シンプルなようで厄介な強化学習アルゴリズム PPO (Proximal Policy Optimization) を実装レベルの細かいテクニックまで含めて解説します。
※TRPOの理解が前提です
[PPOシリーズ]
ハムスターでもわかるProximal Policy Optimization (PPO)①基本編 - どこから見てもメンダコ
ハムスターでもわかるProximal Policy Optimization (PPO)②TF2による実装 - どこから見てもメンダコ

はじめに
PPO (Proximal Policy Optimization, 2017) はシンプルにされた TRPO (Trust Region Optimization, 2015) として発表された手法です。
TRPOはアイデアも性能も素晴らしいのですが実装が複雑になりすぎる、ActorとCriticでパラメータ共有をするA3C 型のアーキテクチャが利用困難である、CNNやRNNで性能が悪いなどいくつかの課題がありました(TRPO著者の講義スライドより)。そこで、PPOではClipped Surrogate Objectiveという直感的にも実装的にもシンプルなアイデアでTRPOのコンセプトを実現できることを提案し、実際にMuJoCo環境でTRPOと同等以上のパフォーマンスを発揮することを示しました。
さらに同じ論文内で、A2CにPPOのアイデアを導入することでCNN+離散値アクションのAtari環境でも良いパフォーマンスを発揮することを示し、その実装の手軽さと性能の安定性から現在でも人気の強化学習手法となっています。
一方で、PPO(に限らず方策勾配学習全般)は実装レベルの細かいテクニック(たとえば報酬のスケーリングの有無、重みの初期化手法の選択など)によってパフォーマンスが大きく変わるので、コアコンセプトの影響の大きさが比較しにくいことが指摘されてきました。とくに近年のPPO検証論文([2005.12729] Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO, ICML2020)ではMuJoCo環境におけるPPOのパフォーマンス向上は主に実装上の細かいテクニック(code-level optimization)によって得られているものだと指摘しています。
というわけで、本記事ではそのような”実装上の細かいテクニック”まで含めてPPOを紹介します。
TRPO: KL制約付き最大化問題としての方策更新
PPOはシンプル化されたTRPOとして発表された手法ですので、まずはTRPOのコンセプトを紹介します。
方策勾配法は適切な更新サイズを決める困難さからしばしば大きく更新しすぎて方策ネットワークが破綻する(あるいは小さく更新しすぎて学習が全く進まない)という不安定さの課題を抱えています。この課題を”方策ネットワークの出力が更新前と更新後で変化しすぎないように更新サイズを毎回決める” ことによって解決したい、というのがTRPOのコアコンセプトです。
TRPOはこのコンセプトを毎回の方策ネットワークの更新をKL制約付き最大化問題として捉えることによって実現します。
すなわち、更新前方策の出力と更新後方策
の出力のKLダイバージェンスが一定値以下という制約の下で、代理目的関数 (Surrogate objective)
を最大化する
を計算します。これは方策パラメータθについての制約付き最大化問題であるのでラグランジュ乗数法で解くことができます。
なお、慣れ親しんだ方策勾配法の目的関数(が入ってるアレ)とは異なる代理目的関数 (Surrogate objective)
がどこから湧いてきたのかが気になります。この代理目的関数L(θ)は重点サンプリング (Importance Sampling)によって導出される”方策関数の更新に伴う期待報酬の改善″なのですが解説すると長くなるので詳細は過去記事を参照ください。
PPO:シンプル化されたTRPO
TRPOの欠点は上述したKL制約付き最大化をラグランジュ問題として真面目に解くために実装が死ぬほど煩雑になることです。具体的にはフレームワークが用意するAdamなどのOptimizerを使わずパラメータ更新処理を自力実装する必要があります。またパラメータ数についてのスケーラビリティの問題、および方策ネットワークにCNNが含まれる性能がイマイチという問題もあります。
そこで、PPO論文ではTRPOのコンセプトであるKL制約つきパラメータ更新を継承しつつ実装の煩雑さを改善するために下記の2つのアプローチを提案しました。なお、一般にPPOと言った場合は① Clipped Surrogate Objectiveでの実装を指すことに留意ください。
① Clipped Surrogate Objective
※すべての式と図はPPO論文 より
TRPOでも登場した代理目的関数(Surrogate Objective)の内部には、更新前方策の出力と更新後方策
の出力の変化の比が含まれます。この比を r(θ) と置きます。(rはimportance ratio のrでありrewardのrではないことに注意)

Clipped Surrogate Objectiveではr(θ)が(1-ε)以下、(1+ε)以上にならないようにクリッピングを行います(εはハイパーパラメータでありε=0.1-0.2くらいがよく採用されます)。このクリッピング処理は、Clipされた代理目的関数とClipされていない代理目的関数を比較し、小さいほう(=悪い方)を採用することで実現できます。

