Google Kubernetes Engine (GKE) とpythonの分散処並列理ライブラリRayで安価に大規模分散並列強化学習(Ape-Xアーキテクチャ)の実行環境をつくるチュートリアルです。GKEのプリエンプティブルインスタンスを活用することで、総リソース 128 vCPU, NVIDIA Tesla P4 x1, 256 GB memory のクラスタがざっくり150-200 円/時間になります。(2021年8月時点)

rayで実装する分散強化学習シリーズ:
Pythonの分散並列処理ライブラリRayの使い方 - どこから見てもメンダコ
rayで実装する分散強化学習 ①A3C(非同期Advantage Actor-Critic) - どこから見てもメンダコ
rayで実装する分散強化学習 ②A2C(Advantage Actor-Critic) - どこから見てもメンダコ
rayで実装する分散強化学習 ③Ape-X DQN - どこから見てもメンダコ
はじめに
分散並列強化学習のメリット
分散強化学習は、単に処理が高速化するだけでなく多様な状態遷移の収集が可能になり学習が安定化することがメリットです。
このことをA3C論文が当時のatari環境のSotAという結果で示して以来、軽量なシミュレーターが利用可能な強化学習環境(atariやMuJoCoなど)では分散並列化が基本テクニックとして採用されるようになりました。とくにApe-X DQN、R2D2やAgent57などのDQN派生の手法では、並列化されたagentごとに異なる探索戦略(単純には探索率εの値など)を割り当てるマルチ方策学習が採用されているため、分散並列化することが手法の前提となっています。
このような強化学習の分散並列化トレンドに対応すべく、本稿ではGoogle Cloud PlatformのマネージドKubernetesであるGKE(Google Kubernetes Engine)を利用して分散並列強化学習環境を構築します。また、並列化のバックエンドとしてはRayライブラリを使用します。
Ape-X アーキテクチャ
より具体的には、本稿はGCPのマネージドKubernetesであるGKE上でApe-Xアーキテクチャを実装するチュートリアルです。
※Ape-Xの手法自体の説明は過去記事をご参照ください。
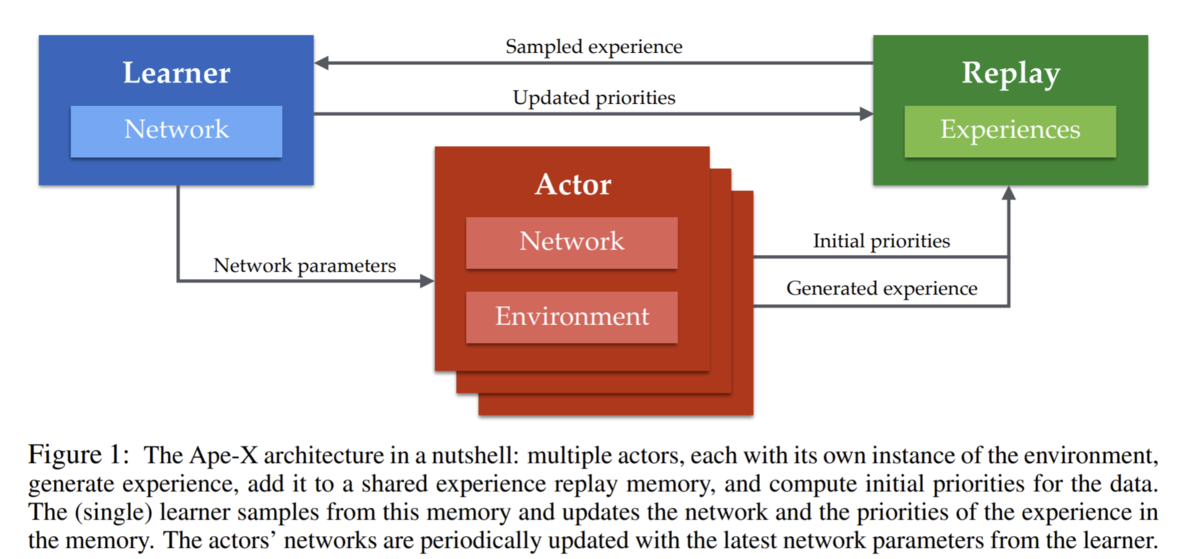
rayで実装する分散強化学習 ③Ape-X DQN - どこから見てもメンダコ
各プロセスの概要および要求リソースは以下のようになります。
Replay(1CPU, 0GPU, メモリたくさん)×1プロセス:
Actorが収集した遷移情報の受け取り、およびLearnerへの遷移情報の送信を行います。また、メインプロセスを兼ねます。
Leaner (1CPU, 1GPU, メモリ多少)×1プロセス:
Replayから遷移情報のミニバッチを受け取ってひたすらネットワーク更新だけを行います。これによって1台のGPUを最大効率で活用できるというのがApe-Xアーキテクチャの嬉しさです。
Actor(1CPU, 0GPU, メモリ多少)×200~300プロセス:
ひたすら環境と相互作用(atari環境ならゲームをプレイ)して遷移情報を収集し、Replayプロセスへ送信します。Actorは行動選択時にQネットワークでの推論を行いますが、1サンプル推論なのでGPU無くても問題ないです。
なぜGKEを使うか?
プリエンプティブルVMが格安
GPUが不要であるならマルチノード分散並列化せずに単一ノードのウルトラハイスペックインスタンスをGCE(AWSでいうEC2)で用意してもいいのですが、GCEではGPUを利用する場合には1GPUあたりで利用可能なCPU数に上限がかかるので大規模な並列化はできません。たとえばNVIDIA T4ではGPU1枚あたり24 vCPUが上限です。
Compute Engine の GPU | Compute Engine ドキュメント | Google Cloud
かといってGCEインスタンスを手動でたくさん立ててクラスタ構築するのはあまりに煩雑ですので、GCPのマネージドKubernetesであるGKEを利用していきます。マネージドKubernetes自体はAWS(EKS)やAzure(AKS)でも提供されていますが、それらではなくGKEを選択するのは安価なプリエンプティブルVM が利用可能であるためです。プリエンプティブルVMとはGCPの余ったリソースを定価の7-8割引きという格安で提供するインスタンス形式です。ただし、最大24時間しか持続しない上にGCPのリソースの状況次第で突然停止されることもあります。
GKEのプリエンプティブルインスタンスを活用することで、総リソース 128 vCPU, NVIDIA Tesla P4 x1, 256 GB memory のクラスタがざっくり150-200 円/時間になります。※2021年8月時点の概算
GPU の料金 | Compute Engine: 仮想マシン(VM) | Google Cloud
Autoscalingがお手軽
プリエンプティブルVM以外のGKEの利点としては、計算リソースのAutoScaling機能がお手軽かつ優秀*1なのでノード構成をあまり意識しなくてよいということがあります。とくに最近リリースされたGKE AutoPilotモードでは物理ノード構成を一切意識しなくてよいという大変便利なものになっていますが、AutoPilotはプリエンプティブルVMをサポートしていない(21年8月時点)ので本稿ではGKE Standardモードで構築します。お金のある人はAutoPilotモードがおすすめです。
なぜRayを使うか?
