Deep-Q-Network以降の深層強化学習(というか深層Q学習)の発展を、簡単な解説とtensorflow2での実装例と共に紹介していきます。今回は経験再生の改良である優先度付き経験再生(Prioritized experience replay)、方策勾配法ではよく使われるMulti-step learning, そして深層分布強化学習の有用性を示したCategorical DQN を紹介します。
DQNシリーズ
DQNの進化史 ①DeepMindのDQN - どこから見てもメンダコ
DQNの進化史 ②Double-DQN, Dueling-network, Noisy-network - どこから見てもメンダコ
DQNの進化史 ③Prioritized experience replay, Multi-step learning, Categorical DQN - どこから見てもメンダコ
DQNの進化史 ④Rainbowの実装 - どこから見てもメンダコ
前提手法:DQN horomary.hatenablog.com
Prioritized experience replay(2015)
[1511.05952] Prioritized Experience Replay
オリジナルのDQNではReplayBufferに蓄積した遷移情報からのランダム選択によってミニバッチを作成します。しかし、遷移情報をランダムに選択するのでは思いがけず上手くいったような貴重なイベント(遷移)を学習する効率が悪いですね。そこで、Prioritized experience replay(優先度つき経験再生)ではその名の通り、意外性の高い遷移を優先してReplayBufferからサンプリングします。
具体的には、TD誤差δの大きい遷移情報ほど意外性が高いと見なし、TD誤差δの絶対値の大きさに応じてサンプリングされる確率に重みをつけます。*1
TD誤差δ:
バッファ内のi番目の遷移情報がサンプリングされる確率P(i):
P(i)内のαはハイパーパラメータ(0≦α≦1)です。α=0のとき P(i) = 1/N になりランダムサンプリングと同一となります。また、εはサンプリング確率が完全にゼロになってしまうことを防ぐための適当な微小量です。
このような重みづけサンプリングは速度パフォーマンスを気にしないならば、np.random.choiceで楽に実装できます。速度を気にするならSegmentTree*2で実装しましょう。簡単のためにここでは前者の実装例を示します。
#: Nは蓄積されている遷移情報の総数 probs = priorities / priorities.sum() indices = np.random.choice(np.arange(N), p=probs, replace=False, size=batch_size)
sumtreeでの高速な優先度付きサンプリングについては別記事を参照ください。
補正TD誤差によるネットワーク更新
優先度に応じてサンプリングすると同じ遷移情報を執拗に学習することになり学習の安定性を損なう恐れがあるため、Q関数の更新時には遷移から計算されるTD誤差にサンプリング確率に応じた補正を行います*3。
補正重み:
βは補正の強さを決めるハイパーパラメータ(0≦β≦1)です。β=0のときw=1で補正無しとなりβ=1のとき完全な補正となります(優先度付きのサンプリング確率がP(i)であるため)。βはオリジナルDQNにおける探索率εと同様、学習中にアニーリングを行います。atari環境ではβ=0.4から始めて学習終了時にβ=1.0になるように線形に増加させるのが良いようです。
補正重みはミニバッチ平均をとる前のTD誤差に適用します。
ネットワークの更新のために計算したTD誤差で各遷移の優先度を更新するのも忘れないようにしましょう。
リプレイバッファの実装:
atari環境で100万ステップを愚直に蓄積するとメモリ消費が大変なことになるのでzlibで圧縮しています。
【追記:2021/02/15】
パフォーマンス検討の結果、この実装例で処理速度のボトルネックになっているのはnp.random.choiceではなく、listからndarrayへの変換処理が入る probs = np.array(self.priorities) / sum(self.priorities)でした。よって、self.prioritiesをlistではなくnp.ndarrayで実装するとget_minibatchの速度パフォーマンスが10倍くらい改善されます。
Multi-step learning
Multi-step learning というアイデアは新しいものではありませんが、Rainbow (2017) やApe-X-DQNの構成要素となっているので紹介しておきます。
まず、オリジナルのDQNでは下式のように1step分の遷移情報を使用してTD誤差を計算します。
1step-TD誤差
これに対してMulti-step learningではその名の通り、1stepじゃなくNstepの遷移情報でTD誤差を計算します。ここでは具体的にRainbow(2017)でも採用されている3stepTD誤差の式を示します。
3step-TD誤差
これだけです、とくに難しいことはないですね。
Multistep-learningを採用することで遅延報酬が伝搬しやすくなると考えられます。例えば、Breakout(ブロック崩し)ではボールを弾く(行動選択)タイミングに対して、ブロックを崩す(報酬を得る)のは何フレームか後です。このような行動選択に遅延して生じる報酬の因果関係を学習しやすくなることが期待できます。とはいえ、あまり長く先まで見すぎるとそれはもはやモンテカルロ推定でありバイアスが大きくなりすぎるのでほどほどにします。
補足:
atari環境では問題なく機能しますがMultistep-learningを採用したDQNは厳密にはoff-policyではないことに留意。
Off-policy n-step learning with DQN - Data Science Stack Exchange
実装例
Multistep-learningのコンセプトは単純なのですがどう実装するか、というかどの部分に実装するかは迷うところです。とりあえずreplay_bufferにこの役割を担わせることにしました。こうするとオリジナルDQNからのコード変更が少ない気がします。
Categorical DQN(2017)
[1707.06887] A Distributional Perspective on Reinforcement Learning
Rainbow以前の単体でもっとも強力なDQN拡張手法はおそらくこのCategorical DQN (C51)でしょう。*4 Dueling-networkや前述の優先度付き経験再生など他のDQN拡張手法を使用せずに単体で当時のatari環境のSotAを奪いました。
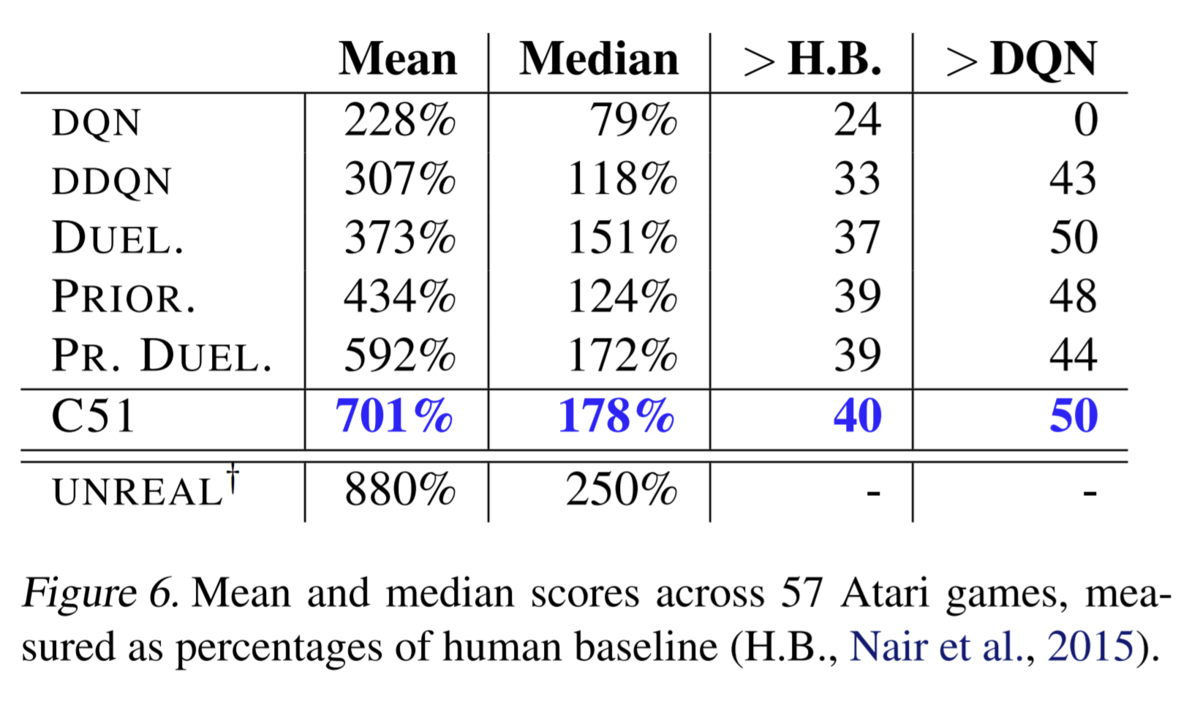
通常のQ学習では状態行動価値Q(s, a)の期待値を近似するのに対して、Categorical DQNでは状態行動価値Q(s, a)の分布を近似することを狙います。状態行動価値Qの期待値でなく分布を近似することでなぜ性能が大幅向上するかは実はよくわかっていないものの、その圧倒的な性能で深層分布強化学習という分野を切り開き、D4PG、 QR-DQN、 IQN など多くの後継手法を生みました。
Categorical DQNは単体でもっとも強力なDQN拡張手法であると同時に、単体でもっとも実装が煩雑なDQN拡張手法でもあります。難解ではありませんが煩雑です。 ゆえに解説するとわりと長くなるので実装は別記事を参照ください。