注意:
Alphafold2の手法解説です。使い方の説明ではありません
構造生物学ドメイン にはある程度の説明をつけます
アーキテクチャ 設計の意図については個人の考察であり、正しさに何ら保証がありませんAttentionとTransformerそのものについての説明は行いません
AlphaFold2論文など:
Highly accurate protein structure prediction with AlphaFold | Nature
Supplementary information(アルゴリズム詳細説明)
AlphaFold: a solution to a 50-year-old grand challenge in biology | DeepMind
DeepMindのCAPS14プレゼン
AlphaFold2とは
タンパク質は生命に不可欠であり、実質的にすべての機能をサポートしています。タンパク質はアミノ酸 の鎖で構成された大きな複雑な分子であり、タンパク質が何をするかはその独特の3D構造に大きく依存します。タンパク質がどのような形に折りたたまれるのかを解明することは「タンパク質の折り畳み問題」として知られており、過去50年間生物学の大きな課題となっていました。このたび、AIシステムAlphaFoldの最新バージョンは、隔年で開催されるタンパク質構造精密予測コンテスト(CASP)の主催者によってこの壮大な課題の解決策として認められました。この画期的な進歩は、AIが科学的発見に与える影響と、私たちの世界を説明し形作る最も基本的な分野のいくつかで進歩を劇的に加速する可能性を示しています。 (DeepMind Blog より)
DeepMind 社のタンパク質の立体構造予測アルゴリズム AlphaFoldの最新版である「AlphaFold2」 がCASP14(タンパク質立体構造予測コンペ)にてエポックメイキングな結果を残しました。とくに構造未知タンパク質の立体構造*1 を予測するという非常に難しいタスクでも、GDT(ざっくり正しい位置を予測できている原子の割合)が87.0という驚くべき精度 となっています。
GDT:ざっくり正しい位置を予測できている原子の割合
今後AlphaFold2は構造生物学的研究の必須ツールの一つとなっていくことが予想されますが、内部の仕組みがよくわからないツールを使うのはいくら精度が高いことが実証されていても心地悪いものです。そこで、本稿ではこの「AlphaFold2」のタンパク質立体構造予測の仕組みを論文に基づいて解説していきます。
タンパク質折り畳み問題について
まずは前提知識としてタンパク質折り畳み問題の概略を説明します。※生物系の方はスキップ推奨
タンパク質とはアミノ酸 が鎖状に連結した高分子化合物でありすべての生命に不可欠な物質です。タンパク質は筋肉を動かすモーターとして働いたり、赤血球として全身に酸素を運んだり、あるいは緑色に光ることさえできます。生命活動に必要なほとんどすべての機能発現がタンパク質によって担われているのです。
さまざまなタンパク質の立体構造
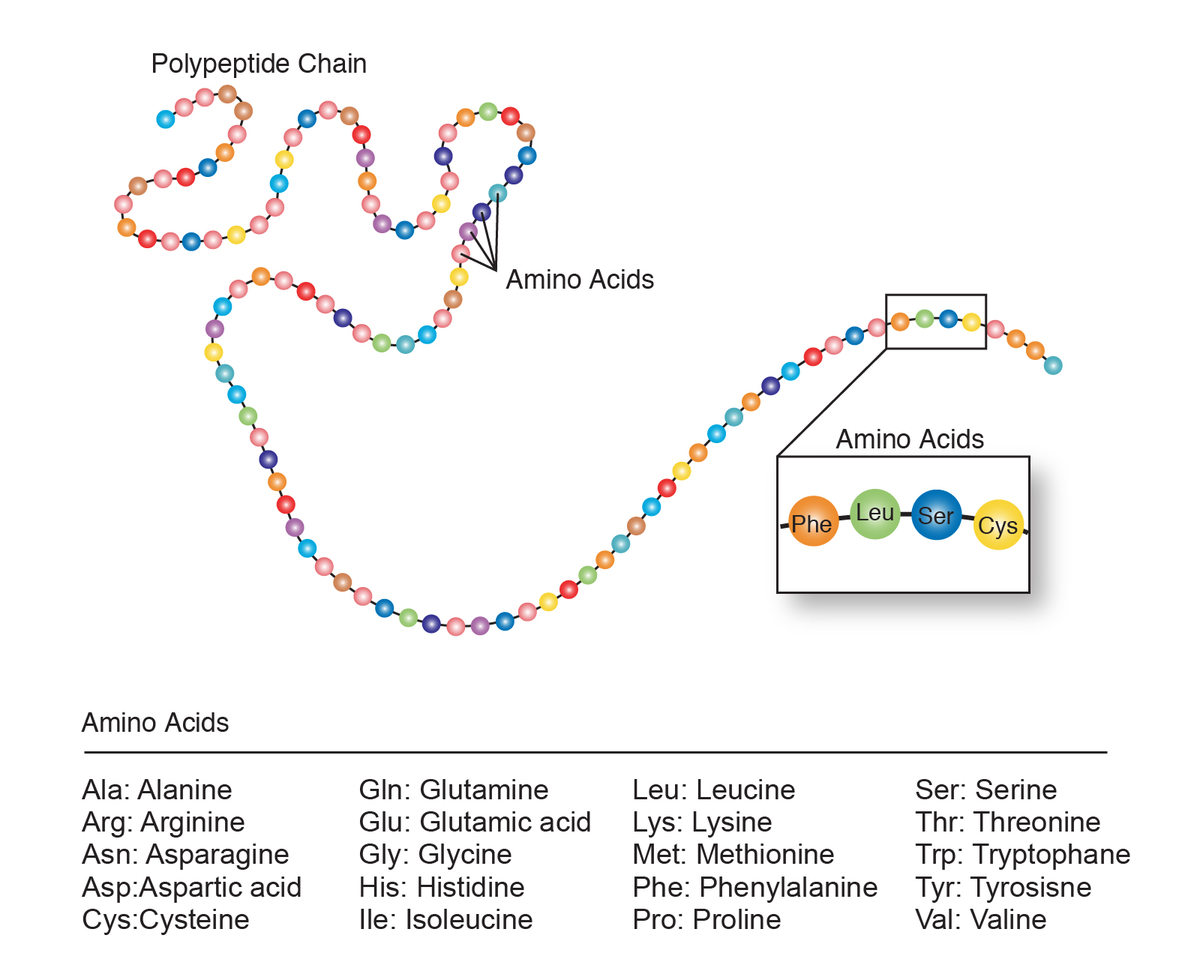
・タンパク質は20種類のアミノ酸 で構成される鎖
多様な機能を発現するタンパク質ですが、驚くべきことにすべてのタンパク質はたった20種類*2 のアミノ酸 が鎖状に連結することによって構築 されています。
https://www.genome.gov/genetics-glossary/Amino-Acids より
20種類のアミノ酸 のうちでも、アスパラギン酸 (Aspartic acid) やトリプトファン (Tryptophan)などは栄養ドリンクやサプリに表記されているのを目にしたことがあるのではないでしょうか。他にはグルタミン酸 (Glutamic acid)などはうまみ調味料の主成分としてお馴染みですね。
補足資料として下図ではタンパク質を原子レベルで描画した場合の構造 とタンパク質構造に関する用語 をまとめました。とくに、Cα(α炭素) の位置とねじれ角(torsion angle)Φ/Ψ/ω は知らないとAlphaFold2論文を読むのが困難なので覚えておきましょう。
タンパク質構造に関する基本用語集
・タンパク質は自発的に立体構造を形成する