分散並列化のバックエンドにはRayライブラリを使用します。Rayを採用するとPythonのマルチノード分散並列処理が驚くほど楽にできるようになります。*2
Rayの利点①:並列化コードを書くのが楽
分散並列化でなく単なる並列化であれば、multiprocessingやjoblibのような並列処理のライブラリも利用可能ですが、Rayはこれらの既存ライブラリと比べても遜色なくシンプルに並列処理のコードが書けます。
Rayの利点②:単ノード並列(MP)→マルチノード分散並列(MPI)でコード変更がほぼ不要
単一マシンでの並列処理コードをほぼ変更することなくマルチノードで分散並列処理ができることはrayの大きな利点のひとつです。ローカルマシンでデバッグしつつ作成した並列処理コードをそのままスケールアップして分散並列処理することができるため生産性が高くなります。
たとえば上のサンプルコードでは、並列処理と分散並列処理でコード変更が必要なのはクラスタの初期化処理(ray.init())の引数のみです。
Rayの利点③:クラスタのセットアップが楽
OpenMPIしかりMPICHしかり、分散並列処理フレームワークは環境構築が煩雑な印象があります。一方でrayはpip install rayだけで環境構築が完了です。クラスタの起動も簡単で、ヘッドノード(pythonスクリプトを起動するノード)でray start --head --port=6379、ワーカーノードで ray start --address='<ヘッドノードのIP>:6379' を実行すればクラスタの準備完了です。あとはヘッドノードにてrayで並列化が記述された任意のpythonコードを実行するだけとなります。
マルチノード分散強化学習チュートリアル
ここからは実際にGKEでクラスタを構築し、rayによって分散並列化された強化学習を実行するチュートリアルです。
※強化学習コードやKubernetesのマニフェストファイルの詳細はGithubを参照ください
github.com
1. 並列強化学習の実装とDockerイメージ作成
まずは普通にローカルマシン上にてrayによって並列化されたApe-Xアーキテクチャを実装します。
※実装自体は過去記事とほぼ同じなので省略します
次に、実装したコード(code/以下)を動かすためのdocker imageを作成します。
# Dockerfile FROM tensorflow/tensorflow:2.5.1-gpu COPY ./code /code RUN pip install -r code/requirements.txt
作成したイメージはdockerhubかGCR(Google container registry)にpushし、GKEから利用可能な状態にしておきます。
2. Kubernetesマニフェストの作成
分散学習クラスタをkubernetesマニフェストに記述します。
entrypointはtype=LoadBalancerのServiceリソースです。
このServiceリソースは外部からtensorboardおよびray-dashboardにアクセスして学習をモニタリングするためだけに使用するので必須ではありません。(※この設定はIPさえ知っていれば誰でもtensorboardにアクセスできるので機密プロジェクトでは使用しないでください。)ray-headless-svcはワーカーノードがヘッドノードを名前解決するためのHeadless Serviceです。masterはおよびメインプロセスおよびtensorboardコンテナを起動するPodです。よってこのPodが稼働しているノードがヘッドノード(pythonスクリプトを起動するノード)です。Ape-XのメインプロセスはReplayBufferを持ちメモリを大量に消費するのでresources.requestsでmemory=24GiBをリクエストしています。また、GPUを利用するLearnerプロセスとメインプロセスを物理的に同じノードに置きたいのでnvidia.com/gpuをリクエストしています。
actorはワーカーノードに配置されるactor-podを複製するReplicaSetです。各actor-podは15CPUを要求します。ワーカーノードからヘッドノードへの通信確立はray start --address='<ヘッドノードのIP or ホスト名>:6379'コマンドで行います。ただ当然ながらヘッドノードが立ち上がっていないとこのコマンドは失敗するのでmasterが起動するまで待機するスクリプトを先に実行します。この待機スクリプトをConfigMapに記述してマウントしています。
3. 環境構築
GKEをローカルマシンから操作する前準備を行います
(無い場合)GCPアカウントの作成:Step 1: Create a GCP account | Apigee X | Google Cloud
gcloudコマンド: Cloud SDK のインストール | Cloud SDK のドキュメント | Google Cloudkubectlコマンド: kubectlのインストールおよびセットアップ | Kubernetes
がローカルマシンから実行可能にしておいてください。
4. GKEへのクラスター構築
※ここからはすべてローカルマシンでの操作です
まずはGCPへのログインと新規プロジェクト作成
#: ブラウザが立ち上がりログイン画面が表示される gcloud auth login #: 任意のIDおよび名前でプロジェクトを作成 #: gcloud projects create <ProjectID> --name <ProjectName> gcloud projects create distrl-project --name distrl
つぎにconfigにデフォルト値を設定することで以後のコマンド入力を楽にします。
