深層強化学習における超大規模分散並列化の有用性を示したApeX-DQN(Distributed Prioritized Experience Replay)をtensorflow2とrayで実装します。手法の構成要素自体はRainbowとだいたい同じであるため、本記事の焦点は分散並列学習の実装です。

rayで実装する分散強化学習:
Pythonの分散並列処理ライブラリRayの使い方 - どこから見てもメンダコ
rayで実装する分散強化学習 ①A3C(非同期Advantage Actor-Critic) - どこから見てもメンダコ
rayで実装する分散強化学習 ②A2C(Advantage Actor-Critic) - どこから見てもメンダコ
前提手法:
DQNの進化史 ①DeepMindのDQN - どこから見てもメンダコ
DQNの進化史 ②Double-DQN, Dueling-network, Noisy-network - どこから見てもメンダコ
DQNの進化史 ③優先度付き経験再生, Multi-step learning, C51 - どこから見てもメンダコ
DQNの進化史 ④Rainbowの実装 - どこから見てもメンダコ
はじめに
[1803.00933] Distributed Prioritized Experience Replay
Distributed Prioritized Experience Replay | OpenReview
Distributed Prioritized Experience Replay、あるいはApe-X*1はその名の通り 優先度付き経験再生を大規模分散並列学習に対応させた手法です。Ape-XはDDPGにもDQNにも適用可能な手法ですが、後者に適用された場合にはApe-X DQNと呼称されます。Ape-X DQNはオフポリシー強化学習の大規模分散並列化は訓練時間*2を短縮するだけでなく、パフォーマンスの向上にも寄与することを当時のatari環境における圧倒的SotAで示しました。

DQNはオフポリシー手法であるので、収集した遷移情報(経験)を何度でも再学習してよいはずなのですが、Ape-Xはそのような循環式の経験再生よりも、源泉かけ流し的な贅沢な経験再生の方がパフォーマンスが良くなるということを示しました。この発見が以降の強化学習手法における大規模分散並列学習トレンドを加速していくこととなります*3。
Ape-X DQN の概要
Ape-Xの基本コンセプトは遷移情報を収集するプロセス、遷移情報を蓄積を担うプロセス、および勾配計算してネットワークを更新するプロセスを完全に分離することによる効率化です。この分散学習アーキテクチャはFig.1に示されており、Learner, Actor, Replay という3つの主要な役割があることが分かります。
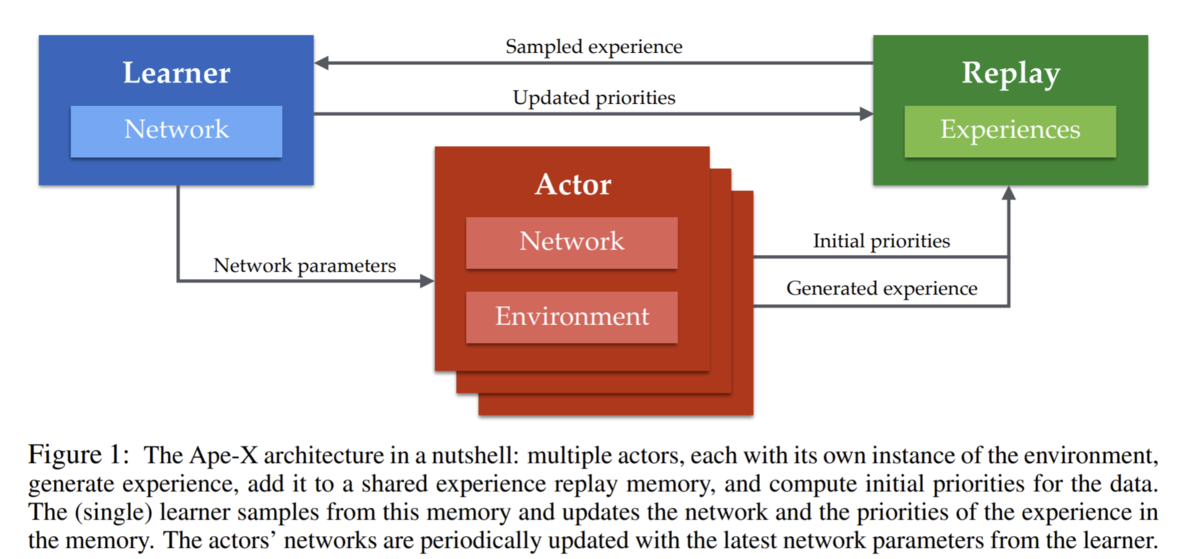
Learnerの役割
Leanerプロセスには1CPU, 1GPUが割り当てられます。
Leanerの役割はReplayから供給されるミニバッチでひたすらにQネットワークを更新しつづけること、およびActorからのネットワーク重み同期要求に応じることです。学習速度を最大化する(≒GPU稼働率を最大化する)ためにReplayからのミニバッチの供給を途切れさせないことが重要となります。
Actorの役割
各Actorプロセスには1CPU, 0GPUが割り当てられます。このActorプロセスは論文では最大360並列実行されています。
Actorの役割は、遷移情報の収集と各遷移の初期優先度の算出です。ActorはQネットワークを持ち自律的にrolloutを行います。100step程のrolloutを行った後に勾配計算は行わず集めた遷移情報をそのままRepalyプロセスに送信します。ただし、遷移情報の送信時にはローカルQネットワークでの推論により初期優先度(∝TD誤差)を算出しておきます。
オリジナルの優先度付き経験再生では、各遷移の初期優先度には最大値を割り当てることで必ず一回は経験が再生されるようにしていましたが、経験再生される速度よりも経験の供給速度の方が圧倒的に速いApe-Xアーキテクチャでそれを行うと直近の遷移ばかりが再生されることになりReplayが意味をなさないため、Actorプロセスで初期優先度を計算することにより遷移情報をふるいに掛けています。換言するとApe-Xアーキテクチャでは一度も再生されないまま消えゆく遷移情報もあるということで、当然サンプル効率は劣悪です*4。
ActorがローカルQネットワークを保持して自律的にrolloutを行うという点ではA3Cアーキテクチャと同じですが、Ape-XではA3Cと異なりActorは勾配計算せずReplayへ遷移情報を送信するだけです。これは、勾配情報だとグローバルQネットワークへの反映遅れに気を使う必要がありますが、遷移情報ならばReplayへの反映が多少遅れても問題ないので大規模分散学習にて扱いやすいためです。また、勾配計算するならActorにもGPUが無いと厳しいですが推論だけならCPUだけでもそれほど苦しくないという利点もあります。
また、分散並列化されたActorはすべて異なる探索率εが割り当てられる、というのも重要なポイントです。従来のシングルActorのDQNでは、高い探索率εで学習を開始しゆっくりとεを下げていくアニーリング方式によって探索と活用のトレードオフをバランスしていました。これに対してApe-Xではさまざまな探索率のActorが存在するので自然に多様な経験を収集することができます。このような異なる方策(探索率)を持った並列Actorでのrolloutは、DQNがoff-policyであること生かしたテクニックと言えます。

Replayの役割
Replayの役割はActorからの遷移情報受け取り、Leanerに供給するミニバッチの作成、およびLeanerからの更新優先度情報の受け取りです。実態はただの優先度付きReplayBufferなのですが、ActorともLeanerともやり取りしなければいけないため一番忙しいプロセスです。
Rainbowからの継承要素
Ape-X DQNは優先度つき経験再生の後継手法というよりは、DQNの改良トリック全部盛り手法である Rainbow + 大規模分散並列学習 と表現するほうが正確でしょう。実際に、Rainbowが採用していた6つのDQN改良トリック(Double Q-learning, Dueling network, Noisy-network, Prioritized Experience Replay, Multi-step learning, Categorical DQN)のうち、Ape-X DQNではNoisy-networksとCategorical DQN (C51) 以外はすべて採用しています。
上述の通りApe-Xでは各Actorに異なる探索率εを割り当てることにより(計算パワーの力で)探索と活用のバランスをとるので、同じく探索戦略であるNoisy-networkを除外することはごく自然です。一方で、Rainbowに採用された6つDQN改良トリックのうち単体でもっともパフォーマンスの高いC51を除外するのは明らかに違和感がありますが、OpenReviewでの回答を見る限りでは単に実装の煩雑さを嫌っただけのようです*5。
Q1: on using all Rainbow components and on using multiple learners.
These are both interesting directions which we agree may help to boost performance even further. For this paper, we felt that adding extra components would distract from the finding that it is possible to improve results significantly by scaling up, even with a relatively simple algorithm. (https://openreview.net/forum?id=H1Dy---0Z)
大規模並列Actorの効果検証
Actorを増やすほどReplayBuffer内の繊維状の入れ替わりサイクルが短くなるため、より最近に収集された遷移情報が再生されやすくなります。また、ある経験が再生される回数が少なくなり源泉かけ流しに近くなっていきます。これはある意味でon-policy学習のやり方でQネットワークを訓練していると解釈できます。
もしon-policyっぽくDQNの訓練を行うことがパフォーマンスの向上の理由ならば、actorの数を大規模並列化せずとも経験再生される回数を制限すればApe-Xと同等のパフォーマンスが得られるはずです。論文ではこれについての検証実験を行っており、Fig.6はactorの並列数(n)=32に固定したうえで、ある遷移情報が再生される回数(k)を変化させるとパフォーマンスにどう影響するのかを示しています。同じactor数(n=32)では再生回数kの違いは大差ないことがわかります。さらにactorの並列数(n)=256の場合はn=32の場合と比較してパフォーマンスに大きな差をつけています。
この結果から論文では経験再生の新陳代謝の速さに由来するon-policyっぽい学習だけでなく、並列マルチ方策(=異なる探索率εが割り当てられた)actorによって生成される多様な経験がパフォーマンスに寄与していると結論付けています。