ここまででタンパク質はアミノ酸 できた鎖(ペプチド) であることを説明しましたが、このアミノ酸 の鎖は適温の水*3 に入れることで自発的に*4 折りたたまれて立体構造を形成します。アミノ酸 配列では異なる構造に折りたたまれるためにタンパク質は多様な立体構造と多様な生物学的な機能を持つことができるのです。
DeepMind blog "Using AI for scientific discovery" より
補足情報:細胞内でのリアルな折り畳みについての解説田口 英樹 「タンパク質フォールディングの「理想」と「現実」:凝集形成とシャペロンの役割」日本生化学会
タンパク質折り畳みの駆動力となっているのはタンパク質内部の分子間相互作用や水との相互作用などの物理化学的な力 であるので、ごく小さいサイズのタンパク質であれば分子シミュレーション(分子動力学シミュレーション, Molecular Dynamics) によって折り畳み過程をシミュレートすることもできます。が、しかし分子シミュレーションで立体構造予測をするのは計算コストが重すぎるので現時点では あまり実用的ではありません。
VIDEO www.youtube.com
タンパク質立体構造の重要性
タンパク質の立体構造がわかることには様々な嬉しさがあるのですが、もっとも身近なのは創薬 への応用リレンザ やタミフル
応用物理学会 創薬を目指したSPring-8/SACLAの構造生物学研究 より
・ タンパク質立体構造解析の困難
問題はタンパク質の立体構造を実験的に解明するためには多大な労力が必要であることです。
もっともポピュラーなタンパク質立体構造の解析手法はX線 結晶構造解析法X線 で解析するのですが、そもそもタンパク質結晶の作製難易度が極めて高いという難点を抱えています。結晶成長に重力が悪さするから宇宙で結晶つくろうぜ という実験が実際に行われている、という事実からも苦労が推し量れます。
他には NMR(核磁気共鳴法) という分析機器を使ったり、最近ではCryo-電子顕微鏡 でタンパク質を直接見るというような方法も行われています。
データ駆動の立体構造予測
過去50年間にわたり構造生物学者 たちは大変な労力をかけて実験的なタンパク質立体構造解析を行ってきました。このような先人の血と汗とPEGの結晶として2021年現在では18万件以上のタンパク質の立体構造がPDB(Protein Data Bank) に登録されています。
これほどのデータが蓄積されているならば教師あり学習 の機運が高まるのは自然な流れです。
タンパク質の立体構造は
・ 似ているアミノ酸 配列であれば同じような立体構造となるアミノ酸 配列で同じ温度の水中なら同じ立体構造となる (と概ね見なせる)
という教師あり学習 に適した特性を持っているために、データ駆動での立体構造予測の試みが古くから行われていました。
ja.wikipedia.org
AlphaFold2ではこのような伝統的なタンパク質構造予測アプローチと深層学習をうまく融合 させたことにより、圧倒的な性能を実現しました。特筆すべきはAlphaFold2で使われている深層学習のテクニックは最先端のものですが、設計コンセプト自体は伝統的なバイオインフォマティクス の発想(ドメイン 知識)に基づいたもの であり、所謂「ディープでポン」の対極にあるアプローチであるという事実です。
つまりはAlphaFold2は、深層学習にドメイン 知識をどうやって注入すればよいのか?という視点で見ると大変示唆深く面白い手法と感じます。
AlphaFold2の概観
前提の説明が長くなりましたがここからが本題です。
4つのモジュール
論文Fig.1に注釈を追記
AlphaFold2は4つのモジュール *5 によって構成されています。
0. データ準備モジュール :アミノ酸 配列(input sequence)をクエリとし、バイオインフォマティクス のツールを用いてテンプレート立体構造の使用は任意であり無くても構いません 。
1. Embeddingモジュール :MSA representation の作成Pair representation の作成
入力値のEmbedding (Supl. Fig. 1)
2. Evoformerモジュール :
・MSAからの特徴抽出 ・Pair representationからの特徴抽出 ・MSAとPair representationでの情報交換
やりたいことはTransformerのEncoder部とほぼ同じですが、MSAの特性や空間グラフ(タンパク質)の物理的な制約を意識してちょっと変わったattentionの設計(axial attention, triangular attention) が行われています。