regionによっては使えないGPUもあることに留意してください
GPU regions and zones availability | Compute Engine Documentation
#: gcloud config set project <ProjectID> gcloud config set project distrl-project #: gcloud config set compute/region <RegionName> gcloud config set compute/region northamerica-northeast1 #: gcloud config set compute/zone <zoneName> gcloud config set compute/zone northamerica-northeast1-a gcloud config list
注意:
GCPアカウントの利用実績がない場合は、プロジェクトが同時に利用可能な総CPU数/GPU数/メモリ に強い制限がかかっています。この場合はReplicaSet/actorのreplicas=1と設定して並列数を減らすか、下記リンクを参考にリソース割り当ての増加をリクエストしてください
割り当てと上限 | Network Service Tiers | Google Cloud
以下のコマンドでクラスタを構築しますがここからは時間課金されるのでクラスタの消し忘れに注意してください。不安になったらWeb-GUIを確認しましょう。まあ万が一クラスタを消し忘れてもプリエンプティブルVMは24時間で消えるのでダメージは小さいです。
#: GPU node-pool (1ノード) の作成
#: 16 vCPU, 32GiB memory, 1 NVIDIA Tesla P4 GPU
gcloud container clusters create rl-cluster \
--accelerator type=nvidia-tesla-p4, count=1 \
--preemptible --num-nodes 1 \
--machine-type "custom-16-32768"
#: CPU node-pools (autoscale) の作成
#: 各ノード 16 vCPU, 32GiB memory, 0 GPU
gcloud container clusters node-pools create cpu-node-pool \
--cluster rl-cluster \
--preemptible --num-nodes 1 \
--machine-type "custom-16-32768" \
--enable-autoscaling --min-nodes 0 --max-nodes 30 \
# ローカルマシンからGKEクラスタにkubectlする権限取得
gcloud container clusters get-credentials rl-cluster
#: Install GPU driver
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
重要なオプション:
--preemptible: プリエンプティブルインスタンスを指定--enable-autoscaling: 計算リソースが不足した場合は自動でノードプール内のノード数を増やす
gcloud container clusters create | Cloud SDK Documentation
4. 学習実行とモニタリング
ようやく学習を開始します。
#: GKEにマニフェストを反映 kubectl apply -f apex-cluster.yml #: ヘッドノードへログイン kubectl exec -it master bash
ヘッドノードへログイン後、ray statusコマンドを実行することでクラスタの状態を確認できます。
>>> ray status ~~ 中略 ~~ Resources ------------------------------------------------------------ Usage: 0.0/109.0 CPU 0.0/1.0 GPU 0.0/1.0 accelerator_type:P4 0.00/172.930 GiB memory 0.00/74.506 GiB object_store_memory Demands: (no resource demands)
クラスタが正常に作成されていることが確認できたのでヘッドノードでpythonスクリプト実行することで学習を開始します。
#: 学習の実行(100プロセスのactorを分散並列実行) python /code/main.py --logdir log/tfboard --cluster --num_actors 100 --num_iters 30000
6. モニタリング
kubectl get svc master-svcを実行して表示される <EXTERNAL-IP>:6006にブラウザアクセスすることでtensorboardを見ることができます。

また、 <EXTERNAL-IP>:8265からはクラスタのリソース使用状況などを確認できるrayの素敵機能ray-dashboardにアクセスできます。

5. クラスタの削除
クラスタ削除を忘れずに!
gcloud container clusters delete rl-cluster
まとめ
ほんとうは256並列でCartPoleやろうと思ってたのですがCPU割り当て増加リクエストが128 vCPUまでしか承認されなかったので100並列に押さえました。こんな簡単にHPCできるなんてすごい時代になったものだ。