ついでにFig.7では各Actorへの探索率εの割り当ての多様性の効果について検証しています。各Actorにすべて異なる探索率を割り当てた時と、割り当てる探索率を6つに減らした時にどうパフォーマンスが変わるかの検証実験です。前者はepsilons = np.linspace(0.01, 0.4. num_actors)で後者はepsilons = np.linspace(0.01, 0.4. 6)という感じのイメージ*6だと思います。結果は直感通りで、パフォーマンスにそこまでの大差なしとのこと。
CartPole環境での簡易実装
まずは分散並列アーキテクチャを理解するために、CartPole環境で優先度付き経験再生以外のDQN改良トリックを除外したシンプルな実装を示します。
分散学習の実装
Ape-X アーキテクチャで重要なのはLearner(=GPU)を休ませないことです。このためにLeanerには16セットのミニバッチを渡し、Learnerがネットワークの更新をしている裏でReplayはせっせとActorから経験を受け取っていきます。*7 この流れはrayを使うことですっきり記述できます。
Pythonの分散並列処理ライブラリRayの使い方 - どこから見てもメンダコ
実装上のポイントは39行目のfinished_learner, _ = ray.wait(wip_learner, timeout=0)です。timeout=0を指定したray.waitは実行時点で対象プロセスが未完了である場合、finished_learnerとして空リストを返すためLearnerプロセスの終了判定が可能です。このLeanerプロセス終了判定をActor to Replayでの遷移情報送付が1回行われるごとに実行することで、Learnerプロセスが空き次第すぐに次のminibatchを渡すという疑似的な割り込み処理を実装することができます。
この実装は45,46行目でReplayプロセスが行う、次のミニバッチセットの作成と優先度の更新処理がLeanerプロセスに比べて十分に速いことを前提としていることに注意してください。もしReplayプロセスが遅すぎる、あるいはLeanerプロセスに渡すミニバッチの数が少ないためにLeanerプロセスの完了が早すぎる場合にはActorからの遷移情報送付が滞ってしまいます。このため、一度のネットワーク更新ごとに何回Actorからの遷移情報送付が行われているかはしっかりチェックしておきましょう。
Actorへ最新の重みを渡すためにray.putを使用していることに留意してください。ray.putは大きめのデータ、この場合はメインQ関数の重みを多数のリモートActorに配布する処理を効率化してくれます。
Ray Core Walkthrough — Ray v2.0.0.dev0
ApeXのコアとなるコードはこれだけです。 rayのおかげでシンプルに実装できていると思います。以下では各プロセスの詳細実装を紹介しますが、DQNおよび優先つき経験再生を理解できていればとくに難しいことは無いはずです。
Actorの実装
Actorプロセスは一定stepのrolloutを行って遷移情報するだけなので実装はごく単純です。A3Cと同様にApeXではActorがローカルQネットワーク(LearnerのQ関数のコピー)を持ち自律的にrolloutを行うので、Actor.rolloutではまず初めにleanerのQ関数と重みの同期を行います*8。その後、100step分のrolloutを行い、収集した遷移情報とそれらについてのTD誤差(初期優先度の計算に使用)を返します。
Replayの実装
Replayは単なる優先度付き経験再生です。Ape-XではReplayプロセスが行うミニバッチ作成(Replay.sample_minibatch)の速度パフォーマンスが求められるので、高速な重み付きサンプリングができるSumTree構造で優先度を保存しています。他の留意点として、オリジナルの優先度付き経験再生では、Importance Sampling weights(もどき)のハイパラであるβをアニーリングしていましたが、Ape-Xでは固定値になっています。
Learnerの実装
LearnerはReplayから受け取ったミニバッチでひたすらネットワーク更新するだけのプロセスです。16セットのミニバッチを消費したら最新の重み、および更新された優先度をメインプロセスへ返却します。優先度付き経験再生を理解していれば何も難しいことはありません。
Qネットワーク
特筆することは何もありませんが一応載せておきます。
学習結果:CartPole-v0
CartPole-v0のハイスコア200点に到達するまでおよそ20秒!

(もちろんマシンスペックに依存しますが)8並列Actorの環境ではLearnerが16セットのミニバッチ(各batch_size=32)を消化する間にActorからReplayへの遷移情報送信が25回程度行われていました。
Atari環境(Breakout)での実装
さて、CartPoleでの簡易実装がうまくいったのでBreakout(ブロック崩し)でDQN改良トリックまで含めて本格実装したコード例も掲載します。と言いたいところだったのですが、過去記事で紹介したRainbowの実装と丸被り & コードが長大なので結果だけ示します。改良トリックの詳細は過去記事で、実装全体はGithubでご確認ください。大筋は上に示したCartPoleと同じですが、Dueling-net, Double-DQN, Multi-step Learning、およびメモリ節約のために遷移情報をzlibで圧縮するコードが追加されています。
学習結果:BreakoutDeterministic-v4
リソースの都合上*9、actorは20並列にしかできませんでしたがそれでも分散学習の威力を実感できる結果となりました。探索率εの大きいactorが混じっていることによる正則化?効果のおかげかパフォーマンスが大崩れせず順調に学習が進みます。ただし、Breakout環境では探索率εの上限値が論文通りの0.4では小さすぎるためか学習の立ち上がりが悪く感じたのでεの上限は0.5に変更しています。