Evoformerモジュール (Fig.3)
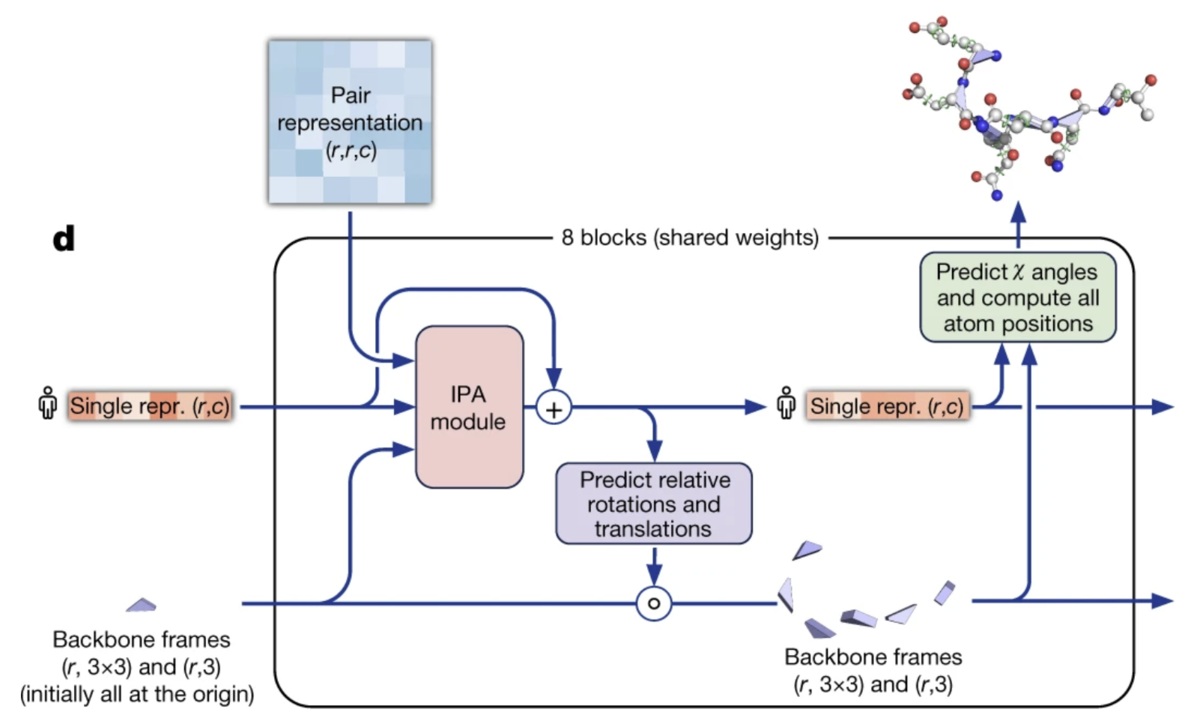
3. 構造モジュール :
・IPA (Invariant point attention)モジュールMSA表現, 残基ペア表現 そして現在の立体構造 の統合各残基への相対的な移動指示(=残基数分の(3,3)の回転行列と(x, y, z)の並進ベクトル) および側鎖のねじれ角(χ1-4) を予測
構造モジュール:shared weightsであることに注意(Fig. 3)
AF2のやってることをざっくり理解する
AlphaFold2とはタンパク質立体構造を入力としてよりrefineされたタンパク質立体構造を出力するネットワーク であると理解できます。
AF2の処理を極めて単純化 すると以下のようになります。
① すべての残基が原点に集合している構造で主鎖立体構造を初期化(ブラックホール 初期化構造モジュール に入力し、各残基への相対的な移動指示 を出力
AlphaFold2の出力とは各残基への相対的な移動(=並進と回転)指示
(実際には側鎖のねじれ角も予測しますが)おおまかな理解としてはAlphaFold2は各残基ごとへの相対的な移動指示(回転と並進)の出力を繰り返すことによってより良い立体構造を模索している イメージとなります。ここで、相対的な移動指示 というのは「残基番号127のグルタミン酸 は今の位置から10歩くらい右に動いて」 というようなニュアンスです。
ツールとしてのAlphaFold2ユーザーの視点では目的配列を入力すると一発で精確な立体構造が出力されるように見えますが、実際には分子力学シミュレーションによる構造最適化と同じように相対的な立体構造改善のiterationを重ねることで最終的な立体構造を得ています。構造モジュール(Structure module)はこのような立体構造改善iterationを実行する役割 を担っています。
また、AlphaFold2が立体構造改善の重要な手掛かりとしているのがMSA(Multiple sequence alignment) です。後述しますがこれはMSAにはアミノ酸 配列-タンパク質立体構造相関情報が豊富に含まれているためです。EvoformerモジュールはMSAからの情報抽出 を担っています。
0. データ準備
伝統的なバイオインフォマティクス 手法による入力データ準備を行うモジュール*6 です。立体構造を予測したいタンパク質のアミノ酸 配列 (input sequence) をクエリとしたDB検索によってMSA (Multiple sequence alignment) を作成 し、さらに自然言語 モデルBERTにおけるMasked Language Modelのアイデア を転用してMSAへのマスク・変異導入
MSA (Multiple sequence alignment) の作成
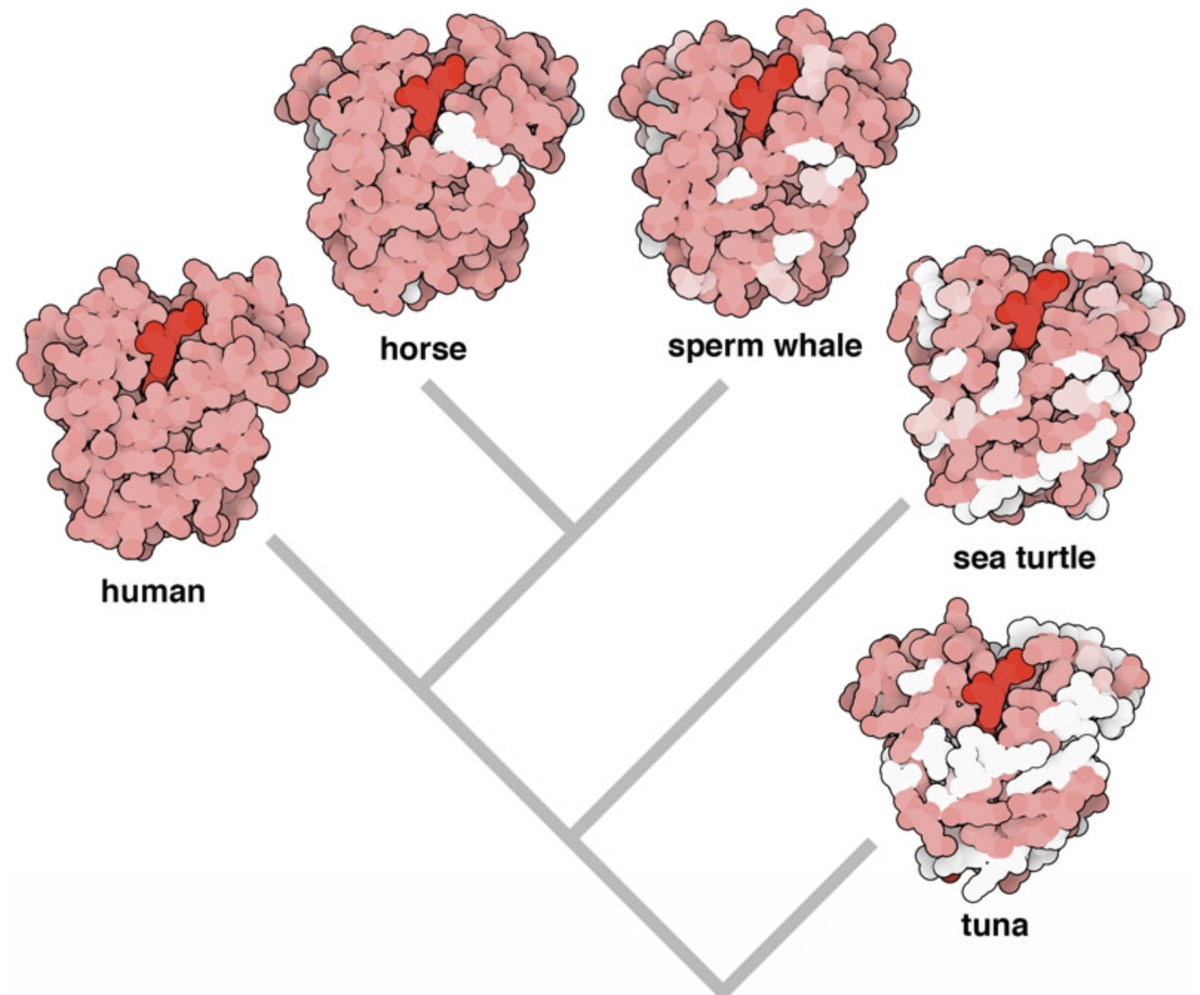
ヒトもウマもカメも共通の祖先から分化して進化したために、ヒトが持っているタンパク質の多くはウマもカメも持っています。ヒトとウマとカメの外形的な見た目は全く異なる一方で、実はタンパク質レベルでの見た目であればそれほど変わりません。この傾向は下図に示すミオグロビン(酸素を運搬するヘモグロビンの仲間)のような生命維持に不可欠なタンパクであるほど顕著となります。
PDB-101: Molecule of the Month: Globin Evolution よりミオグロビンタン パクの生物種間比較図アミノ酸 が使われている
ここで重要なのは、同種のタンパク質であれば生物種が変わっても全体的な立体構造はあまり変わらないが、アミノ酸 配列レベルではそれなりに差異が生じている ということです。ゆえに、あるタンパク質についてさまざまな生物種のアミノ酸 配列を並べたもの(=MSA)は、アミノ酸 配列-タンパク質立体構造相関を考えるうえで重要な手掛かり となります。
ただし、アミノ酸 配列は分子進化の過程で変異するだけでなく長くなったり短くなったりするために妥当なアミノ酸 配列の整列を得るのは容易なことではなく、バイオインフォマティクス 分野ではより妥当なMSAを作成するための手法研 究が古くから行われてきました。AlphaFold2が使用している HMMER は隠れマルコフモデル に基づくMSA作成手法の実装です。
