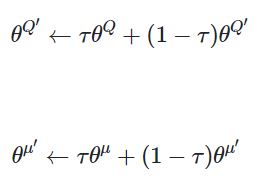D3.jsが役に立つケース
Pythonにおいてインタラクティブデータ可視化のほとんどのユースケースはbokehyやPlotly などのライブラリにより実現可能です。
しかしいくつかのユースケースではライブラリの提供する自由度の制限により本当に表現したいことが実現困難ということもあります。
たとえば以下のような複数グラフ間でのインタラクティブな表現はD3が簡単です。

D3.jsの利用はJupyter Notebookではやや煩雑な手順を踏む必要がありました。
(notebookではpy_d3ライブラリを使うことを推奨します)
しかしJupyterLabでは気軽に利用可能となっています。
ですので、"Bokehで実装するのは難しいから"という理由でデータ可視化を諦める必要はありません。
※ただしコーディングを始める前に、”その可視化は本当に必要か?”と疑うことは重要です。
D3ってなに?
D3.jsは、データに基づいてドキュメントを操作するためのJavaScriptライブラリです。D3は、HTML、SVG、およびCSSを使用してデータを実現するのに役立ちます。D3はWeb標準に重点を置いているため、独自のフレームワークに縛られることなく、最新のブラウザーの全機能を利用できます。強力な視覚化コンポーネントとDOM操作に対するデータ駆動型アプローチを組み合わせています。
D3.js - Data-Driven Documents
Installation
Jupytelabがないならインストールしましょう。
また、pythonからHTMLへデータを渡すためにテンプレートエンジンのjinjaを、
HTMLをJupyterlab上で表示するためにPanelを使用するのでこれらをインストールします。
conda install -c conda-forge jupyterlab
conda install -c pyviz panel
pip install jinja2
#: jupyterlabでのpanelの使用はlabextensionのインストールが必要
jupyter labextension install @pyviz/jupyterlab_pyviz
jupyterlabで可視化するための流れ
pandas.DataFrame.to_jsonで生成されるjson形式のテキストを、jinjaテンプレートエンジンを使用してあらかじめ準備したhtmlファイルに埋め込みます。
これをpanel.pane.HTMLに渡すことによりjupyterlabでD3を作図ライブラリのように使用することが可能になります。
panel.pane.HTMLはIPython.display.HTMLでもある程度代用可能です。同様にjinjaはstring.Templateでも代用可能ですが、jinjaの方が便利です。
今回のサンプルは以下のようなフォルダ構造で作成しました。
jupyter_d3.ipynbがJupyterlabで可視化を実行しているNotebookです。
working_dir
│ ─ correlogram.py
│ ─ jupyter_d3.ipynb
│ ─ simple_scatter.py
│
└─templates
│ ─ correlogram.html
└─ simple_scatter.html
シンプルな散布図の例
まずはシンプルな例から始めましょう。
jupyterlab上のコード
Cell 1 :
- PanelをLabで使用するためにpanel.extension()の実行
- jinjaで読み込むためのhtmlテンプレートの置き場所設定。
- ブラウザにD3.jsを読み込むための関数であるinit_d3を定義し、実行。
Cell 2 :
- サンプルデータセットを‘pd.DataFrame‘で用意

Cell 2 :
- simple_scatter.pyに定義されているSImpleScatterクラスをインスタンス化し、サンプルデータセットを渡す
- SImpleScatter.show()で散布図を表示

うまくD3.jsによる作図をPythonでラップできていることがわかると思います。
実際のD3へのデータの受け渡しはsimple_scatter.py内で行っています。
import panel as pn
class SimpleScatter:
def __init__(self, df, env):
self.data = df.to_json(orient="records")
self.template = env.get_template("simple_scatter.html")
def show(self, width=400, height=400, marker_size=6):
html = self.template.render({"DATASET": self.data,
"WIDTH": width,
"HEIGHT": height,
"MARKER_SIZE": marker_size})
pane_html = pn.pane.HTML(html)
return pane_html
SimpleScatterはデータフレームをJson形式文字列に変換し、これをsimple_scatter.htmlに埋め込み、panel.pane.HTMLオブジェクトとして返すだけのクラスです。このときマーカサイズなどの各種設定も一緒に埋め込みます。
D3.jsのコードはすべてsimple_scatter.htmlに記述されています。
<head>
<meta charset="UTF-8">
<style>
#chart{
margin: 4px;
box-shadow: 0px 0px 4px lightgray;
background-color: white;
border-radius: 10px;
}
.d3tip{
position: absolute;
text-align: center;
width: auto;
height: auto;
padding: 5px;
font-size: 10px;
background: white;
box-shadow: 0px 0px 10px lightgray;
visibility: hidden;
}
</style>
</head>
<body>
<div id="chart"></div>
<script src="https://d3js.org/d3.v5.js"></script>
<script>
var width = {{ WIDTH }};
var height= {{ HEIGHT }};
var margin = {top: 40, right: 40, bottom: 40, left: 40};
var RADIUS = {{ MARKER_SIZE }};
var chart_width = width - margin.left - margin.right;
var chart_height = height- margin.top - margin.bottom;
var fontsize = 10;
var fontfamily = "Meiryo UI";
var DATASET = {{ DATASET }}
var XNAME = "NOX"
var YNAME = "AGE"
var TITLE = "ScatterPlot"
var tooltip = d3.select("body").append("div").attr("class", "d3tip");
var svg = d3.select("#chart")
.append("svg")
.attr("width", width)
.attr("height", height)
.append("g")
.attr("transform", `translate(${margin.left}, ${margin.top})`);
svg.append("text")
.attr("x", (width/ 2) - margin.left)
.attr("y", 0 - (margin.top/4))
.attr("text-anchor", "middle")
.style("font-size", "16px")
.style("fill", "dimgray")
.style("font-weight", "bold")
.style("text-decoration", "underline")
.text(`${TITLE}`);
var x_scale = d3.scaleLinear()
.domain(getScaleMargin(
min=d3.min(DATASET.map((o)=>{return o[XNAME]})),
max=d3.max(DATASET.map((o)=>{return o[XNAME]})),
))
.range([0, chart_width]);
var y_scale = d3.scaleLinear()
.domain(getScaleMargin(
min=d3.min(DATASET.map((o)=>{return o[YNAME]})),
max=d3.max(DATASET.map((o)=>{return o[YNAME]})),
))
.range([0, chart_height]);
var x_axis = d3.axisBottom(x_scale);
var y_axis = d3.axisLeft(y_scale);
svg.append("g")
.attr("class", "xaxis")
.attr("transform", `translate(0, ${chart_height})`)
.call(x_axis)
.append("g")
.attr("class", "xlabel")
.append("text")
.attr("fill", "dimgrey")
.style("font-size", "16px")
.style('font-weight', 'bold')
.attr("x", chart_width)
.attr("y", -6)
.style("text-anchor", "end")
.text(`${XNAME}`);
svg.append("g")
.attr("class", "yaxis")
.call(y_axis)
.append("g")
.attr("class", "ylabel")
.append("text")
.attr("fill", "dimgrey")
.style("font-size", "16px")
.style('font-weight', 'bold')
.attr("transform", "rotate(-90)")
.attr("y", 6)
.attr("dy", ".71em")
.style("text-anchor", "end")
.text(`${YNAME}`);
svg.selectAll(".circle")
.data(DATASET)
.enter()
.append("circle")
.attr("class", "circle")
.attr("cx", (d) => {
return x_scale(d[XNAME]);
})
.attr("cy", (d) => {
return y_scale(d[YNAME]);
})
.attr("fill", "steelblue")
.attr("r", RADIUS)
.on("mouseover", function(d) {
tooltip
.style("visibility", "visible")
.html(`x: ${d[XNAME]}<br>y: ${d[YNAME]}`);
})
.on("mousemove", function(d) {
tooltip
.style("top", (d3.event.pageY - 20) + "px")
.style("left", (d3.event.pageX + 10) + "px");
})
.on("mouseout", function(d) {
tooltip.style("visibility", "hidden");
});
function getScaleMargin(min, max){
let mergin = (max - min) * 0.1;
return [min - mergin, max + mergin];
};
</script>
</body>
以上、簡単ですね。
Appendix: 複数グラフ間でのインタラクティブデータ可視化
冒頭の例もSImpleScatterと全く同様に実装しています。単純にHTMLに記述しているD3のコード量が長くなるだけです。
右側の相関図内の相関の大きさを表す円をクリックすると、左側の散布図が対応するデータにアップデートされるというグラフです。
このグラフは探索的データ解析において、1. 相関を確認する -> 2. 散布図を確認する という作業の繰り返しがあまりにもダルいことがモチベーションになり作成しました。
html以外はほぼ同じなので詳細な解説は省き、コードだけ掲載します。
※D3.js初心者が試行錯誤しながら作成したコードです。わりとクソコードであることに留意してご参考ください。
import pandas as pd
import panel as pn
class Correlogram:
def __init__(self, df, env):
self.df = df
self.template = env.get_template("correlogram.html")
def show(self, width=400, height=400, marker_size=6,
font_size=12, max_col=10):
df = self.df.iloc[:, :max_col]
data_json = df.to_json(orient="records")
corr_json = df.corr().to_json(orient="index")
html = self.template.render({"CORR_JSON": corr_json,
"DATA_JSON": data_json,
"WIDTH": width,
"HEIGHT": height,
"MARKER_SIZE": marker_size,
"FONTSIZE": font_size})
pane_html = pn.pane.HTML(html)
return pane_html
<head>
<meta charset="UTF-8">
<style>
.dashbord{
width: 100%;
display: flex;
flex-wrap: normal;
background-color: whitesmoke;
}
#chart1{
margin: 4px;
box-shadow: 0px 0px 4px lightgray;
background-color: white;
border-radius: 10px;
}
#chart2{
margin: 4px;
box-shadow: 0px 0px 4px lightgray;
background-color: white;
border-radius: 10px;
}
.xaxis path, .xaxis line{
display: none ;
}
.yaxis path, .yaxis line{
display: none ;
}
.tooltip {
position: absolute;
text-align: center;
width: auto;
height: auto;
padding: 5px;
font-size: 10px;
background: white;
box-shadow: 0px 0px 10px lightgray;
visibility: hidden;
}
</style>
</head>
<body>
<div class="dashbord">
<div id="chart1"></div>
<div id="chart2"></div>
</div>
<script src="https://d3js.org/d3.v5.js"></script>
<script>
var width = {{ WIDTH }};
var height = {{ HEIGHT }};
var margin = {top: 40, right: 40, bottom: 40, left: 40};
var fontsize = {{FONTSIZE}};
var fontfamily = "sans-serif";
var chart_width = width - margin.left - margin.right;
var chart_height = height - margin.top - margin.bottom;
var rawData = {{ CORR_JSON }}
var scatterData = {{ DATA_JSON }}
var indices = Object.keys(rawData)
var xname = indices[0]
var yname = indices[1]
var scatterR = {{ MARKER_SIZE }}
var upperData = [];
for (let i=0; i<indices.length; i++){
for (j=i+1; j<indices.length; j++){
let d = {};
d.x = indices[i];
d.y = indices[j];
d.corr = -1 * rawData[d.x][d.y];
upperData.push(d);
}
}
var lowerData= [];
for (let i=0; i<indices.length; i++){
for (j=i+1; j<indices.length; j++){
let d = {};
d.y = indices[i];
d.x = indices[j];
d.corr = -1 * rawData[d.x][d.y];
lowerData.push(d);
}
}
var middleData = [];
for (let i=0; i<indices.length; i++){
let d = {};
d.x = indices[i];
d.y = indices[i];
d.corr = rawData[d.x][d.y];
middleData.push(d);
}
var x_scale = d3.scaleBand()
.domain(indices)
.range([0, chart_width]);
var y_scale = d3.scaleBand()
.domain(indices)
.range([0, chart_height]);
var csize = d3.scaleSqrt()
.domain([0, 1])
.range([x_scale.bandwidth()/10, x_scale.bandwidth()/4]);
var ccolor = d3.scaleLinear()
.domain([-1, 0, 1])
.range(["#000080", "#fff", "#B22222"]);
var tooltip = d3.select("body").append("div").attr("class", "tooltip");
var svg = d3.select("#chart1")
.append("svg")
.attr("width", width)
.attr("height", height)
.append("g")
.attr("transform", `translate(${margin.left}, ${margin.top})`);
svg.append("text")
.attr("x", (width/ 2) - margin.left)
.attr("y", 0 - (margin.top/4))
.attr("text-anchor", "middle")
.style("font-size", "16px")
.style("fill", "dimgray")
.style("font-weight", "bold")
.style("text-decoration", "underline")
.text("Correlogram");
svg.selectAll(".fname")
.data(middleData)
.enter()
.append("text")
.attr("class", "fname")
.text((d) => {
if (d.x.length < 5){
return d.x;
}
else{
return d.x.slice(0, 7);
}
})
.attr("x", (d) => {
return x_scale(d.x) + x_scale.bandwidth()/2;
})
.attr("y", (d)=>{
return y_scale(d.y) + y_scale.bandwidth()/2;
})
.style("fill", "dimgrey")
.style("text-anchor", "middle")
.style("font-size", fontsize)
.style('font-weight', 'bold')
.on("mouseover", function(d) {
tooltip
.style("visibility", "visible")
.html(d.x);
})
.on("mousemove", function(d) {
tooltip
.style("top", (d3.event.pageY - 20) + "px")
.style("left", (d3.event.pageX + 10) + "px");
})
.on("mouseout", function(d) {
tooltip.style("visibility", "hidden");
});
svg.selectAll(".corCircle")
.data(lowerData)
.enter()
.append("circle")
.attr("class", "corCircle")
.attr("cx", (d) => {
return x_scale(d.x) + x_scale.bandwidth()/2;
})
.attr("cy", (d)=>{
return y_scale(d.y) + y_scale.bandwidth()/2;
})
.attr("fill", (d) => {
return ccolor(d.corr);
})
.attr("r", (d) => {
return csize(Math.abs(d.corr));
})
.on("mouseover", function(d){
d3.select(this)
.style("r", (d) =>{
return csize(Math.abs(d.corr)*3);
});
tooltip
.style("visibility", "visible")
.html(`x: ${d.x}<br> y:${d.y} <br> r: ${d.corr.toFixed(2)}`);
})
.on("mousemove", function(d) {
tooltip
.style("top", (d3.event.pageY - 20) + "px")
.style("left", (d3.event.pageX + 10) + "px");
})
.on("mouseout", function(d){
d3.select(this)
.style("r", (d) => {
return csize(Math.abs(d.corr));
});
tooltip.style("visibility", "hidden");
})
.on("click", updateScatter);
svg.selectAll(".corstr")
.data(upperData)
.enter()
.append("text")
.attr("class", "corstr")
.text((d) => {
return d.corr.toFixed(2);
})
.attr("x", (d) => {
return x_scale(d.x) + x_scale.bandwidth()/2;
})
.attr("y", (d)=>{
return y_scale(d.y) + y_scale.bandwidth()/2;
})
.style("fill", (d) => {
if (d.corr >= 0){
return "red";
} else {
return "royalblue";
}
})
.style("text-anchor", "middle")
.style("font-size", fontsize)
.style('font-weight', 'bold');
var svg2 = d3.select("#chart2")
.append("svg")
.attr("width", width)
.attr("height", height)
.append("g")
.attr("transform", `translate(${margin.left}, ${margin.top})`);
svg2.append("text")
.attr("x", (width/ 2) - margin.left)
.attr("y", 0 - (margin.top/4))
.attr("text-anchor", "middle")
.style("font-size", "16px")
.style("fill", "dimgray")
.style("font-weight", "bold")
.style("text-decoration", "underline")
.text("Scatter Plot");
svg2.append("clipPath")
.attr("id", "plot-area-scatter")
.append("rect")
.attr("x", 0)
.attr("y", 0)
.attr("width", chart_width)
.attr("height", chart_height)
var x_scale2 = d3.scaleLinear()
.domain(getScaleMergin(
min=d3.min(scatterData.map((o)=>{return o[xname]})),
max=d3.max(scatterData.map((o)=>{return o[xname]})),
))
.range([0, chart_width]);
var y_scale2 = d3.scaleLinear()
.domain(getScaleMergin(
min=d3.min(scatterData.map((o)=>{return o[yname]})),
max=d3.max(scatterData.map((o)=>{return o[yname]})),
))
.range([0, chart_height]);
var x_axis2 = d3.axisBottom(x_scale2);
var y_axis2 = d3.axisLeft(y_scale2);
svg2.append("g")
.attr("class", "xaxis2")
.attr("transform", `translate(0, ${chart_height})`)
.call(x_axis2)
.append("g")
.attr("class", "xlabel")
.append("text")
.attr("fill", "dimgrey")
.style("font-size", "16px")
.style('font-weight', 'bold')
.attr("x", chart_width)
.attr("y", -6)
.style("text-anchor", "end")
.text(`${xname}`);
svg2.append("g")
.attr("class", "yaxis2")
.call(y_axis2)
.append("g")
.attr("class", "ylabel")
.append("text")
.attr("fill", "dimgrey")
.style("font-size", "16px")
.style('font-weight', 'bold')
.attr("transform", "rotate(-90)")
.attr("y", 6)
.attr("dy", ".71em")
.style("text-anchor", "end")
.text(`${yname}`);
svg2.append("g")
.attr("id", "plot-area-scatter")
.attr("clip-path", "url(#plot-area-scatter)")
.selectAll(".points")
.data(scatterData)
.enter(j)
.append("circle")
.attr("class", "points")
.attr("cx", (d) => {
return x_scale2(d[xname]);
})
.attr("cy", (d) => {
return y_scale2(d[yname]);
})
.attr("fill", "steelblue")
.attr("r", scatterR);
function getScaleMergin(min, max){
let mergin = (max - min) * 0.15;
return [min - mergin, max + mergin];
};
function updateScatter(d){
xname = d.x;
yname = d.y;
x_scale2.domain(getScaleMergin(
min=d3.min(scatterData.map((o)=>{return o[xname]})),
max=d3.max(scatterData.map((o)=>{return o[xname]}))
));
y_scale2.domain(getScaleMergin(
min=d3.min(scatterData.map((o)=>{return o[yname]})),
max=d3.max(scatterData.map((o)=>{return o[yname]})))
);
svg2.selectAll(".xlabel")
.selectAll("text")
.text(`${xname}`);
svg2.selectAll(".ylabel")
.selectAll("text")
.text(`${yname}`);
svg2.selectAll("circle")
.transition()
.delay(function(d, i){return 1})
.attr("cx", (d) => {
return x_scale2(d[xname]);
})
.attr("cy", (d) => {
return y_scale2(d[yname]);
});
}
</script>
</body>