかResNet)の潜在変数は一般的なプレゼンスライドであり、特定の目的を達成するために効果的な情報表現となっているはずです。
実際、MuZeroより後に発表されたVAE系モデルベース強化学習(Dreamer)の結果を見てもatari環境ではそれほどスコアがでていません。一方で、連続値コントロール環境(いわゆるMujuco環境)ではD4PGに匹敵する高スコアを出しているので、視覚的情報量の少ない環境ではうまくworkするのでしょう。
Google AI Blog: Introducing Dreamer: Scalable Reinforcement Learning Using World Models
とはいえVAEベースの世界モデル手法も着実に発展はしてきていますので今後に期待です。実用上、エージェントのプランニングを人間が視覚的に理解できるにこしたことはないのですから。
MuZero Reanalyze
MuZeroではリプレイバッファに蓄積されたサンプルの10%しかネットワーク更新に使わない(90%はそのまま捨てる!)上にサンプルは使い捨てというきわめて富豪的な学習戦略をとっていました。atariのような低コストな環境ならこのようなサンプル効率無視の戦略でもよいのですが、これでは現実の課題への適用が難しくなってしまいます。これはMuZero以前のatari環境SotAであるR2D2やApe-Xも抱えている問題でした。
そこで、論文のAppendix Hではサンプル効率を高めた派生手法 MuZero Reanalyze を紹介しています。具体的にはリプレイバッファの入れ替わり速度を小さくして各サンプルが2回程度はネットワーク更新に使われるようにしたうえで、過学習を抑えるためにハイパラを調整しています。
また、target-valueの再計算とtarget-policyとなるMCTSの都度やり直しを行うことで、サンプルの賞味期限切れ問題を軽減しています。

これによって、MuZero Reanalyzeは高いサンプル効率を保証しつつApe-X以上のパフォーマンスに到達することに成功しています。サンプル効率は強化学習の実用化への大きな障壁であるために、これは目覚ましい成果と言えます。
MuZeroの実装
ここからはBreakoutDeterministic-v4(ブロック崩し)向けでのMuZeroの実装例を紹介します。計算リソースの制約上、MuZero Reanalyzeに寄せつつも計算コスト削減のためいろいろ簡略化した実装になってることに留意ください。また、コード全文を掲載するには長すぎるので詳細はgithubを参照ください。
コード全文:
github.com
前提手法:AlphaZero
スッキリわかるAlphaZero - どこから見てもメンダコ
参考:公式疑似コード
https://arxiv.org/src/1911.08265v2/anc/pseudocode.py
メインループ
サンプル収集を行うActorとネットワーク更新を行うLearnerを切り離すApe-Xアーキテクチャ風に実装しました。すなわち、Actorはselfplayによってサンプルを収集しReplayBufferに格納することをひたすら繰り返し、Learnerは蓄積されたサンプルを使ってネットワークを更新をひたすら繰り返します。並列化はrayライブラリで実装しています。
rayで実装する分散強化学習 ③Ape-X DQN - どこから見てもメンダコ
Pythonの分散並列処理ライブラリRayの使い方 - どこから見てもメンダコ
Actorによるサンプル収集
Actorによるサンプル収集はとくに難しいことはなく、MCTSで行動決定しつつゲームをプレイするだけです。
MuZero版モンテカルロ木探索
MuZeroのコアであるモンテカルロ木探索ですが、状態遷移にダイナミクスネットワークを使うこと以外はやってることはAlphaZeroのPV-MCTSと同じです。ただし、潜在変数空間でゲーム木を探索するためゲーム終了が明示されないこと、およびUCBスコアのUとバランスをとるためにQをリスケールしていることに注意してください。
ネットワーク構造
MuZeroの3つのネットワークである、表現ネットワーク、PVネットワークおよびダイナミクスネットワークのtensorflow2での実装例を以下に示します。囲碁・チェス・将棋ではなくatari向けの実装であることに注意してください。
実装を見ると、表現ネットワークは実質的にResNetであることが確認できます。ちなみに表現関数とPV関数を(プログラミング的に)一つのクラスで実装するとAlphaZeroのPVネットワークとほぼ同一になります。
表現関数で抽出した潜在変数とアクションをconcatしてダイナミクス関数への入力とするため、表現関数の出力を0-1にリスケーリングすることで潜在状態と入力アクション(0 or 1)のスケール感を合わせていることに注意してください。
潜在変数空間で表現された状態sとアクションを入力とし、遷移先の状態s'と即時報酬r(s, a)を出力するダイナミクス関数もまた、実質的にResNetであることがわかります。ただし、atari環境では即時報酬r(s, a)の予測値をスカラでなくカテゴリ分布で表現するという点が少しトリッキーです。
たとえば、下図では即時報酬r(s, a)=1.8であるときにどのようにカテゴリ分布で表現されるかを示します。
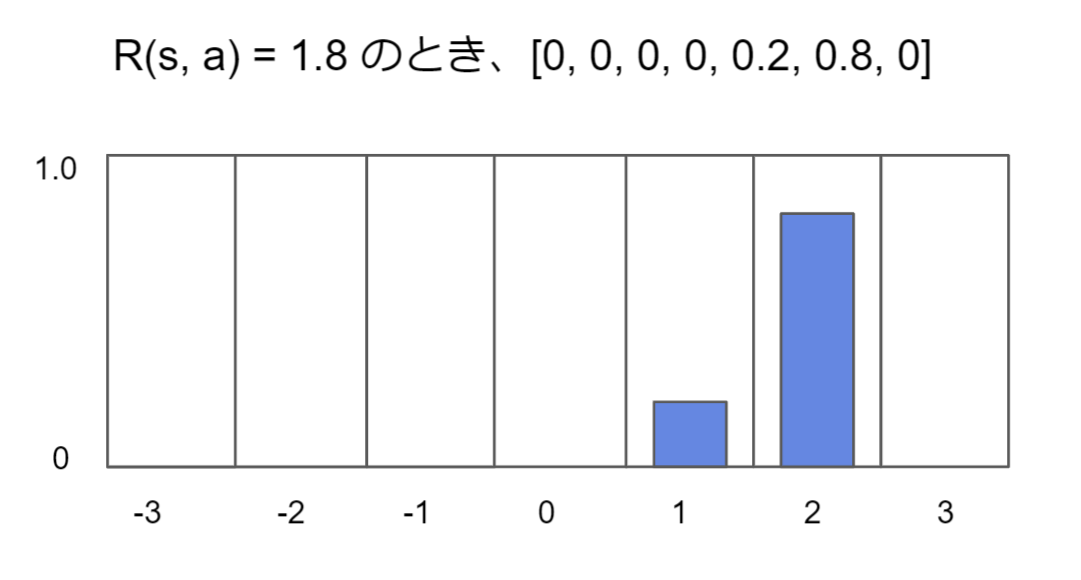
このようにスカラ値であるr(s, a)を無理にカテゴリ分布で表現するのは、後述するロスの計算においてPolicy lossおよびValuelossとのスケール感を合わせるためです。カテゴリ表現するとクロスエントロピーをロス関数に使えるため、policylossに比べてreward lossおよびvaluelossが大きすぎる/小さすぎるということが起こりにくくなります。
Learnerによるネットワーク更新
MuZeroネットワークのトレーニングでは、ある時間tからNstep先までのp, v, r の各予測値とトラジェクトリのずれをロスとします。


p (= policy)についてはAlphaZeroと同様にMCTSの実行結果π(s)を教師ラベルとしてp(s)とのクロスエントロピーをロス関数とします。このpとはあくまで過去のMCTSの結果の近似でしかないので、強化学習的な「方策」ではないことに注意しましょう。
v (= value)についてはボードゲーム環境(囲碁・チェス・将棋)とatari環境で扱いがやや異なります。ボードゲーム環境ではAlphaZeroと全く同様にその盤面が最終的に勝利すれば1, 敗北なら-1, 引き分けなら0 を教師ラベルとしてMSEをロス関数とします。atari環境でも同様にするならゲーム終了時の総スコアをvとすべきですが、そうではなくmulti-step returnを教師ラベルとします。かつ、上述した理由によりスカラ値をカテゴリ分布に変換しクロスエントロピーをロス関数とします。
r (=reward)については、ボードゲーム環境に即時報酬が無いためatari環境でのみ計算します。実際に得た即時報酬uをカテゴリ分布に変換し、予測値とのクロスエントロピーをロス関数とします。
ネットワーク更新のtensorflow2での実装例を以下に示します。ロス関数自体はクロスエントロピーなので実装は簡単ですが、難しいというか面倒なのはあるサンプルを起点とした時間発展でこのロスを計算しなければいけないことです。※以下のコードでは時間発展ステップ数をunroll_stepsとしています。
Breakoutの学習結果
GCPの24-vCPU/128GB RAM/GPU T4 のプリエンティブルVMインスタンス(ubuntu18.04)を使って24×2時間*5の学習を行いました。400点を超えているので動作検証としては十分なスコアが得られています。

各フレームごとに状態価値V(s), モンテカルロ木探索の結果であるπ(s), そして即時報酬予測R(s, a)を可視化してみると、しっかり即時報酬が予測できていることがわかります。しかし、ボールの速度変化に対応できずロストしてる感じです。論文では直近32フレームをネットワークの入力しているのですがこの実装ではメモリの都合上直近4フレームしか入力してないことが悪く影響しているような気がします。
Deepmind's MuZero (reimplementation for Breakout) #ReinforcementLearning pic.twitter.com/JWvnwFC1Om
— めんだこ (@horromary) 2021年8月3日
↓しっかり即時報酬を予測してます

次:???
DeepMind先生の次回作にご期待ください