Multiple sequence alignment - Wikipedia
より
なお、タンパク質立体構造解析に比べてタンパク質アミノ酸 配列の解析は格段にコストが低いために、立体構造は不明だけどもアミノ酸 配列ならわかっているというタンパク質が大量にあります。
MSA作成手順(概要):
入力配列をクエリとして配列の類似性スコアが一定値以上の最大5000配列でMSAを作成する
配列を雑に間引く(Supl. 1.2.6)
間引いてなお配列数が128以上の場合は、ランダムに128配列を選択する
配列数を128まで絞っているのは単純に計算コストの問題であり、深い意味はないことに留意ください。また、128配列に選ばれなかった配列についてそのまま捨ててしまうのはもったいないということで統計情報だけは利用するなどさまざまな工夫をしています(Supl. 1.2.7 MSA clustering)が、枝葉の処理なのでここでは詳細を割愛します。
MSAへのBERT風マスク導入
自然言語 モデルBERT では文章中の単語の15%程度をマスクトーク ンに置き換えて、この穴埋めクイズを事前学習(pre-training)として行うことにより言語への理解を獲得 します。(Masked Language Model)
AlphaFold2でもMSAに対してBERTと同様なマスク置き換えを行い、MSA穴埋めクイズを通してAF2ネットワークにMSAの読み方を理解させる ことを目指します。
Supl. 1.2.7 より
ただし、BERTとは異なりAF2では事前学習(MSA穴埋めクイズ)と目的タスク(立体構造予測)の訓練を分離せず、MSA穴埋め予測クイズのロス項と立体構造予測のロス項を足したものをトータルロスとしてまとめて学習します。(詳細は後述)。
テンプレート構造の検索(任意)
たとえばヒトのミオグロビンタン パクの立体構造を予測したいとします。ここで、もしヒトと十分に近縁であるサルのミオグロビンタン パクの立体構造が既知であるならば、サルのミオグロビンタン パクの立体構造をテンプレート(鋳型)としてヒトミオグロビンタン パクの立体構造を生成するだけで十分に品質の高い予測立体構造が得られます。
AlphaFold2においてもテンプレート構造情報を入力に含めることができますが、必須入力ではない上にablation study (論文 Fig. 4)より使わなくてもパフォーマンスがほぼ変わらないとされているので詳細説明は省略します。
1. Embeddingモジュール
このモジュールではスパースな入力値に対してEmbedding(活性化なし全結合層、つまり線形変換)を行うことでdenseなベクトルに変換します。さらに各入力データを統合し、MSA representation および Pair Representation を出力します。初見では複雑な処理に見えますが、必須のパス(任意パスは灰囲み)だけを見ればMSAに目的配列情報を付加する程度のごくシンプルな処理であることに気づきます。
Supl. Fig1 に注釈を追記。Rの意味はRecycling項を参照
入力データのOne-hot化
入力データはonehot化されています。自然言語処理 に慣れた人にはonehot化からのembeddingはお馴染みの定型処理ですが、そうでない人のために何をやってるかの図を置いときます。ここでアミノ酸 タイプ天然アミノ酸 20種+残基不明+欠損+マスクトーク ンの23タイプ です。
アミノ酸 配列のonehot表現
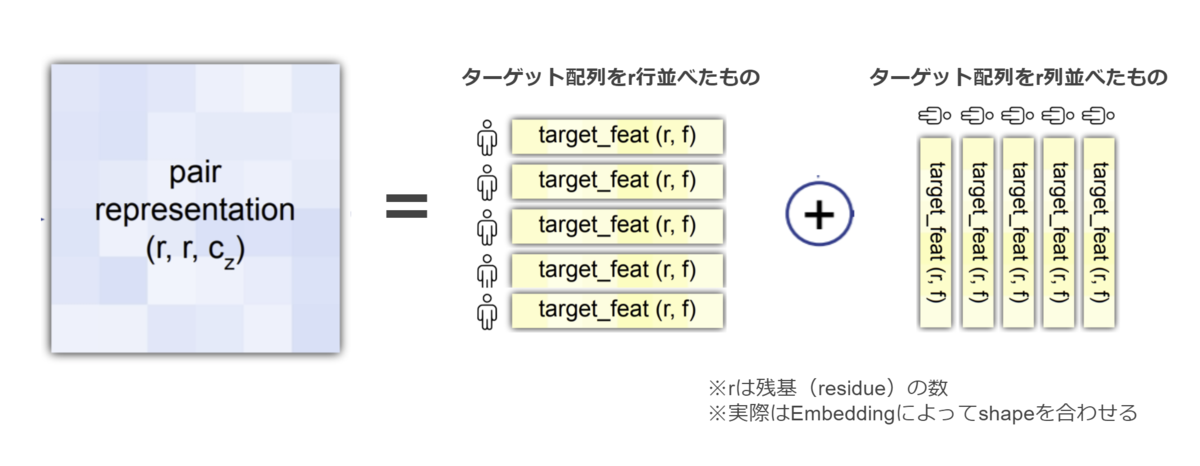
MSA Representation
MSA representaion は生のMSAに立体構造予測を行いたいアミノ酸 配列(ターゲット配列 )情報を紐づけたものと理解できます。また、直後にテンプレート立体構造のtorsion angleがconcatされることから側鎖レベルの詳細な立体構造情報を保持する役割も担っている と解釈できます。
MSA representaionは生MSAにターゲット配列情報が付与されたもの
Pair Representation(残基ペア表現)