ネストしていて微妙に分かりにくいこのクリッピング処理を視覚的に示したのが下図です。実質的にはAdvantageの正負で場合分けして上限クリップするか下限クリップするか決めるという処理が行われます。
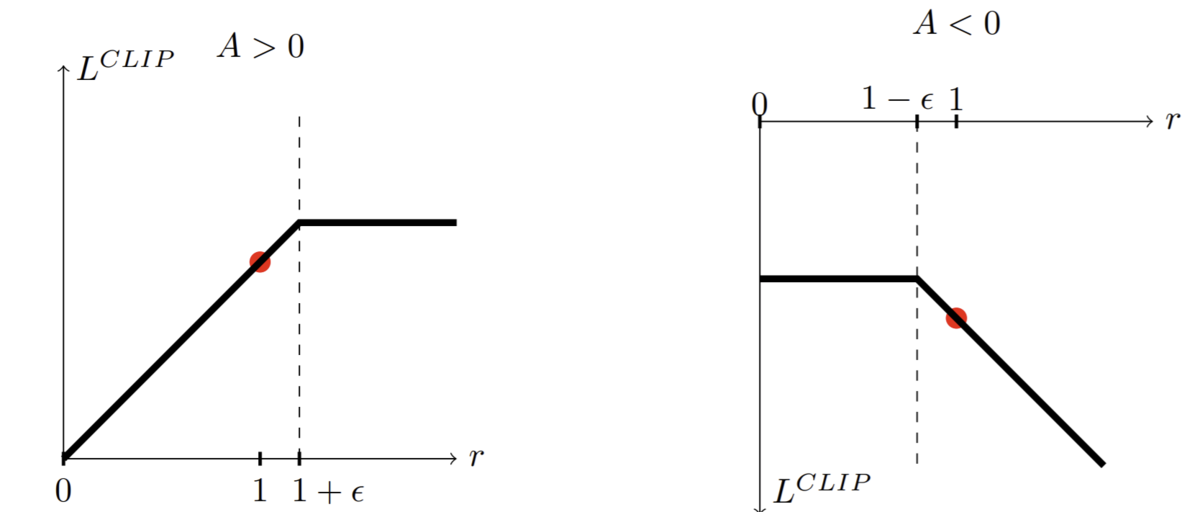
しかし、なぜ代理目的関数のClipping処理によってTRPOコンセプトである”方策関数の極端な更新を避ける”ことを達成できるのでしょうか?
直感的な理解のためにOptimizerの気持ちを考えてみます。
例えば与えられたミニバッチ内のあるの組が他の
の組に比べて極端に大きな報酬を獲得していたとき、すなわち
が極端に大きいとき、Optimizerは代理目的関数L(θ)を最大化するためにミニバッチ内の他の
の組を差し置いても、方策関数が
において
を出力する確率
をできるだけ高めるように極端な方策関数の更新を行ってしまいます。
しかし、Clipつき代理目的関数の場合は、更新後方策関数がにおいて
を出力する確率
を、更新前方策関数が
において
を出力する確率
の (1+ε)倍 以上に大きくしても上限Clipによって代理目的関数が改善しないので方策関数の極端な更新を回避することができます。
逆もまた同様で、ミニバッチ内のあるの組が他の
の組に比べて極端に小さな報酬を獲得していた時も下限のClippingが機能し方策関数の極端な更新を回避できます。
Clippingの効果を視覚的に示したのが下図です。更新前の方策関数を0、Clippingつき代理目的関数を用いて一回更新した方策関数を1として、他の目的関数を採用したときに値がどう変化するかを線形補間で示しています。
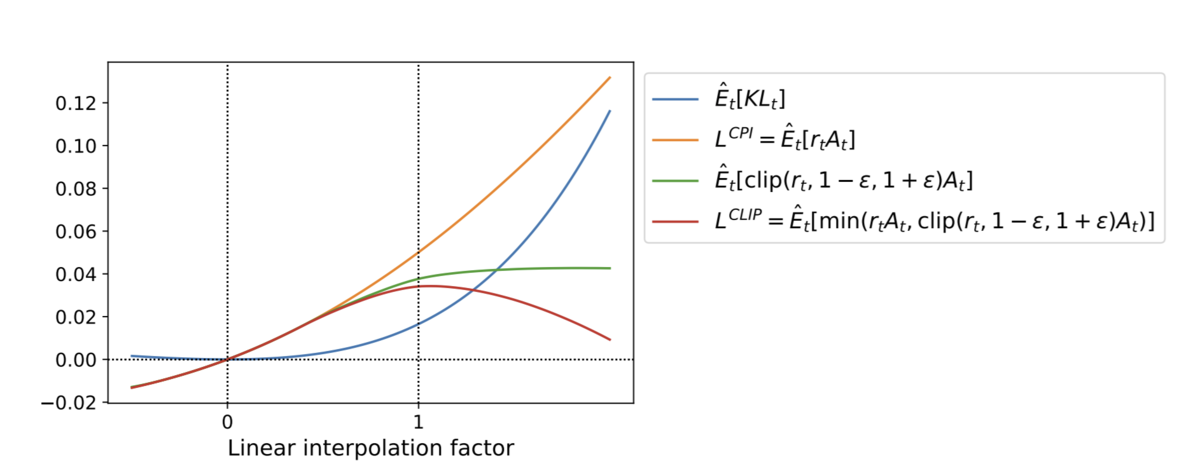
Clipされた代理目的関数(赤)の場合は、KLダイバージェンス(青)が0.02くらいのところで目的関数が最大になるのに対して、クリップがない場合(オレンジ)は大きく更新すればするほど目的関数の値が大きくなっていきます。さらに、代理目的関数をクリップするがクリップ前の代理目的関数との最小値比較をしない場合(緑)では、大きく更新しても目的関数の値は大きくならないものの、値が小さくもならないので方策関数の極端な更新を回避するモチベーションが弱いことがわかります。
② Adaptive KL ペナルティ
KL制約つき最大化問題を真面目に解かずに、目的関数にソフト制約(ペナルティ)として組み込もう、というのがこのアプローチです。ペナルティの大きさは適応的(adaptive)に変化させていくので Adaptive KL penalty となります。

