深層強化学習において分散並列学習の有用性を示した重要な手法であるA3Cの解説と Tensorflow 2 での実装を行います。
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning
- A3C: Asynchronous Actor Critic
- Asynchronous (非同期) とは
- 分岐型 Actor-Critic ネットワーク
- A3Cのロス関数
- 実装
- 学習結果
- そしてA2Cへ
pythonの分散並列処理ライブラリのrayでa3cを実装し直しました(2020/12)
A3C: Asynchronous Actor Critic
A3Cとは、Vanilla Policy Gradient*1の学習を非同期分散並列で行う手法です。分散並列化されたエージェントが好き勝手にサンプル収集&学習行った結果(=NN重みの勾配)だけを中央のパラメータサーバに集めます。加えて、これ以前のActor-Critic系手法ではActorとCriticを別のネットワークとして実装するのが普通でしたが、A3CではActorとCriticを、入力に近い層を共有する双出力ネットワークとしてまとめるという工夫により学習の効率化を実現しています。これは画像入力系のタスク(ゲームとかね)においてとくに効果的なようです。
Vanilla Policy Gradient — Spinning Up documentation
Asynchronous (非同期) とは
A3Cの3つのAの先頭は Asynchronous(非同期)で、複数のAgentによる非同期並列学習を行うことに由来します。
具体的には並列化された各Agentが自律的にrollout (ゲームのプレイ) を実行 & 勾配計算を行い、その勾配情報だけをパラメータサーバ(global network)に送信します。各Agentは定期的に自分のネットワーク (local network) の重みをパラメータサーバ(global network) の重みと同期します。

並列分散Agentで学習を行うことは、単純にCPUリソースに応じて学習が高速化するという恩恵以上に、経験の自己相関を低減し学習を安定化する効果が期待できます。
経験の自己相関による学習の不安定化は強化学習が長く抱えてきた課題でした。この課題について、DQN (2013) は Experience Replay (経験再生) 機構 でバッファに蓄積した経験をランダムに取り出すことで経験の自己相関を低減することにより学習の安定化に成功しまさにエポックメイキングというにふさわしい手法となりました。しかし、経験再生は(基本的には)オフポリシー手法でしかとれないトリックです。
そこでオンポリシー手法であるA3Cではサンプルを集めるAgentを並列化することで自己相関を低減するという手段をとりました。この並列化アプローチは非常に効果的である上、他手法でも容易に転用可能なアイデアであるので、A3Cの発表後には強化学習分野には分散並列化ブームが到来することになりました。
ただし、Pythonは言語特性上、非同期並列処理を行うのがなかなか面倒であるという実装上の問題があります。また、各agentが自律的に学習するというアーキテクチャであるため Agentの数=GPUの数 のときに最大のパフォーマンスを発揮するという計算資源が豊富でない一般人/小規模ラボにはなかなか辛い手法です。
A3CとA2C
A3Cの後にA2Cという手法が発表されていますので、この2つの手法の違いについて解説しておきます。
上述した通り、Pythonの言語特性上の理由で並列Agentたちが自律的に学習し好き勝手なタイミングで共有ネットワークを更新する非同期 (Asynchronous ) 学習の実装は相当面倒です。
また、パフォーマンスを最大化しようと思うとAgentの数と同数のGPUが必要です。
しかしこれがもし同期処理でもよいなら、すなわち各Agentが中央指令室からアクションの指示を受けて一斉に1step進行する、中央指令室は各Agentから遷移先状態(next_state)の報告を受けて次のアクションを指示する、という処理で実装するならば推論 する (=GPUを使う) のは中央指令室だけなのでGPUが一つでOKです。 また、Pythonでよく使われるmultiprocessingライブラリなどで容易に実装可能です。このような非同期でないA3Cの実装をA2Cと呼びます。
A3Cが発表されたあとの検証研究により、A2Cの同期学習でもパフォーマンスが落ちないことがわかったので実装が楽なA2Cがよく使われるようになりました。
※A2Cの実装は別記事を参照ください horomary.hatenablog.com
分岐型 Actor-Critic ネットワーク
典型的なActor-Criticアーキテクチャでは、方策ネットワークと価値ネットワークを別に定義して、それぞれ別のロス関数(方策勾配ロス/価値ロス)でネットワークを更新します。
一方、A3CのActor-Criticでは一つのネットワークが方策と価値を出力する分岐型のネットワークを実装し、後述するトータルロスでネットワークを更新します。
Actor関数でもCritic関数でも、観測情報 から情報を抽出する役割を持つInputに近い層は似たような重みになると思われるため、このようなパラメータ共有型のActor-Criticは画像のように高度な表現抽出処理が必要な場合に効果的と思われます。
一方で、今回ターゲットにするCartPoleのように生の観測情報(角度、加速度など)が十分に系の状態を表現している場合にはA3C型のパラメータ共有Actor-Criticの恩恵が受けにくいと考えられることに留意ください。
A3Cのロス関数
上述の通り、A3Cでは一つのネットワークが方策と価値を出力する分岐型のネットワークを実装し、一つのロス関数でネットワークを更新します。
具体的にこのA3Cのロス(Total loss)はアドバンテージ方策勾配, Value loss, 方策エントロピー, の3項に分けて次式のように表せます。
Total loss アドバンテージ方策勾配
Value loss
方策エントロピー
※方策勾配と方策エントロピーは最大化したいので-1を掛けます。
※係数αとβはハイパーパラメータです
① アドバンテージ方策勾配項
アドバンテージ方策勾配項は、名前の通りアドバンテージ関数Aで評価する方策勾配です。
AはAdvantage項であり状態行動価値Q から価値のベースラインとも言える状態価値を差し引いたものと定義され、もっともシンプルには下式のように実装できます。
方策勾配の重みづけに状態行動価値
をそのまま使用するのではなく、価値のベースラインである
を引くことで分散が小さくなり学習の安定化が期待できます。
直感的にはアクションの価値(状態行動価値 Q)はしばしば現在の状態(tex:V(s_t))に大きく依存するので分散が小さくなる、と考えると理解しやすいでしょう。

アドバンテージ関数について上ではわかりやすさのために1step後までの即時報酬しか使用しないもっともシンプルな例を紹介しましたが、Advantageの実装にはいくつかのパターンがあります。
A3Cのbaselines実装では1-5step程度分までの即時報酬を使用するmulti-stepアドバンテージ(※名称合っているかわからない)を採用しているので今回はこの方法で実装します。これ以外ではGAE (Generalized Advantage Estimation)という手法がよく用いられます。
GAE: [1506.02438] High-Dimensional Continuous Control Using Generalized Advantage Estimation
② Value Loss 項
Valueloss 項は DQNとほぼ同じです。もっともシンプルには をターゲットとして学習します。
式から明らかなようにAdvantage関数とA3CにおけるValuelossは同じものになります。
ただし、アドバンテージ方策勾配項におけるAdvantageは定数(勾配を流さない)として扱うのに対して、ValueLoss項では は定数として扱うが
は勾配が流れるようしなければならないことに注意してください。具体的には適切に
tf.stop_gradientするのですが詳細は下記の実装を参照ください。
方策エントロピー項
たとえば、ある状態sの入力について出力であるアクションの採用確率が (a1, a2, a3, a4) = [0.25 0.25, 0.25, 0.25] のときと (a1, a2, a3, a4) = [0.85, 0.05, 0.05, 0.05] のときでは前者のほうが方策のエントロピーが大きい状態となります。
方策エントロピー項の追加は、方策関数の正則化効果が期待できます。
具体的には方策のエントロピーが大きくなることにボーナスを与えることで、方策関数の早すぎる収束による局所最適化を防ぎ学習を安定化します。
※エントロピー項の係数βは探索の度合いを調整するハイパーパラメータです。
実装
この実装はTensorflow blog に掲載されたのA3C実装 (tensorflow1系での実装) を参考にしています。
上述した通り、Pythonでプロセス非同期処理を実装するのはたいへん面倒なため、threadingモジュールを使いスレッド間での非同期処理で実装しています。
※threadingでは並列処理による高速化は望めません。
コード全文はGithubへ:
Asynchronousの実装
スレッド間非同期並列処理のコードがこちら。
各Agent(スレッド)はglobal_counterとglobal_ACNetを共有します。
グローバルActorCriticNetworkをbuild()することを忘れると学習が全く進まないことに注意。 tensorflow2.0はdefine by run なわけですが、A3Cではグローバルネットワークは自ら推論することが訓練中一度もないので明示的にbuildしないとdefineされないためです。
Actor Critic ネットワーク
Actor Critic Networkは状態を入力されるとValueとaction確率(softmaxする前なのでlogit)の2つを出力します。
アクションの決定はtensorflow_probabilityで行います。今回の例はアクションが離散値なので役に立ってませんが、連続値アクションをサンプリングするときにはコードがすっきりします。
Agentの挙動
A3CのAgentの動作はざっくりとは下記のような感じ
最大 N step分 ゲームをプレイ(
play_n_steps())しtrajectoryを取得。
もし途中でゲームオーバーになった場合はその時点で2へ。
N step 進んだらそこでゲーム中断し2へ1で得た最大Nステップ分のtrajectoryからロスを計算・勾配情報を取得
2.で得た勾配情報を共有ネットワーク(global network)に適用する。
ローカルネットワークとグローバルネットワークを同期(重みをコピー)する
1-4を繰り返す
ロスの計算
この実装では最大N step 先の即時報酬まで使用してAdvantageを計算(multi-step Advantage)するので、trajectoryの何番目のステップかによって先読みする長さが異なることに注意。

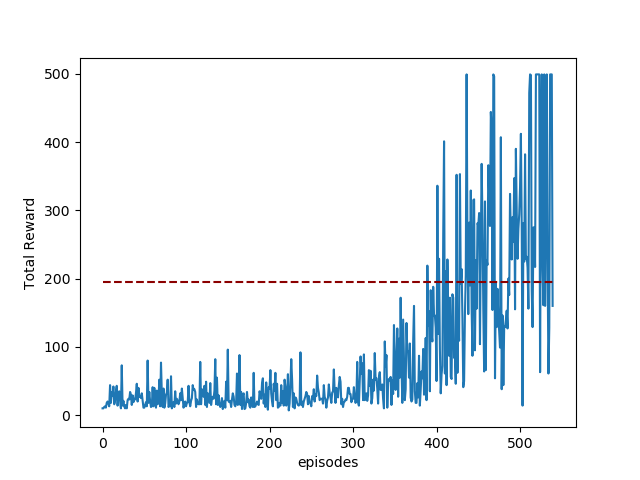
学習結果
最後の方はCartPole-v1環境の満点である500点を安定して取れるようになっています。