Pair Representation(残基ペア表現)とは残基間の関係性(たとえば残基-残基タイプや残基間の空間的距離など)を表現することにより、主鎖レベルの大雑把な立体構造情報を保持する役割を担っていると解釈できます。 初期状態では残基-残基タイプ程度の情報しか持ちませんが、AF2ネットワークを進むことにより残基間関係の情報が書き加えられていきます。たとえば、もし立体構造テンプレートを使用している場合は直後にテンプレート立体構造における残基間距離情報が追記(加算)されます。
初期のPair representaionは残基タイプ-残基タイプ情報程度しか保持していない
Evoformerモジュールではself-attention機構によってMSA表現および残基ペア表現からの特徴量抽出 を行います。やりたいことはTransformerのEncoder部とほぼ同じ ですが、MSAおよび空間グラフとしてのタンパク質の物理的制約を意識してやや変わったattention設計を行っています。また、MSA表現と残基ペア表現で情報交換が行われていることも特徴的なアーキテクチャ です。
Evoformerモジュール (論文Fig. 3 に注釈を追記)
① axial-attentionによるMSA表現の特徴抽出
上図よりMSA表現からの特徴抽出パスには
MSA row-wise gated self-attention with pair bias
MSA column-wise gated self-attentio
Transition (ただの全結合層)
の3つのブロックが存在することがわかります。
A. MSA row-wise gated self-attention with pair bias:
Supl. Fig2 に注釈を追記
このブロックでは配列方向(row-wise)にaxial self-attention(軸方向注意) を適用することにより、配列内での情報交換を促進します。この(配列, row-wise)軸方向注意の仕組みは、ちょうど人間がMSAを配列方向に眺めて「このあたりはヘリックス*7 構造っぽい」とか「システイン が複数あるから分子内でスルフィド結合(S-S結合)を形成するかも」と考えつつMSAに注釈をつけていくようなプロセスを再現しています。
なお、このaxial attention(軸方向注意)はAF2論文での新規提案手法ではなく画像認識分野で提案された手法の転用となっています。
Google AI Blog: Axial-DeepLab: Long-Range Modeling in All Layers for Panoptic Segmentation
さてこのMSAについてのself-attentionですが、attention機構を見慣れた人であれば残基ペア表現(Pair representaion)をdot-product affinitiesにバイアスとして加算していることに強烈な違和感を覚えるのではないでしょうか。 安直には残基ペア表現をQuery, MSA表現をKey, Value としてattentionをしたくなります。しかし、残基ペア表現(Pair representaion)が保持している情報が残基-残基ペアの空間的関係性であることを思い起こせばバイアスとして加算することはごく自然な発想であることに気づきます。すなわち空間的に近い残基ペアについて大きなattention-weightsが割り当てられるようになるのです。
最後に目につくのはgating ですが、これはLSTMなどにおけるゲート機構と全く同じ役割を担っていると考えられます。すなわち不要な情報を削る”ゲート”の役割 です。シグモイド関数 で活性化されており素早く0→1を切り替えることができるために、効果的に情報の取捨選択を行えます。
B. MSA column-wise gated self-attention: 人間がMSAを残基位置方向に眺めて「この残基位置は生物種にわたって変異がほぼがないからきっと重要な残基なのだろう」とか「この残基位置はそれなりに変異あるけど疎水性アミノ酸 ばかりだなあ」とか考えつつMSAに注釈をつけていくようなプロセスを再現しています。
② 残基ペア表現(Pair representation) の特徴抽出
残基ペア表現(Pair representation)は残基間の空間的な位置関係情報を保持するように設計されているために、
残基ペア表現の特徴抽出ブロックもまた残基間の空間的な位置関係 に着目した設計となっています。
論文Fig. 3より
たとえば上図において残基i-k間の空間的距離と残基j-k間の空間的距離が決まったとすると、三角不等式より "残基i-j間の空間的距離 <= 残基i-k間の空間的距離 + 残基j-k間の空間的距離" でなければならないという制約が生じます。 言い換えると、残基i-j間のペア表現を更新するときには残基i-k間のペア表現および残基j-k間のペア表現と事前に情報交換を行う必要がある ということです。関係者への根回しは大事。
そこでEvoformerでは関係の深い残基ペア表現間での情報交換の促進を
Triangular multiplicative update
Triangular self-attention
の2つのブロックで実現しています。ただし、あくまで残基間の物理的な制約を意識して 設計されたブロックというだけであり、実際に物理的制約を満たすことは何ら保証されていないということには注意してください。
A. Triangular multiplicative update:
このブロックでは残基iとすべての残基間のペア表現(i行目)および残基jとすべての残基のペア表現(j行目)を使用して残基i-j間のペア表現を更新 します。論文Fig3では3残基の組み合わせごとにfor文で処理するような印象を受けますが、Supl. Fig6では行ごとにまとめた計算効率の良い等価処理を説明しています。また、更新前の残基i-j間のペア表現 がgating機構 を通して情報の取捨選択をコントロール していることがわかります。
論文Fig.3, Supl. Fig6 に注釈を追記
ちなみにこのブロックはTriangular self-attentionの軽量versionとして設計されたものの、Triangular self-attentionと併用することによって精度向上することがわかったという開発秘話が論文Supl.に記述されています。
B. Triangular self-attention:
論文Fig.3とSupl. Fig.7 より
3. 構造モジュール (Structure module)
構造モジュール (Structure module)では、Evoformerによって特徴抽出されたMSA表現と残基ペア表現 と現在の主鎖立体構造 を入力として、各残基への「追加」の回転・並進指示 および 各残基のねじれ角 を出力します。※ i: iteration, r: 残基番号
論文Fig3 に注釈を追記
ここで、"現在の主鎖立体構造" とは、(x, y, z)で表現されるようなリアルな座標ではなく、各残基についての原点からの回転・並進操作 T=(R, t)で表現される ことに注意してください。回転・並進操作Tは各残基のCα(主鎖の中心炭素)に対して適用されます。
初めて構造モジュールに到達した場合は、"現在の立体構造"としてすべての残基が原点に集合する並進・回転操作 として与えられます。なお、この構造初期化スキームは論文中でブラックホール 初期化*8 と呼称されています。
IPA (Invariant Point Attention)モジュール構造モジュールではまずIPA モジュールによって、MSA表現と残基ペア表現、そして現在の主鎖立体構造 が統合されます。
Supplementary Figure 8 に注釈を追記
IPA モジュールの上半分についてはEvoformerのMSA row-wise gated self-attention with pair biasとほぼ同じことをやってるだけなので説明を省省略します。
IPA モジュールの下半分では現在の残基間距離情報 を取得する処理を行っています。このために残基数×p点の座標セットを生成し、現在の主鎖構造を表現している回転・並進操作Tを適用したうえで座標セット間の距離を算出しています。
squared distance affinitiesの算出
Tを適用する前の座標セットに固定点を使うのではなくネットワークに動的生成させている意義はよくわかりません。残基タイプを考慮してネットワークがいい感じに座標セットを生成してくれる、たとえばアスパラギン酸 のような細長い残基であれば細長い座標セットになるような効果があるのかもしれません。
座標点数pについて、query, keyについてはp=4座標点を生成しています。これは3点以下の座標点では回転操作の効果が薄れるためでしょう。value についてはp=8座標点と多めに生成しており、より詳細な側鎖構造を意識している気がします。
・ Invariant(不変性)とは?
Invariant Point Attentionの「Invariant」とは、IPA モジュールの出力が主鎖構造のグローバルな回転・並進に依存しないよということを示しています。残基間の相対距離情報のみを利用しているのでグローバルな回転・並進操作に出力が依存しないのは直感的にも明らかです。※証明はSupl.1.8.2
(主鎖のグローバルな回転・並進操作: Pymolなどの3D分子Viewerで対象分子をグルグル回す操作と同様)
Predict relative rotations and translations(主鎖構造の更新)
IPA モジュールの出力するMSA表現は現在の立体構造情報を含むすべての情報を統合した最終MSA表現 です。このブロックでは最終MSA表現から相対的な回転・並進指示を予測します。
とはいえやってることは全結合層で残基数分の回転行列と並進ベクトルを出力するだけです。ただし、回転行列(3×3)は直接予測するのではなくquaternion*9 の予測を回転行列に変換します。quaternion知らなくともこれを使うと予測すべきパラメータが減って嬉しいくらいの理解でOK。
構造を改善できるような「相対的」な回転・並進指示の予測
出力されるのは「相対的」な回転・並進操作Tなので、現在のTに出力されたTを適用することで現在のTを更新します。
Algorithm 20 Structure module より
各残基のねじれ角予測
Structureモジュールに突入する直前のMSA表現 とIPA の出力した最終MSA表現 から各残基の側鎖レベルの構造=ねじれ角 します。
ω, Φ, Ψは主鎖のねじれ角(二面角)であり、χ1-4は側鎖のねじれ角です。たとえばグリシン などは側鎖をもたないアミノ酸 なのでχ1-4を利用しませんが深層学習の都合上で予測だけは行います。
ω, Φ, Ψは主鎖のねじれ角
Algorithm 20 Structure module より
最終MSA表現だけでなく、s_init = Structureモジュールに突入する直前のMSA表現 が併用されているのは、側鎖構造は主鎖構造に依存するので構造修正の手戻りが多いためでしょう。側鎖構造のバックアップを保持しているとも解釈できます。
なお、角度予測なので安直には[0, 2π]の範囲のスカラ値を予測したくなりますが、そうではなく2次元ベクトルを予測して回転行列に変換するほうが良いとのことです*10 。
立体構造の出力
ここまでで主鎖構造(各残基の位置) と詳細構造(各残基のねじれ角) が決まったので一意的に立体構造を出力できます。しかしこれは暫定的な中間出力構造です。Structure moduleは8回繰り返すことで1サイクルとなっていますので、改善された主鎖立体構造と最終MSA出力を次ブロックの入力として同じ作業を繰り返しましょう。
最終的に出力された立体構造については軽量な分子シミュレーション(AMBER分子力場を使用した構造緩和)を行い、物理化学的に無理な構造を解消します。どの程度の無理があったかはfine-tuning時のみロス関数に使用します(後述)。
ロス関数
AF2のロス関数は複数種類のロス関数の重みづけ和をとったものとなっています。また、初期トレーニン グ時と自己蒸留データセット を用いたfine-tuning時(後述)ではロスの項が異なる(増える)ことに注意してください。これは物理化学的な無理(Lviol)のような細かい構造変化にセンシティブに反応する項を初期から考慮していると学習が不安定化する ためであると考えられます。
AlphaFold2のロス関数
Lfape: FAPEスコア に基づいたロス項。FAPEはRMSD(RMSD - Protein Data Bank Japan )スコアと似たような意味合いだが回転・並進ベクトルに基づくためキラリティを考慮しやすい。また、構造ズレが大きすぎる場合はClippingされる*11 。
Laux:
Ldist:
Lmsa:
BERT風のマスクが適用されたMSAの穴埋めクイズを通じてAF2ネットワークにMSAの読み方を理解してもらうためのロス項 。BERTのpre-trainingを同じ役割が期待されているはず。係数が大きいので実質的に事前学習(pre-training)っぽくなっているのでは。
Lconf: pLDDT の予測ロス。※後述
Lexp_resolved:
Lviol:
「予測の信頼性」の予測:pLDDTスコア
AlphaFold2では「予測の信頼性(正確さ)」を予測する ことを目指します。