シンプルですが論文内のパフォーマンスはパッとしなく、ベースライン扱いで提案されている感じがあります。 この実装例はtf_agents (agents/ppo_agent.py at master · tensorflow/agents · GitHub)などで見ることができます。
実装レベルの最適化
※式と図はA Case Study on PPO and TRPO より
方策勾配系の強化学習手法は、各手法のコアコンセプトではない”実装レベルの細かいテクニック”がパフォーマンスに大きく影響することが様々な論文で検証されています。また、この傾向はとくに連続値コントロール環境で顕著なようです。
論文① [1709.06560] Deep Reinforcement Learning that Matters
論文② [2006.05990] What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
論文③ [2005.12729] Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
とくに 論文③ ではPPOとTRPOのパフォーマンスを比較しており、この論文内では”パフォーマンスに大きな影響を与えうる実装レベルのトリック"として具体的に下記の示すものが検証されています。
① Value Clipping
ポリシーネットワークで行ったClippingと同じことを価値関数でも行います。なんとなく価値ネットワークの学習安定性が向上が期待できます。

しかし、論文③ のabration studyではvalue clippingはあっても無くてもあまり変わらない、という結果になっています。ただし、このトリックは価値関数の出力の正規化を行うトリックとのシナジーがある可能性もあるのではということが論文②の注11に記述されています。
個人的にはεを大きく設定すれば効果は薄れるしとりあえず実装しとけばいいんでは?という印象。
② Reward Scaling
論文③では重要なトリックとされており、割引報酬和の標準偏差でrewardを割ることでスケーリングします。※平均値を引く処理は行いません。
ただしrungning stats の性質上、報酬がスパースな場合は注意が必要です。具体的にはBipedalWalker-v3のようにほとんどのステップでの報酬は-1 から+1であるのに転倒時だけ-100というような極端な負報酬をとるような系では学習が不安定化します。
③ 方策ネットワークの初期化スキーム
A Case Study on PPO and TRPOでも、"What Matters In On-Policy Reinforcement Learning?"でも同様にポリシーネットワークの初期化スキームがパフォーマンスに大きな影響を与えいるとの指摘がされています。
前者ではkerasで言うとkernel_initializer="Orthogonal"がパフォーマンスを向上させると報告しています。後者では初期化スキームについてより詳細な調査を行っています。
④ 学習率のアニーリング
PPOではOptimizerにADAMを使用しますがこの学習率を徐々に下げていくとパフォーマンスが向上することが論文③で指摘されています。
その他
細かいトリックはまだまだあります。たとえば観測の正規化をするか、valueネットワーク出力の正規化をするか、アドバンテージをどのような手法で実装するかなど。実際のところこれらの効果は系によるところが大きいので一概には言えないというのが正直なところではないでしょうか。
そして実装へ
Bipedalwalker-v3をターゲットにtensorflow2でPPOを実装します。
References
[1707.06347] Proximal Policy Optimization Algorithms
[1502.05477] Trust Region Policy Optimization
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning
[1709.06560] Deep Reinforcement Learning that Matters
[2006.05990] What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
[2005.12729] Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO









