GPUが一つしかなくても効率よく訓練できる分散強化学習手法A2Cをrayで実装します。
前記事:

A2Cとは
A3C論文: [1602.01783] Asynchronous Methods for Deep Reinforcement Learning
A2CはA3C(Asynchronous Advantage Actor Critic) の派生手法です。 A3Cでは並列化された各agentが自律的にrollout → 勾配計算し勾配情報だけをパラメータサーバに送付、という流れで分散学習を行います。この方法では各agentがそれぞれ勾配計算を行うためGPUの数=agentの数のときパフォーマンスが最大となります*1。これはGPUリソースに乏しい一般人にはなかなか辛いアーキテクチャです。
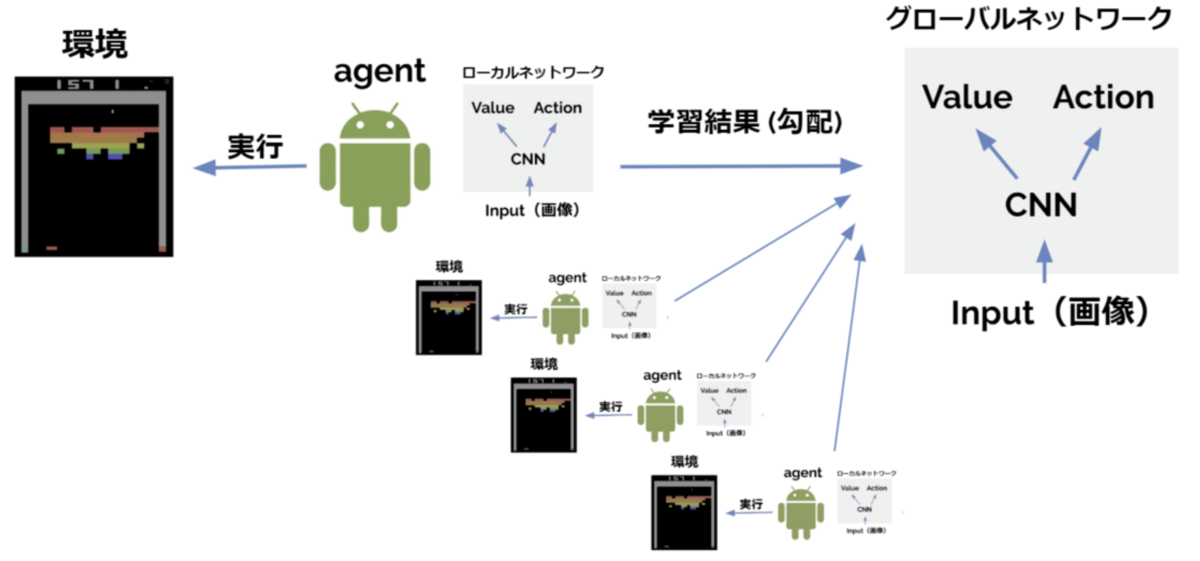
そこで、①中央指令室がすべてのagentに対してアクション指示を出す→②並列化された各agentは指示されたアクションで環境のstepを進める→③各agentは蓄積した遷移情報を中央指令室へ送信→④中央指令室が集められたトラジェクトリから勾配計算しネットワークを更新する、という流れで学習を行う派生手法が考案されました。これなら推論、勾配計算をするのは=GPUを使うのは中央指令室だけなのでGPUは1つでOKとなります。
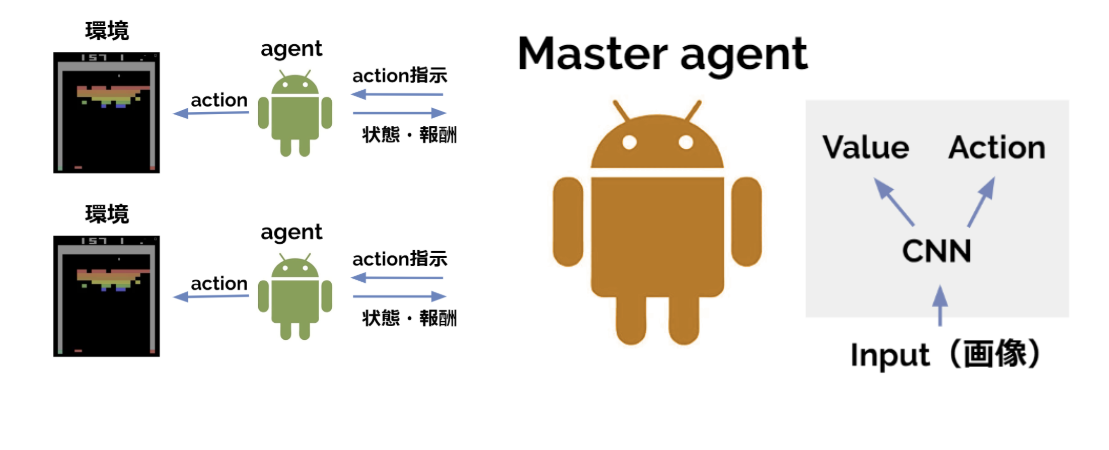
この分散学習アーキテクチャはA3Cの最初のAである Asynchronous(非同期) の要素が削られているのでA2Cと呼ばれます。ちなみに、A3CとA2Cでパフォーマンスに大きな差は無い*2、とのことです。
A3Cの非同期並列アーキテクチャ、およびA2Cの同期並列アーキテクチャはその後のさまざまな手法で転用されているので実装できるようになっておくと便利です。たとえば openai/baselines のppo1はA3CアーキテクチャでのPPO(Proximal Policy Optimization)実装、ppo2はA2CアーキテクチャでのPPO実装です。
rayによるA2C型同期並列アーキテクチャの実装
A3Cの非同期並列学習とは違い、A2Cの同期並列学習についてはmultiprocessingなんかでの実装もそれほど難しくありませんが、rayを使うことですっきりシンプルに実装できます。
並列agentでトラジェクトリを収集するコードはこれだけ!
以前openai/baselinesの
SubprocVecEnvを参考にしたmultiprocessingモジュールでのA2C実装を紹介しましたが、それと見比べるとシンプルさがよくわかります。rayではクラスごと並列化できるので状態を保持するサブプロセスを実装するときに本当に便利です。
A2Cでのネットワーク更新
更新アルゴリズム自体はA3Cと全く同じですので解説については前記事を参照ください
A3Cでは各agentごとにミニバッチを作成し更新していましたが、A2Cでは各agentから取得したtrajectoryを集約してminibatchとします。
CartPole-v1での学習結果
とくに問題なし