より具体的には最終予測立体構造と教師立体構造間の残基ごとに算出 されるIDDT-Cαスコア を予測し、その予測誤差をネットワークのロス項に含めます(Lconf)。このIDDT-Cαスコアの予測値についてpLDDT と呼称します。
なおIDDT-Cαスコアとは2つのタンパク質立体構造のズレを妥当に算出するために設計されたスコアのようです。私は改造されたRMSD(RMSD - Protein Data Bank Japan )スコア程度の認識しかできていません。
pLDDTの定義から明らかなようにこのスコアに物理的な意味はありません 。が、pLDDTは立体構造が既知の類似配列が乏しいような配列を予測する場合にはスコアが下がると思われますので予測信頼性の予測という表記通りの視点では一定の意味がありそうです。ただし、立体構造既知の類似配列に乏しい ∝ 定まった構造を取りにくいので立体構造が解かれてない ∝ 物理化学的に不安定、 のような疑似相関が見出される可能性は十分にあるかと思います。
pLDDTは後述する自己蒸留 における、立体構造が既知の類似配列が乏しい配列についての予測立体構造を除外するような用途であれば存分にworkすることが期待できます。
更なる精度向上のためのトリック
Recycling
48のEvoformerブロックと8のStructureブロックを超えたあなたの手元には、十分に特徴抽出されたMSA表現 とPair representaion 、そしてすべての残基が原点に集合した初期構造と比較すればはるかに改善された主鎖立体構造 を持っています。
ではこの3つを新たな入力として強くてニューゲーム しましょう。再開始はEmbeddingモジュールの"R"と書いてある位置です。
"R is for Recycling" (Supl. Fig1 に注釈を追記)
論文Fig.4ではこのRecyclingによって構造精度が徐々に改善するタンパク(緑 T1064*12 )があることが示されています。※48ブロックで1cycle
論文Fig.4
自己蒸留データセット によるFine-tuning
実験的に解かれたタンパク質立体構造データセット (PDB データセット )よるトレーニン グをある程度終えた後は、データセット を水増し してfine-tuningを行います。
すなわち配列だけはわかっているタンパク質の立体構造を予測し、予測信頼性スコアが高い立体構造をデータセット に合流させることで教師立体構造データセット の大幅な増強(水増し)を実現 します。
このようなラベルなしデータに予測ラベリング(疑似ラベルづけ)を行い、データセット を増強することで精度向上させるという手法は、画像分類タスクで提案された Noisy-student の手法を踏襲したものとなっています。Noisy-student は有名かつ汎用性が高い手法であるのでweb上に解説記事が多く存在するため、詳細説明は割愛します。
arxiv.org
なお、予測構造のフィルターとなっている信頼性スコアには上述のpLDDTではなく残基間距離予測に基づいた信頼性スコアを使用しているのですが、これは「その時点でpLDDTが開発されてなかっただけであり、もしplDDT使ってたとしても同じような結果になると思うよ」、という記述があります。
まとめ
AlphaFold2は構造生物学のドメイン 知識に基づいたコンセプトをディープラーニング で超人化することに成功した手法と言えます。ドメイン の伝統的な発想を高度な深層学習エンジニアリング力で超人化するというDeepMind のアプローチは機械式時計のような精密工芸品を眺めている気持ちになります。こういうドメイン 知識を活用するアプローチはAlphaZeroでも成功していますしDeepMind の勝ちパターンになってますね。
horomary.hatenablog.com
本記事の記述に間違いを見つけたらコメントにて指摘をお願い致します。
補足情報
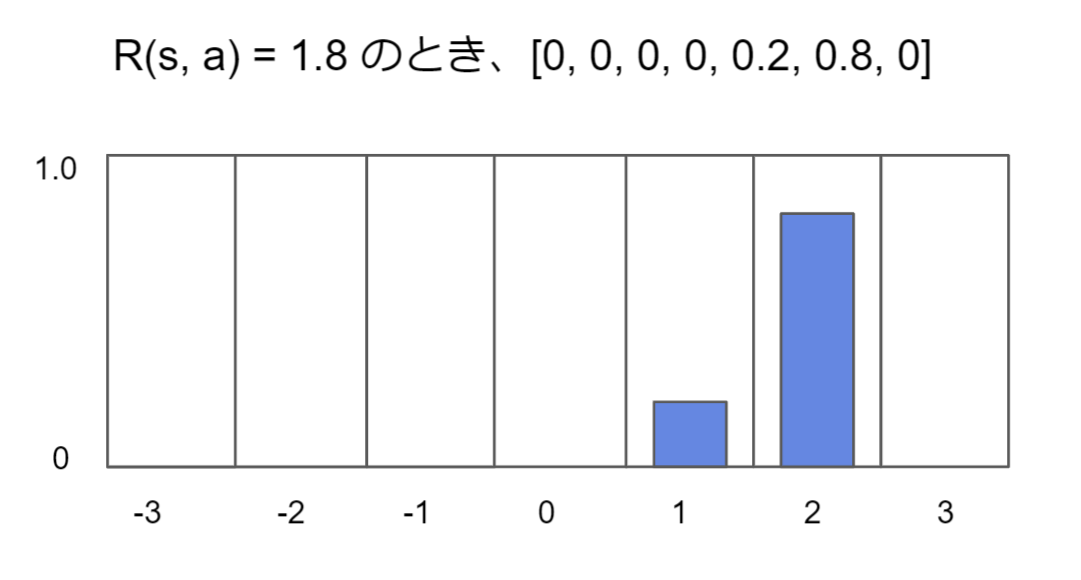
数値のカテゴリ表現
AF2では残基間距離のように数値表現が必要な値は基本的にカテゴリ表現にエンコード します。
本ブログ別記事の転用ですが、下図を見れば数値をカテゴリ表現するという処理の意味がつかめるかと思います。
数値をカテゴリ表現にすることによりエントロピー が使えて学習が安定する
このトリックはMuZero(AlphaZeroの後継手法)でも多用されています。
MuZeroの実装解説(for Breaktout) - どこから見てもメンダコ